asmlinkage long sys_gettimeofday(struct timeval *tv, struct timezone __user *tz)
UL#define ULONG_MAX (~0UL)static inline void prefetch(const void *x){ __asm__ __volatile__ ("dcbt 0,%0" : : "r" (x));}typedef struct {...volatile unsigned int lock;...} spinlock_t#include #include #include #include int main(int argc, char *argv[]){int fd;int pid; pid = fork();if(pid == 0) { execle("/bin/ls", NULL);exit(2); }if(waitpid(pid) <0 )printf("wait error\n"); pid = fork();if(pid == 0) { fd = open("Chapter_2.txt",O_RDONLY); close(fd); }if(waitpid(pid)<0)printf("wait error\n");exit(0);}creat_process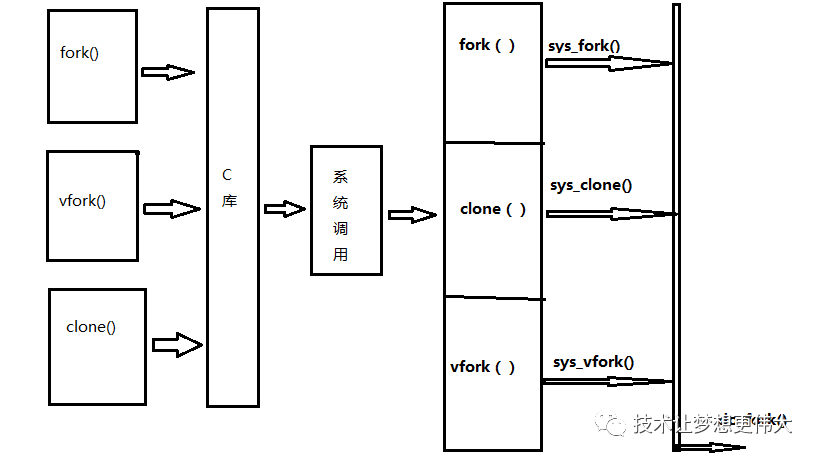
| fork() | vfork() | clone | |
| SIGCHLD | X | X | |
| CLONE_VFORK | X | ||
| CLONE_VM | X |
int do_fork(unsigned long clone_flags,unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size){ int retval; struct task_struct *p; struct completion vfork; retval = -EPERM ;if ( clone_flags & CLONE_PID ) {if ( current->pid )goto fork_out; } reval = -ENOMEM ; p = alloc_task_struct(); // 分配内存建立新进程的 task_struct 结构if ( !p )goto fork_out; *p = *current ; //将当前进程的 task_struct 结构的内容复制给新进程的 PCB结构 retval = -EAGAIN;//下面代码对父、子进程 task_struct 结构中不同值的数据成员进行赋值if ( atomic_read ( &p->user->processes ) >= p->rlim[RLIMIT_NPROC].rlim_cur && !capable( CAP_SYS_ADMIN ) && !capable( CAP_SYS_RESOURCE ))goto bad_fork_free; atomic_inc ( &p->user->__count); //count 计数器加 1 atomic_inc ( &p->user->processes); //进程数加 1if ( nr_threads >= max_threads )goto bad_fork_cleanup_count ; get_exec_domain( p->exec_domain );if ( p->binfmt && p->binfmt->module ) __MOD_INC_USE_COUNT( p->binfmt->module ); //可执行文件 binfmt 结构共享计数 + 1 p->did_exec = 0 ; //进程未执行 p->swappable = 0 ; //进程不可换出 p->state = TASK_UNINTERRUPTIBLE ; //置进程状态 copy_flags( clone_flags,p ); //拷贝进程标志位 p->pid = get_pid( clone_flags ); //为新进程分配进程标志号 p->run_list.next = NULL ; p->run_list.prev = NULL ; p->run_list.cptr = NULL ; init_waitqueue_head( &p->wait_childexit ); //初始化 wait_childexit 队列 p->vfork_done = NULL ;if ( clone_flags & CLONE_VFORK ) { p->vfork_done = &vfork ; init_completion(&vfork) ; } spin_lock_init( &p->alloc_lock ); p->sigpending = 0 ; init_sigpending( &p->pending ); p->it_real_value = p->it_virt_value = p->it_prof_value = 0 ; //初始化时间数据成员 p->it_real_incr = p->it_virt_incr = p->it_prof_incr = 0 ; //初始化定时器结构 init_timer( &p->real_timer ); p->real_timer.data = (unsigned long)p; p->leader = 0 ; p->tty_old_pgrp = 0 ; p->times.tms_utime = p->times.tms_stime = 0 ; //初始化进程的各种运行时间 p->times.tms_cutime = p->times.tms_cstime = 0 ;#ifdef CONFIG_SMP //初始化对称处理器成员{ int i; p->cpus_runnable = ~0UL; p->processor = current->processor ;for( i = 0 ; i < smp_num_cpus ; i++ ) p->per_cpu_utime[ i ] = p->per_cpu_stime[ i ] = 0; spin_lock_init ( &p->sigmask_lock );}#endif p->lock_depth = -1 ; // 注意:这里 -1 代表 no ,表示在上下文切换时,内核不上锁 p->start_time = jiffies ; // 设置进程的起始时间 INIT_LIST_HEAD ( &p->local_pages ); retval = -ENOMEM ;if ( copy_files ( clone_flags , p )) //拷贝父进程的 files 指针,共享父进程已打开的文件goto bad_fork_cleanup ;if ( copy_fs ( clone_flags , p )) //拷贝父进程的 fs 指针,共享父进程文件系统goto bad_fork_cleanup_files ;if ( copy_sighand ( clone_flags , p )) //子进程共享父进程的信号处理函数指针goto bad_fork_cleanup_fs ;if ( copy_mm ( clone_flags , p ))goto bad_fork_cleanup_mm ; //拷贝父进程的 mm 信息,共享存储管理信息 retval = copy_thread( 0 , clone_flags , stack_start, stack_size , p regs );//初始化 TSS、LDT以及GDT项if ( retval )goto bad_fork_cleanup_mm ; p->semundo = NULL ; //初始化信号量成员 p->prent_exec_id = p-self_exec_id ; p->swappable = 1 ; //进程占用的内存页面可换出 p->exit_signal = clone_flag & CSIGNAL ; p->pdeatch_signal = 0 ; //注意:这里是父进程消亡后发送的信号 p->counter = (current->counter + 1) >> 1 ;//进程动态优先级,这里设置成父进程的一半,应注意的是,这里是采用位操作来实现的。 current->counter >> =1;if ( !current->counter ) current->need_resched = 1 ; //置位重新调度标记,实际上从这个地方开始,分裂成了父子两个进程。 retval = p->pid ; p->tpid = retval ; INIT_LIST_HEAD( &p->thread_group ); write_lock_irq( &tasklist_lock ); p->p_opptr = current->p_opptr ; p->p_pptr = current->p_pptr ;if ( !( clone_flags & (CLONE_PARENT | CLONE_THREAD ))) { p->opptr = current ;if ( !(p->ptrace & PT_PTRACED) ) p->p_pptr = current ; }if ( clone_flags & CLONE_THREAD ){ p->tpid = current->tpid ; list_add ( &p->thread_group,¤t->thread_group ); } SET_LINKS(p); hash_pid(p); nr_threads++; write_unlock_irq( &tasklist_lock );if ( p->ptrace & PT_PTRACED ) send_sig( SIGSTOP , p ,1 ); wake_up_process(p); //把新进程加入运行队列,并启动调度程序重新调度,使新进程获得运行机会 ++total_forks ;if ( clone_flags & CLONE_VFRK ) wait_for_completion(&vfork);//以下是出错处理部分 fork_out:return retval; bad_fork_cleanup_mm: exit_mm(p); bad_fork_cleanup_sighand: exit_sighand(p); bad_fork_cleanup_fs: exit_fs(p); bad_fork_cleanup_files: exit_files(p); bad_fork_cleanup: put_exec_domain( p->exec_domain );if ( p->binfmt && p->binfmt->module ) __MOD_DEC_USE_COUNT( p->binfmt->module ); bad_fork_cleanup_count: atomic_dec( &p->user->processes ); free_uid ( p->user ); bad_fork_free: free_task_struct(p);goto fork_out;}fork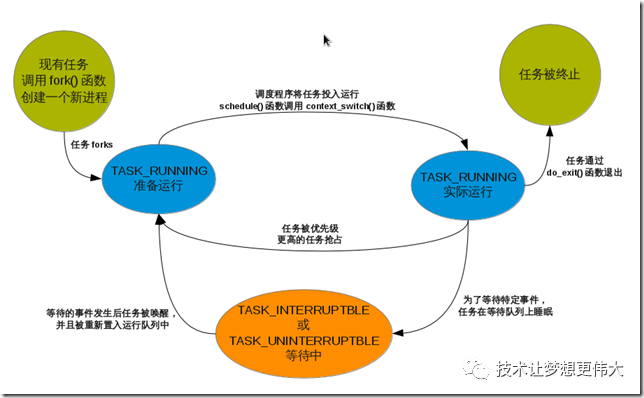
struct prio_array {int nr_active; //计数器,记录优先权数组中的进程数unsigned long bitmap[BITMAP_SIZE]; //bitmap是记录数组中的优先权,实际长度取决于系统无符号长整型的大小struct list_head queue[MAX_PRIO]; //queue存储进程链表的数组,且每个链表含有特定优先权的进程}; 最后讲到的是异步执行流程,我们说过,进程能够通过终端中断一个状态转换到另一个状态,获得这种转换的唯一途径就包括异常和中断在内的异步。
最后讲到的是异步执行流程,我们说过,进程能够通过终端中断一个状态转换到另一个状态,获得这种转换的唯一途径就包括异常和中断在内的异步。struct page{unsigned long flags; //flags用来存放页的状态,每一位代表一种状态atomic_t count; //count记录了该页被引用了多少次unsigned int mapcount;unsigned long private; struct address_space *mapping; //mapping指向与该页相关的address_space对象 pgoff_t index; struct list_head lru; //存放的next和prev指针,指向最近使用(LRU)链表中的相应结点 union { struct pte_chain; pte_addr_t; } void *virtual; //virtual是页的虚拟地址,它就是页在虚拟内存中的地址}struct zone {spinlock_t lock; //lock域是一个自旋锁,这个域只保护结构,而不是保护驻留在这个区中的所有页unsigned long free_pages; //持有该内存区中所剩余的空闲页链表unsigned long pages_min, pages_low, pages_high; //持有内存区的水位值unsigned long protection[MAX_NR_ZONES];spinlock_t lru_lock; //持有保护空闲页链表的自旋锁struct list_head active_list; 在页面回收处理时,处于活动状态的页链表struct list_head inactive_list; //在页面回收处理时,是可以被回收的页链表unsigned long nr_scan_active;unsigned long nr_scan_inactive;unsigned long nr_active;unsigned long nr_inactive;int all_unreclaimable; //内存的所有页锁住时,此值置1unsigned long pages_scanned; //用于页面回收处理中struct free_area free_area[MAX_ORDER];wait_queue_head_t * wait_table;unsigned long wait_table_size;unsigned long wait_table_bits; //用于处理该内存区页上的进程等待struct per_cpu_pageset pageset[NR_CPUS];struct pglist_data *zone_pgdat;struct page *zone_mem_map;unsigned long zone_start_pfn;char *name;unsigned long spanned_pages;unsigned long present_pages;};#define alloc_pages(gfp_mask,order) alloc_pages_node(numa_node_id(),gfp_mask,order)#define alloc_page(gfp_mask) alloc_pages_node(numa_node_id(),gfp_mask,0)include/linux/gfp.h#define __get_dma_pages(gfp_mask,order) \__get_free_pages((gfp_mask)|GFP_DMA,(order))include/linux/gfp.h#define __get_dma_pages(gfp_mask,order) \__get_free_pages((gfp_mask)|GFP_DMA,(order))extern void __free_pages(struct page *page, unsigned int order);extern void free_pages(unsigned long addr, unsigned int order);void *kmalloc(size_t size, gfp_t flags)void kfree(const void *objp)void *vmalloc(unsigned long size)void vfree(const void *addr)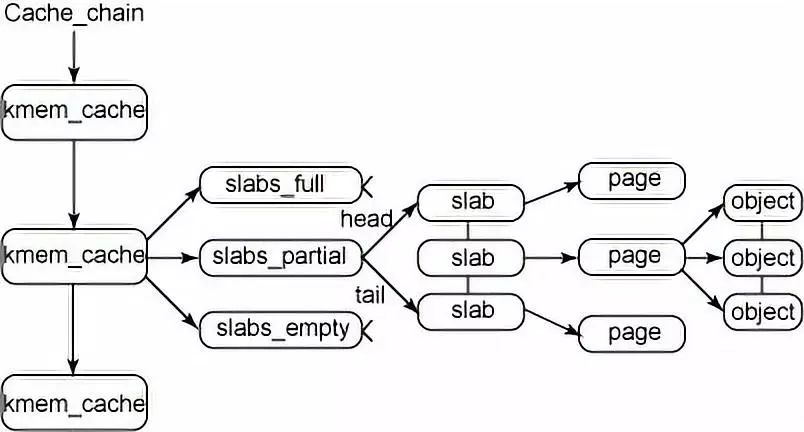 在最高层是 cache_chain,这是一个 slab 缓存的链接列表。可以用来查找最适合所需要的分配大小的缓存。cache_chain 的每个元素都是一个 kmem_cache 结构的引用。一个kmem_cache中的所有object大小都相同。这里我们首先看看缓存描述符中各个域以及他们的含义。
在最高层是 cache_chain,这是一个 slab 缓存的链接列表。可以用来查找最适合所需要的分配大小的缓存。cache_chain 的每个元素都是一个 kmem_cache 结构的引用。一个kmem_cache中的所有object大小都相同。这里我们首先看看缓存描述符中各个域以及他们的含义。struct kmem_cache_s{struct kmen_list3 lists; //lists域中包含三个链表头,每个链表头均对应了slab所处的三种状态(满,未满,空闲)之一,unsigned int objsize; //objsize域中持有缓存中对象的大小unsigned int flags; //flags持有标志掩码,其描述了缓存固有特性unsigned int num; //num域中持有缓存中每个slab所包含的对象数目unsigned int gfporder; //缓存中每个slab所占连续页面数的幂,该值默认0size_t color; unsigned int color_off;unsigned int color_next;kmem_cache_t *slabp_cache; //可存储在自身缓存中也可以存在外部其他缓存中unsigned int dflags;void (*ctor) (void *,kmem_cache_t*,unsigened long);void (*dtor)(void*,kmem_cache_t *,unsigend long);const char *name; //name持有易于理解的名称struct list_head next; //next域指向下个单向缓存描述符链表上的缓存描述符};struct cache_sizes{size_t cs_size; //持有该缓存中容纳的内存对象大小kmem_cache_t *cs_cachep; //持有指向普通内存缓存描述符飞指针kmem_cache_t *cs_dmacachep; //持有指向DMA内存缓存描述符的指针,分配自ZONE_DMA};| Free | Partial | Full | |
| Slab->inuse | 0 | X | N |
| Slab->free | 0 | X | N |
struct kmem_cache *kmem_cache_create ( const char *name, //定义了缓存名称 size_t size, //指定了为这个缓存创建的对象的大小 size_t align, //定义了每个对象必需的对齐。 unsigned long flags, //指定了为缓存启用的选项 void (*ctor)(void *)) //定义了一个可选的对象构造器和析构器。构造器和析构器是用户提供的回调函数。当从缓存中分配新对象时,可以通过构造器进行初始化。void kmem_cache_alloc( struct kmem_cache *cachep, gfp_t flags );//cachep是需要扩充的缓存描述符//flags这些标志将用于创建slabint kmem_cache_destroy(kmem_cache_t *cachep){int i;if(!cache || in_interrupt()) BUG(); //完成健全性检查 down(&cache_chain_sem); list_del(&cachep->next); up(&cache_chain_sem); //获得cache_chain信号量从缓存中删除指定缓存,释放cache_chain信号量if(_cache_shrink(cachep)){ slab_error(cachep,"Can't free all objects"); down(&cache_chain_sem); list_add(&cache->next,&cache_chain); up(&cache_chain_sem);return 1; //该段负责释放为使用slab } ... kmem_cache_free(&cache_cache,cachep); //释放缓存描述符return 0;}#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)extern inline unsigned long virt_to_phys(volatile void * address){return __pa(address);}struct mm_struct { struct vm_area_struct * mmap; /* 指向虚拟区间(VMA)链表 */ rb_root_t mm_rb; /*指向red_black树*/ struct vm_area_struct * mmap_cache; /* 指向最近找到的虚拟区间*/ pgd_t * pgd; /*指向进程的页目录*/ atomic_t mm_users; /* 用户空间中的有多少用户*/ atomic_t mm_count; /* 对"struct mm_struct"有多少引用*/ int map_count; /* 虚拟区间的个数*/ struct rw_semaphore mmap_sem; spinlock_t page_table_lock; /* 保护任务页表和 mm->rss */ struct list_head mmlist; /*所有活动(active)mm的链表 */ unsigned long start_code, end_code, start_data, end_data; /*start_code 代码段起始地址,end_code 代码段结束地址,start_data 数据段起始地址, start_end 数据段结束地址*/ unsigned long start_brk, brk, start_stack; /*start_brk 和brk记录有关堆的信息, start_brk是用户虚拟地址空间初始化时,堆的结束地址, brk 是当前堆的结束地址, start_stack 是栈的起始地址*/ unsigned long arg_start, arg_end, env_start, env_end; /*arg_start 参数段的起始地址, arg_end 参数段的结束地址, env_start 环境段的起始地址, env_end 环境段的结束地址*/ unsigned long rss, total_vm, locked_vm; unsigned long def_flags; unsigned long cpu_vm_mask; unsigned long swap_address;....};void *kmap(struct page *page)void kunmap(struct page *page) void *kmap_atomic(struct page *page)static int memory_open(struct inode * inode * inode,struct file * filp){switch (iminor(inode)) { //switch语句根据从设备号来初始化驱动程序的数据结构case 1: ...case 8: filp->f_op = &random_fops;break;case 9: filp->f_op = &urandom_fops;break;struct file {struct list_head f_list;struct dentry *f_dentry;struct vfsmount *f_vfsmnt;struct file_operations *f_op;atomic_t f_count;unsigned int f_flags;...struct address_space *f_mapping;};struct file_operations random_fops = { .read = random_read, .write = random_write, .poll = random_poll, //poll操作允许某种操作之前查看该操作是否阻塞 .ioctl = random_ioctl,}; //随机设备提供的操作有以上struct file_operations urandom_fops = { .read = random_read, .write = random_write, .ioctl = random_ioctl,}; //urandom设备提供的操作有以上static ssize_t extract_entropy(struct entract_syore *r,void *buf,size_t nbytes,int flags){...{static ssize_t extract_entropy(struct entropy_store *r,void *buf,size_t nbytes,int flags){下面我们来介绍怎么去编写源代码,当我们去编写一个复杂的设备驱动程序时,也许要输出驱动程序中定义的某些符合,以便让内核其它模块使用,这些通常被用在低级的驱动程序中,以便根据这些基本的函数来构建更高级的驱动程序,在Linux2.6内核中,code monkey可以用如下两个宏输出符号,代码在include/linux/module.h中查看:
#define EXPORT_SYMBOL(sym) __EXPORT_SYMBOL(sym, "")#define EXPORT_SYMBOL_GPL(sym) __EXPORT_SYMBOL(sym, "_gpl")int ioctl(int fd, ind cmd, …);unsigned long __must_check copy_to_user(void __user *to,const void *from, unsigned long n);unsigned long __must_check copy_from_user(void *to,const void __user *from, unsigned long n);#define get_user(x,ptr)#define put_user(x,ptr)//x是内核空间的简单数据类型地址,ptr是用户空间地址指针。static inline struct proc_dir_entry *create_proc_read_entry(const char *name, mode_t mode,struct proc_dir_entry *base, read_proc_t *read_proc,void * data)
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态