首页
HTML
前端
框架
JavaScript
CSS
首页
/
python解析html標簽
python爬去去掉標簽,pythonboxplot_在python中,如何將標簽添加到plotly boxplot?
對于標簽,請嘗試annotations.你必須計算四分位數,并讓你自己來定位標簽。在簡單示例:import plotly.plotly as pypython爬去去掉標簽?from plotly.graph_objs import *data = Data([Box(python有什么用。y=[0, 1, 1, 2, 3, 5, 8, 13, 21],boxpo
时间:2023-11-19 | 阅读:43
python中eval函數作用,python轉義html字符串,用python處理html代碼的轉義與復原
抓網頁數據經常遇到例如>或者?這種HTML轉義符,抓到字符串里很是煩人。比方說一個從網頁中抓到的字符串python中eval函數作用?html = '<abc>'用Python可以這樣處理:importHTMLParserpython生成html。html_parser =HTMLParser.HTMLPars
时间:2023-11-19 | 阅读:25
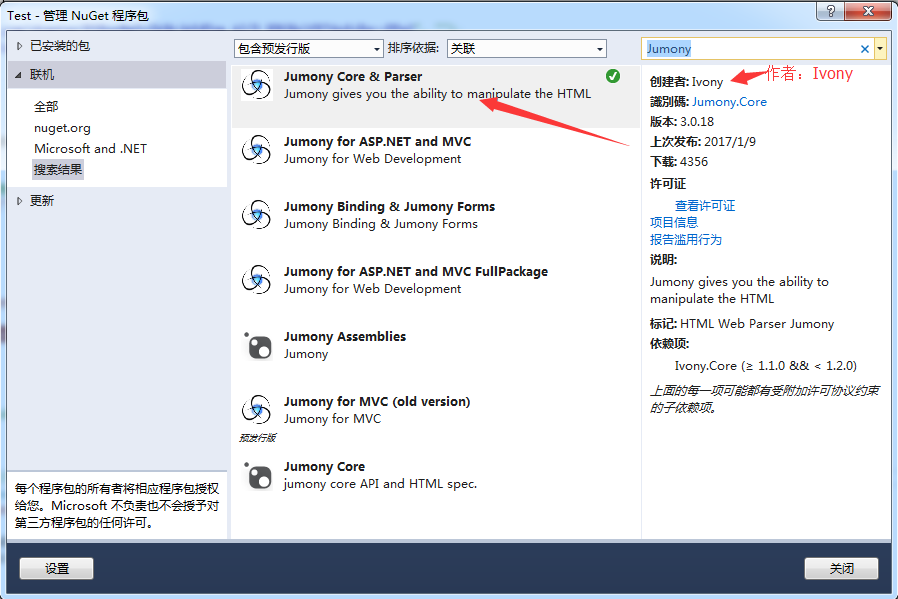
表達式解析引擎,HTML解析引擎:Jumony
Jumony Core首先提供了一個近乎完美的HTML解析引擎,其解析結果無限逼近瀏覽器的解析結果。不論是無結束標簽的元素,可選結束標簽的元素,或是標記屬性,或是CSS選擇器和樣式,一切合法的,不合法的HTML文檔,瀏覽器解析成啥樣&#x
时间:2023-11-19 | 阅读:21
c語言爬蟲和python爬蟲,c 爬蟲 html解析,C# 爬蟲 Jumony html解析
前言前幾天寫了個爬蟲,然后認識到了自己的不足。?烽火情懷推薦了Jumony.Core,通過倚天照海- -推薦的文章,也發現了Jumony.Core。c語言爬蟲和python爬蟲?研究了2天,我發現這個東西簡單粗暴,非常好用,因為語法比較像jQuery。上手快&
时间:2023-11-19 | 阅读:25
微信小程序怎么登,微信小程序使用wxParse解析html
最近項目上遇到在微信小程序里需要渲染文章,后臺返回的是html格式的,小程序默認是不支持html格式的內容顯示的,那我們需要顯示html內容的時候,就可以通過wxParse來實現。首先我們在github上下載wxParsehttps://github.com/icindy/wxParse wxParse
时间:2023-11-19 | 阅读:23
python解析xml文件,python 解析labelme
目錄 python 解析labelme 標簽去掉imagedata labelme轉voc格式: labelme檢測關鍵點標注: python 解析labelme import glob import json import json import cv2 import osfile_dir=r'F:\project\jushi\data\CAM-G
时间:2023-11-07 | 阅读:28
css選擇器有哪幾種,Python scrapy 中的css選擇器提取 a 標簽的 href值
response.css(".copyright-area a::attr(href)").extract()[0] ?
时间:2023-10-06 | 阅读:24
阅读排行
807℃
1
职业性格测试
790℃
2
【小程序项目开发-- 京东商...
732℃
3
ORA-14402:updating parti...
727℃
4
Android系统操作的50个实用...
686℃
5
mac上tflite编译
638℃
6
一分钟自我介绍 建议
562℃
7
IT人不要一直做技术
558℃
8
多線程調用同一個對象的方...
猜你喜欢
html基础、css基础(前端基础知识入门)
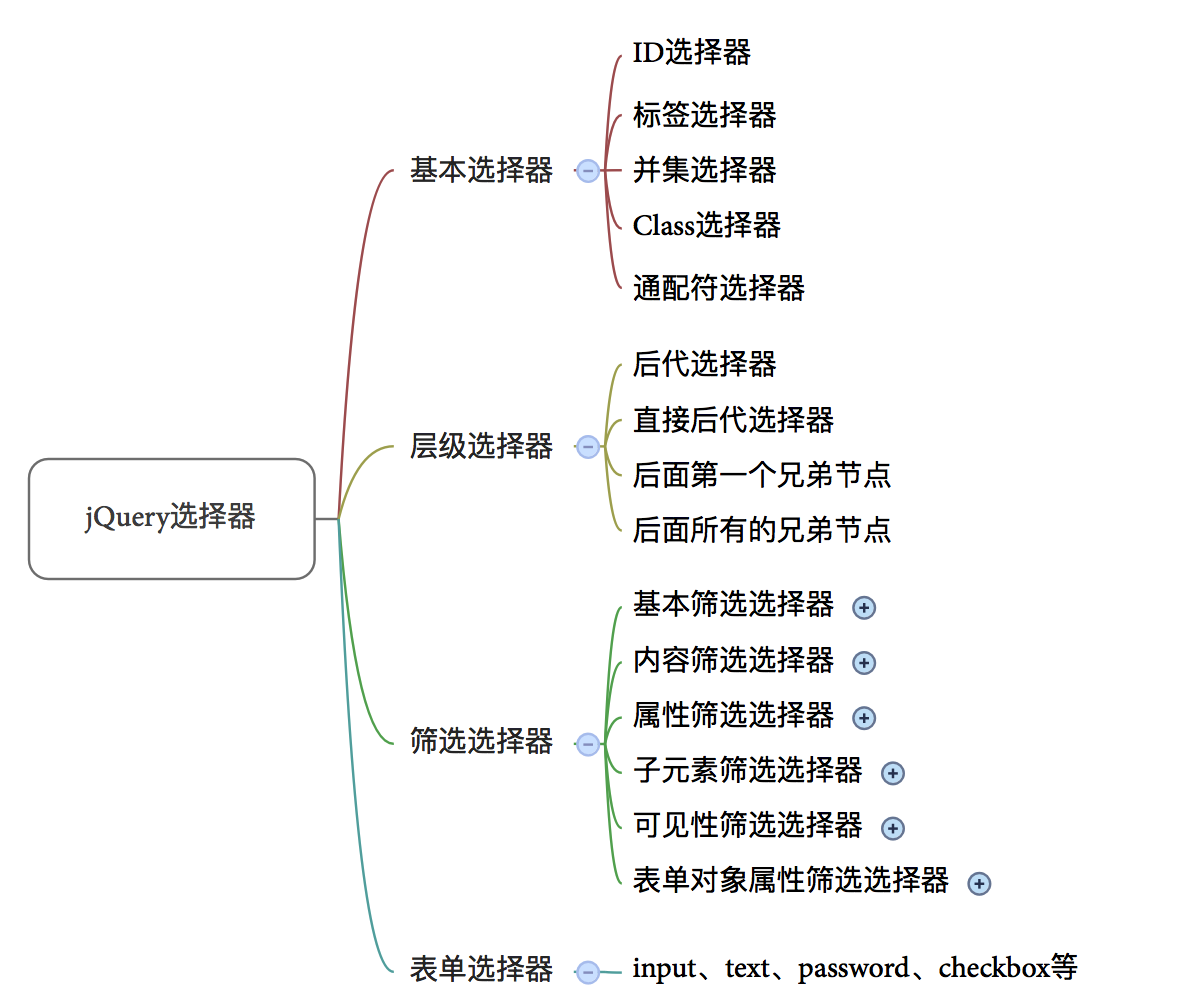
jQuery系列 第四章 jQuery框架的选择器
嵌入式软件工程师是干啥的?
[Classic AUTOSAR学习] DLT模块(LogTrace)
50幅精美绝伦的世界各地风光摄影作品欣赏(下篇)
IAM 使用总结
GeekPwn2019国际安全极客大赛
Node js 集群(cluster)
使用NSIS制作驱动安装包
数学史上的三次危机
oracle数据库归档闪回,oracle数据库开归档闪回模式
android 剪切板监听_android剪切板操作
热门标签
python3
python有什么用
python和java
python爬虫教程
python为什么叫爬虫
Spring Boot
UNIXLINUX
LINUX教程
python爬蟲教程
python编程
springboot
Mybatis
linux
Java
python怎么用
python編程
什么是LINUX
android
我要关灯
我要开灯
客户电话
808629
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部








![[Classic AUTOSAR学习] DLT模块(LogTrace)](https://img-blog.csdnimg.cn/img_convert/741a22837c882ba5e49acbcbc983c2f9.jpeg)