1)實驗平臺:正點原子阿爾法Linux開發板
2)平臺購買地址:https://item.taobao.com/item.htm?id=603672744434
2)全套實驗源碼+手冊+視頻下載地址:http://www.openedv.com/thread-300792-1-1.html
3)對正點原子Linux感興趣的同學可以加群討論:935446741
4)關注正點原子公眾號,獲取最新資料更新

第九章進程
本章將討論進程相關的知識內容,雖然在前面章節內容已經多次向大家提到了進程這個概念,但并未真正地向大家解釋這個概念;在本章,我們將一起來學習Linux下進程相關的知識內容,雖然進程的基本概念比較簡單,但是其所涉及到的細節內容比較多,所以本章篇幅也會相對比較長,所以,大家加油!
本章將會討論如下主題內容。
LINUX教程、?程序與進程基本概念;
?程序的開始與結束;
?進程的環境變量與虛擬地址空間;
?進程ID;
?fork()創建子進程;
?進程的消亡與誕生;
?僵尸進程與孤兒進程;
?父進程監視子進程;
?進程關系與進程的六種狀態;
?守護進程;
?進程間通信概述
10.1進程與程序
10.1.1main()函數由誰調用?
C語言程序總是從main函數開始執行,main()函數的原型是:
int main(void)
或
int main(int argc, char *argv[])
如果需要向應用程序傳參,則選擇第二種寫法。不知大家是否想過“誰”調用了main()函數?事實上,操作系統下的應用程序在運行main()函數之前需要先執行一段引導代碼,最終由這段引導代碼去調用應用程序的main()函數,我們在編寫應用程序的時候,不用考慮引導代碼的問題,在編譯鏈接時,由鏈接器將引導代碼鏈接到我們的應用程序當中,一起構成最終的可執行文件。
當執行應用程序時,在Linux下輸入可執行文件的相對路徑或絕對路徑就可以運行該程序,譬如./app或/home/dt/app,還可根據應用程序是否接受傳參在執行命令時在后面添加傳入的參數信息,譬如./app arg1 arg2或/home/dt/app arg1 arg2。程序運行需要通過操作系統的加載器來實現,加載器是操作系統中的程序,當執行程序時,加載器負責將此應用程序加載內存中去執行。
所以由此可知,對于操作系統下的應用程序來說,鏈接器和加載器都是很重要的角色!
再來看看argc和argv傳參是如何實現的呢?譬如./app arg1 arg2,這兩個參數arg1和arg2是如何傳遞給應用程序的main函數的呢?當在終端執行程序時,命令行參數(command-line argument)由shell進程逐一進行解析,shell進程會將這些參數傳遞給加載器,加載器加載應用程序時會將其傳遞給應用程序引導代碼,當引導程序調用main()函數時,在由它最終傳遞給main()函數,如此一來,在我們的應用程序當中便可以獲取到命令行參數了。
10.1.2程序如何結束?
程序結束其實就是進程終止,進程終止的方式通常有多種,大體上分為正常終止和異常終止,正常終止包括:
?main()函數中通過return語句返回來終止進程;
?應用程序中調用exit()函數終止進程;
?應用程序中調用_exit()或_Exit()終止進程;
以上這些是在前面的課程中給大家介紹的,異常終止包括:
?應用程序中調用abort()函數終止進程;
?進程接收到一個信號,譬如SIGKILL信號。
注冊進程終止處理函數atexit()
atexit()庫函數用于注冊一個進程在正常終止時要調用的函數,其函數原型如下所示:
#include <stdlib.h>
int atexit(void (*function)(void));
使用該函數需要包含頭文件<stdlib.h>。
函數參數和返回值含義如下:
function:函數指針,指向注冊的函數,此函數無需傳入參數、無返回值。
返回值:成功返回0;失敗返回非0。
測試
編寫一個測試程序,使用atexit()函數注冊一個進程在正常終止時需要調用的函數,測試代碼如下。
示例代碼 10.1.1 atexit()函數使用示例
#include <stdio.h>
#include <stdlib.h>static void bye(void)
{puts("Goodbye!");
}int main(int argc, char *argv[])
{if (atexit(bye)) {fprintf(stderr, "cannot set exit function\n");exit(-1);}exit(0);
}
運行結果:
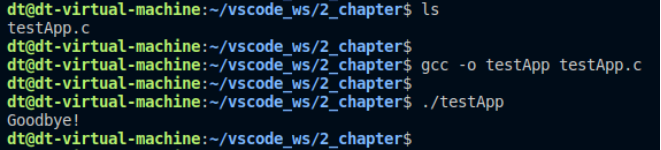
UNIX/LINUX。圖 10.1.1 測試結果
需要說明的是,如果程序當中使用了_exit()或_Exit()終止進程而并非是exit()函數,那么將不會執行注冊的終止處理函數。
10.1.3何為進程?
本小節正式向大家介紹進程這個概念,前面的內容中也已經多次提到了,其實這個概念本身非常簡單,進程其實就是一個可執行程序的實例,這句話如何理解呢?可執行程序就是一個可執行文件,文件是一個靜態的概念,存放磁盤中,如果可執行文件沒有被運行,那它將不會產生什么作用,當它被運行之后,它將會對系統環境產生一定的影響,所以可執行程序的實例就是可執行文件被運行。
進程是一個動態過程,而非靜態文件,它是程序的一次運行過程,當應用程序被加載到內存中運行之后它就稱為了一個進程,當程序運行結束后也就意味著進程終止,這就是進程的一個生命周期。
10.1.4進程號
Linux系統下的每一個進程都有一個進程號(process ID,簡稱PID),進程號是一個正數,用于唯一標識系統中的某一個進程。在Ubuntu系統下執行ps命令可以查到系統中進程相關的一些信息,包括每個進程的進程號,如下所示:

圖 10.1.2 ps命令查看進程信息
上圖中紅框標識顯示的便是每個進程所對應的進程號,進程號的作用就是用于唯一標識系統中某一個進程,在某些系統調用中,進程號可以作為傳入參數、有時也可作為返回值。譬如系統調用kill()允許調用者向某一個進程發送一個信號,如何表示這個進程呢?則是通過進程號進行標識。
在應用程序中,可通過系統調用getpid()來獲取本進程的進程號,其函數原型如下所示:
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
使用該函數需要包含頭文件<sys/types.h>和<unistd.h>。
函數返回值為pid_t類型變量,便是對應的進程號。
使用示例
使用getpid()函數獲取進程的進程號。
示例代碼 10.1.2 getpid()使用示例
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>int main(void)
{pid_t pid = getpid();printf("本進程的PID為: %d\n", pid);exit(0);
}
運行結果:
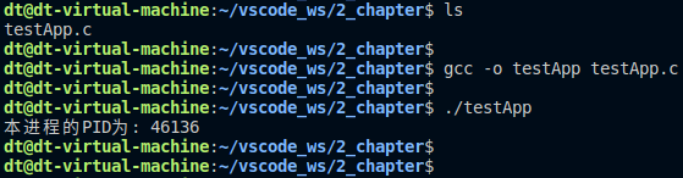
圖 10.1.3 測試結果
除了getpid()用于獲取本進程的進程號之外,還可以使用getppid()系統調用獲取父進程的進程號,其函數原型如下所示:
#include <sys/types.h>
#include <unistd.h>pid_t getppid(void);
返回值對應的便是父進程的進程號。
使用示例
獲取進程的進程號和父進程的進程號。
示例代碼 10.1.3 getppid()使用示例
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>int main(void)
{pid_t pid = getpid(); //獲取本進程pidprintf("本進程的PID為: %d\n", pid);pid = getppid(); //獲取父進程pidprintf("父進程的PID為: %d\n", pid);exit(0);
}
運行結果:
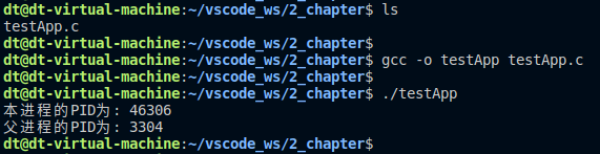
圖 10.1.4 測試結果
10.2進程的環境變量
每一個進程都有一組與其相關的環境變量,這些環境變量以字符串形式存儲在一個字符串數組列表中,把這個數組稱為環境列表。其中每個字符串都是以“名稱=值(name=value)”形式定義,所以環境變量是“名稱-值”的成對集合,譬如在shell終端下可以使用env命令查看到shell進程的所有環境變量,如下所示:

圖 10.2.1 env命令查看環境變量
使用export命令還可以添加一個新的環境變量或刪除一個環境變量:
export LINUX_APP=123456 # 添加LINUX_APP環境變量

圖 10.2.2 export添加環境變量
使用"export -n LINUX_APP"命令則可以刪除LINUX_APP環境變量。
export -n LINUX_APP # 刪除LINUX_APP環境變量
10.2.1應用程序中獲取環境變量
在我們的應用程序當中也可以獲取當前進程的環境變量,事實上,進程的環境變量是從其父進程中繼承過來的,譬如在shell終端下執行一個應用程序,那么該進程的環境變量就是從其父進程(shell進程)中繼承過來的。新的進程在創建之前,會繼承其父進程的環境變量副本。
環境變量存放在一個字符串數組中,在應用程序中,通過environ變量指向它,environ是一個全局變量,在我們的應用程序中只需申明它即可使用,如下所示:
extern char **environ; // 申明外部全局變量environ
測試
編寫應用程序,獲取進程的所有環境變量。
示例代碼 10.2.1 獲取進程環境變量
#include <stdio.h>
#include <stdlib.h>extern char **environ;int main(int argc, char *argv[])
{int i;/* 打印進程的環境變量 */for (i = 0; NULL != environ[i]; i++)puts(environ[i]);exit(0);
}
通過字符串數組元素是否等于NULL來判斷是否已經到了數組的末尾。
運行結果:

圖 10.2.3 測試結果
獲取指定環境變量getenv()
如果只想要獲取某個指定的環境變量,可以使用庫函數getenv(),其函數原型如下所示:
#include <stdlib.h>
char *getenv(const char *name);
使用該函數需要包含頭文件<stdlib.h>。
函數參數和返回值含義如下:
name:指定獲取的環境變量名稱。
返回值:如果存放該環境變量,則返回該環境變量的值對應字符串的指針;如果不存在該環境變量,則返回NULL。
使用getenv()需要注意,不應該去修改其返回的字符串,修改該字符串意味著修改了環境變量對應的值,Linux提供了相應的修改函數,如果需要修改環境變量的值應該使用這些函數,不應直接改動該字符串。
使用示例
示例代碼 10.2.2 getenv()函數使用示例
#include <stdio.h>
#include <stdlib.h>int main(int argc, char *argv[])
{const char *str_val = NULL;if (2 > argc) {fprintf(stderr, "Error: 請傳入環境變量名稱\n");exit(-1);}/* 獲取環境變量 */str_val = getenv(argv[1]);if (NULL == str_val) {fprintf(stderr, "Error: 不存在[%s]環境變量\n", argv[1]);exit(-1);}/* 打印環境變量的值 */printf("環境變量的值: %s\n", str_val);exit(0);
}
運行結果:

圖 10.2.4 測試結果
10.2.2添加/刪除/修改環境變量
C語言函數庫中提供了用于修改、添加、刪除環境變量的函數,譬如putenv()、setenv()、unsetenv()、clearenv()函數等。
putenv()函數
putenv()函數可向進程的環境變量數組中添加一個新的環境變量,或者修改一個已經存在的環境變量對應的值,其函數原型如下所示:
#include <stdlib.h>
int putenv(char *string);
使用該函數需要包含頭文件<stdlib.h>。
函數參數和返回值含義如下:
string:參數string是一個字符串指針,指向name=value形式的字符串。
返回值:成功返回0;失敗將返回非0值,并設置errno。
該函數調用成功之后,參數string所指向的字符串就成為了進程環境變量的一部分了,換言之,putenv()函數將設定environ變量(字符串數組)中的某個元素(字符串指針)指向該string字符串,而不是指向它的復制副本,這里需要注意!因此,不能隨意修改參數string所指向的內容,這將影響進程的環境變量,出于這種原因,參數string不應為自動變量(即在棧中分配的字符數組),因為定義吃變量。
測試
使用putenv()函數為當前進程添加一個環境變量。
示例代碼 10.2.3 putenv()函數使用示例
#include <stdio.h>
#include <stdlib.h>int main(int argc, char *argv[])
{if (2 > argc) {fprintf(stderr, "Error: 傳入name=value\n");exit(-1);}/* 添加/修改環境變量 */if (putenv(argv[1])) {perror("putenv error");exit(-1);}exit(0);
}
setenv()函數
setenv()函數可以替代putenv()函數,用于向進程的環境變量列表中添加一個新的環境變量或修改現有環境變量對應的值,其函數原型如下所示:
#include <stdlib.h>
int setenv(const char *name, const char *value, int overwrite);
使用該函數需要包含頭文件<stdlib.h>。
函數參數和返回值含義如下:
name:需要添加或修改的環境變量名稱。
value:環境變量的值。
overwrite:若參數name標識的環境變量已經存在,在參數overwrite為0的情況下,setenv()函數將不改變現有環境變量的值,也就是說本次調用沒有產生任何影響;如果參數overwrite的值為非0,若參數name標識的環境變量已經存在,則覆蓋,不存在則表示添加新的環境變量。
返回值:成功返回0;失敗將返回-1,并設置errno。
setenv()函數為形如name=value的字符串分配一塊內存緩沖區,并將參數name和參數value所指向的字符串復制到此緩沖區中,以此來創建一個新的環境變量,所以,由此可知,setenv()與putenv()函數有兩個區別:
?putenv()函數并不會為name=value字符串分配內存;
?setenv()可通過參數overwrite控制是否需要修改現有變量的值而僅以添加變量為目的,顯然putenv()并不能進行控制。
推薦大家使用setenv()函數,這樣使用自動變量作為setenv()的參數也不會有問題。
使用示例
示例代碼 10.2.4 setenv()函數使用示例
#include <stdio.h>
#include <stdlib.h>int main(int argc, char *argv[])
{if (3 > argc) {fprintf(stderr, "Error: 傳入name value\n");exit(-1);}/* 添加環境變量 */if (setenv(argv[1], argv[2], 0)) {perror("setenv error");exit(-1);}exit(0);
}
除了上面給大家介紹的函數之外,我們還可以通過一種更簡單地方式向進程環境變量表中添加環境變量,用法如下:
NAME=value ./app
在執行程序的時候,在其路徑前面添加環境變量,以name=value的形式添加,如果是多個環境變量,則在./app前面放置多對name=value即可,以空格分隔。
unsetenv()函數
unsetenv()函數可以從環境變量表中移除參數name標識的環境變量,其函數原型如下所示:
#include <stdlib.h>
int unsetenv(const char *name);
10.2.3清空環境變量
有時,需要清除環境變量表中的所有變量,然后再進行重建,可以通過將全局變量environ賦值為NULL來清空所有變量。
environ = NULL;
也可通過clearenv()函數來操作,函數原型如下所示:
#include <stdlib.h>
int clearenv(void);
clearenv()函數內部的做法其實就是將environ賦值為NULL。在某些情況下,使用setenv()函數和clearenv()函數可能會導致程序內存泄漏,前面提到過,setenv()函數會為環境變量分配一塊內存緩沖區,隨之稱為進程的一部分;而調用clearenv()函數時沒有釋放該緩沖區(clearenv()調用并不知曉該緩沖區的存在,故而也無法將其釋放),反復調用者兩個函數的程序,會不斷產生內存泄漏。
10.2.4環境變量的作用
環境變量常見的用途之一是在shell中,每一個環境變量都有它所表示的含義,譬如HOME環境變量表示用戶的家目錄,USER環境變量表示當前用戶名,SHELL環境變量表示shell解析器名稱,PWD環境變量表示當前所在目錄等,在我們自己的應用程序當中,也可以使用進程的環境變量。
10.3進程的內存布局
歷史沿襲至今,C語言程序一直都是由以下幾部分組成的:
?正文段。也可稱為代碼段,這是CPU執行的機器語言指令部分,文本段具有只讀屬性,以防止程序由于意外而修改其指令;正文段是可以共享的,即使在多個進程間也可同時運行同一段程序。
?初始化數據段。通常將此段稱為數據段,包含了顯式初始化的全局變量和靜態變量,當程序加載到內存中時,從可執行文件中讀取這些變量的值。
?未初始化數據段。包含了未進行顯式初始化的全局變量和靜態變量,通常將此段稱為bss段,這一名詞來源于早期匯編程序中的一個操作符,意思是“由符號開始的塊”(block started by symbol),在程序開始執行之前,系統會將本段內所有內存初始化為0,可執行文件并沒有為bss段變量分配存儲空間,在可執行文件中只需記錄bss段的位置及其所需大小,直到程序運行時,由加載器來分配這一段內存空間。
?棧。函數內的局部變量以及每次函數調用時所需保存的信息都放在此段中,每次調用函數時,函數傳遞的實參以及函數返回值等也都存放在棧中。棧是一個動態增長和收縮的段,由棧幀組成,系統會為每個當前調用的函數分配一個棧幀,棧幀中存儲了函數的局部變量(所謂自動變量)、實參和返回值。
?堆。可在運行時動態進行內存分配的一塊區域,譬如使用malloc()分配的內存空間,就是從系統堆內存中申請分配的。
Linux下的size命令可以查看二進制可執行文件的文本段、數據段、bss段的段大小:
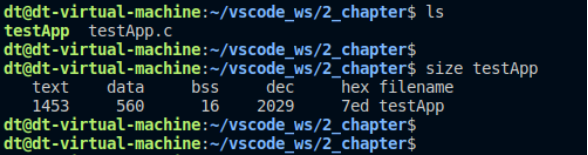
圖 10.3.1 size命令
圖 9.3.2顯示了這些段在內存中的典型布局方式,當然,并不要求具體的實現一定是以這種方式安排其存儲空間,但這是一種便于我們說明的典型方式。

圖 10.3.2 在Linux/x86-32體系中進程內存布局
10.4進程的虛擬地址空間
上一小節我們討論了C語言程序的構成以及運行時進程在內存中的布局方式,在Linux系統中,采用了虛擬內存管理技術,事實上大多數現在操作系統都是如此!在Linux系統中,每一個進程都在自己獨立的地址空間中運行,在32位系統中,每個進程的邏輯地址空間均為4GB,這4GB的內存空間按照3:1的比例進行分配,其中用戶進程享有3G的空間,而內核獨自享有剩下的1G空間,如下所示:
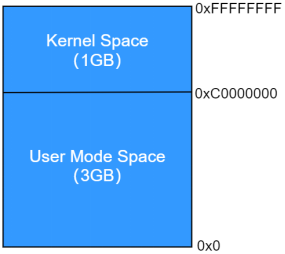
圖 10.4.1 Linux系統下邏輯地址空間劃分
學習過驅動開發的讀者對“虛擬地址”這個概念應該并不陌生,虛擬地址會通過硬件MMU(內存管理單元)映射到實際的物理地址空間中,建立虛擬地址到物理地址的映射關系后,對虛擬地址的讀寫操作實際上就是對物理地址的讀寫操作,MMU會將物理地址“翻譯”為對應的物理地址,其關系如下所示:

圖 10.4.2 虛擬地址到物理地址的映射關系
Linux系統下,應用程序運行在一個虛擬地址空間中,所以程序中讀寫的內存地址對應也是虛擬地址,并不是真正的物理地址,譬如應用程序中讀寫0x80800000這個地址,實際上并不對應于硬件的0x80800000這個物理地址。
為什么需要引入虛擬地址呢?
計算機物理內存的大小是固定的,就是計算機的實際物理內存,試想一下,如果操作系統沒有虛擬地址機制,所有的應用程序訪問的內存地址就是實際的物理地址,所以要將所有應用程序加載到內存中,但是我們實際的物理內存只有4G,所以就會出現一些問題:
?當多個程序需要運行時,必須保證這些程序用到的內存總量要小于計算機實際的物理內存的大小。
?內存使用效率低。內存空間不足時,就需要將其它程序暫時拷貝到硬盤中,然后將新的程序裝入內存。然而由于大量的數據裝入裝出,內存的使用效率就會非常低。
?進程地址空間不隔離。由于程序是直接訪問物理內存的,所以每一個進程都可以修改其它進程的內存數據,甚至修改內核地址空間中的數據,所以有些惡意程序可以隨意修改別的進程,就會造成一些破壞,系統不安全、不穩定。
?無法確定程序的鏈接地址。程序運行時,鏈接地址和運行地址必須一致,否則程序無法運行!因為程序代碼加載到內存的地址是由系統隨機分配的,是無法預知的,所以程序的運行地址在編譯程序時是無法確認的。
針對以上的一些問題,就引入了虛擬地址機制,程序訪問存儲器所使用的邏輯地址就是虛擬地址,通過邏輯地址映射到真正的物理內存上。所有應用程序運行在自己的虛擬地址空間中,使得進程的虛擬地址空間和物理地址空間隔離開來,這樣做帶來了很多的優點:
?進程與進程、進程與內核相互隔離。一個進程不能讀取或修改另一個進程或內核的內存數據,這是因為每一個進程的虛擬地址空間映射到了不同的物理地址空間。提高了系統的安全性與穩定性。
?在某些應用場合下,兩個或者更多進程能夠共享內存。因為每個進程都有自己的映射表,可以讓不同進程的虛擬地址空間映射到相同的物理地址空間中。通常,共享內存可用于實現進程間通信。
?便于實現內存保護機制。譬如在多個進程共享內存時,允許每個進程對內存采取不同的保護措施,例如,一個進程可能以只讀方式訪問內存,而另一進程則能夠以可讀可寫的方式訪問。
?編譯應用程序時,無需關心鏈接地址。前面提到了,當程序運行時,要求鏈接地址與運行地址一致,在引入了虛擬地址機制后,便無需關心這個問題。
關于本小節的內容就介紹這么多,理解本小節的內容可以幫助我們更好地理解后面小節中將要介紹的內容。
10.5fork()創建子進程
一個現有的進程可以調用fork()函數創建一個新的進程,調用fork()函數的進程稱為父進程,由fork()函數創建出來的進程被稱為子進程(child process),fork()函數原型如下所示(fork()為系統調用):
#include <unistd.h>
pid_t fork(void);
使用該函數需要包含頭文件<unistd.h>。
在諸多的應用中,創建多個進程是任務分解時行之有效的方法,譬如,某一網絡服務器進程可在監聽客戶端請求的同時,為處理每一個請求事件而創建一個新的子進程,與此同時,服務器進程會繼續監聽更多的客戶端連接請求。在一個大型的應用程序任務中,創建子進程通常會簡化應用程序的設計,同時提高了系統的并發性(即同時能夠處理更多的任務或請求,多個進程在宏觀上實現同時運行)。
理解fork()系統調用的關鍵在于,完成對其調用后將存在兩個進程,一個是原進程(父進程)、另一個則是創建出來的子進程,并且每個進程都會從fork()函數的返回處繼續執行,會導致調用fork()返回兩次值,子進程返回一個值、父進程返回一個值。在程序代碼中,可通過返回值來區分是子進程還是父進程。
fork()調用成功后,將會在父進程中返回子進程的PID,而在子進程中返回值是0;如果調用失敗,父進程返回值-1,不創建子進程,并設置errno。
fork()調用成功后,子進程和父進程會繼續執行fork()調用之后的指令,子進程、父進程各自在自己的進程空間中運行。事實上,子進程是父進程的一個副本,譬如子進程拷貝了父進程的數據段、堆、棧以及繼承了父進程打開的文件描述符,父進程與子進程并不共享這些存儲空間,這是子進程對父進程相應部分存儲空間的完全復制,執行fork()之后,每個進程均可修改各自的棧數據以及堆段中的變量,而并不影響另一個進程。
雖然子進程是父進程的一個副本,但是對于程序代碼段(文本段)來說,兩個進程執行相同的代碼段,因為代碼段是只讀的,也就是說父子進程共享代碼段,在內存中只存在一份代碼段數據。
使用示例1
使用fork()創建子進程。
示例代碼 10.5.1 fork()使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{pid_t pid;pid = fork();switch (pid) {case -1:perror("fork error");exit(-1);case 0:printf("這是子進程打印信息<pid: %d, 父進程pid: %d>\n",getpid(), getppid());_exit(0); //子進程使用_exit()退出default:printf("這是父進程打印信息<pid: %d, 子進程pid: %d>\n",getpid(), pid);exit(0);}
}
上述示例代碼中,case 0是子進程的分支,這里使用了_exit()結束進程而沒有使用exit()。
Tips:C庫函數exit()建立在系統調用_exit()之上,這兩個函數在3.3小節中向大家介紹過,這里我們強調,在調用了fork()之后,父、子進程中一般只有一個會通過調用exit()退出進程,而另一個則應使用_exit()退出,具體原因將會在后面章節內容中向大家做進一步說明!
直接測試運行查看打印結果:

圖 10.5.1 測試結果
從打印結果可知,fork()之后的語句被執行了兩次,所以switch…case語句被執行了兩次,第一次進入到了"case 0"分支,通過上面的介紹可知,fork()返回值為0表示當前處于子進程;在子進程中我們通過getpid()獲取到子進程自己的PID(46802),通過getppid()獲取到父進程的PID(46803),將其打印出來。
第二次進入到了default分支,表示當前處于父進程,此時fork()函數的返回值便是創建出來的子進程對應的PID。
fork()函數調用完成之后,父進程、子進程會各自繼續執行fork()之后的指令,最終父進程會執行到exit()結束進程,而子進程則會通過_exit()結束進程。
使用示例2
示例代碼 10.5.2 fork()函數使用示例2
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{pid_t pid;pid = fork();switch (pid) {case -1:perror("fork error");exit(-1);case 0:printf("這是子進程打印信息\n");printf("%d\n", pid);_exit(0);default:printf("這是父進程打印信息\n");printf("%d\n", pid);exit(0);}
}
運行結果:

圖 10.5.2 測試結果
在exit()函數之前添加了打印信息,而從上圖中可以知道,打印的pid值并不相同,0表示子進程打印出來的,46953表示的是父進程打印出來的,所以從這里可以證實,fork()函數調用完成之后,父進程、子進程會各自繼續執行fork()之后的指令,它們共享代碼段,但并不共享數據段、堆、棧等,而是子進程擁有父進程數據段、堆、棧等副本,所以對于同一個局部變量,它們打印出來的值是不相同的,因為fork()調用返回值不同,在父、子進程中賦予了pid不同的值。
關于子進程
子進程被創建出來之后,便是一個獨立的進程,擁有自己獨立的進程空間,系統內唯一的進程號,擁有自己獨立的PCB(進程控制塊),子進程會被內核同等調度執行,參與到系統的進程調度中。
子進程與父進程之間的這種關系被稱為父子進程關系,父子進程關系相比于普通的進程間關系多多少少存在一些關聯與“羈絆”,關于這些關聯與“羈絆”我們將會在后面的課程中為大家介紹。
Tips:系統調度。Linux系統是一個多任務、多進程、多線程的操作系統,一般來說系統啟動之后會運行成百甚至上千個不同的進程,那么對于單核CPU計算機來說,在某一個時間它只能運行某一個進程的代碼指令,那其它進程怎么辦呢(多核處理器也是如此,同一時間每個核它只能運行某一個進程的代碼)?這里就出現了調度的問題,系統是這樣做的,每一個進程(或線程)執行一段固定的時間,時間到了之后切換執行下一個進程或線程,依次輪流執行,這就稱為調度,由操作系統負責這件事情,當然系統調度的實現本身是一件非常復雜的事情,需要考慮的因素很多,這里只是讓大家有個簡單地認識,系統調度的基本單元是線程,關于線程,后面章節內容將會向大家介紹。
10.6父、子進程間的文件共享
調用fork()函數之后,子進程會獲得父進程所有文件描述符的副本,這些副本的創建方式類似于dup(),這也意味著父、子進程對應的文件描述符均指向相同的文件表,如下圖所示:

圖 10.6.1 父、子進程間的文件共享
由此可知,子進程拷貝了父進程的文件描述符表,使得父、子進程中對應的文件描述符指向了相同的文件表,也意味著父、子進程中對應的文件描述符指向了磁盤中相同的文件,因而這些文件在父、子進程間實現了共享,譬如,如果子進程更新了文件偏移量,那么這個改變也會影響到父進程中相應文件描述符的位置偏移量。
接下來我們進行一個測試,父進程打開文件之后,然后fork()創建子進程,此時子進程繼承了父進程打開的文件描述符(父進程文件描述符的副本),然后父、子進程同時對文件進行寫入操作,測試代碼如下所示:
示例代碼 10.6.1 子進程繼承父進程文件描述符實現文件共享
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{pid_t pid;int fd;int i;fd = open("./test.txt", O_RDWR | O_TRUNC);if (0 > fd) {perror("open error");exit(-1);}pid = fork();switch (pid) {case -1:perror("fork error");close(fd);exit(-1);case 0:/* 子進程 */for (i = 0; i < 4; i++) //循環寫入4次write(fd, "1122", 4);close(fd);_exit(0);default:/* 父進程 */for (i = 0; i < 4; i++) //循環寫入4次write(fd, "AABB", 4);close(fd);exit(0);}
}
上述代碼中,父進程open打開文件之后,才調用fork()創建了子進程,所以子進程了繼承了父進程打開的文件描述符fd,我們需要驗證的便是兩個進程對文件的寫入操作是分別各自寫入、還是每次都在文件末尾接續寫入。
運行測試:
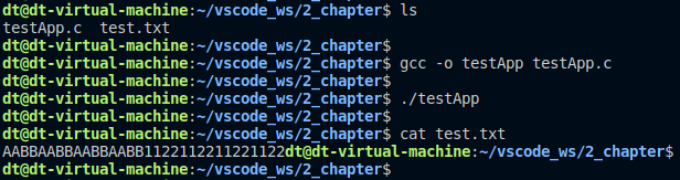
圖 10.6.2 測試結果
有上述測試結果可知,此種情況下,父、子進程分別對同一個文件進行寫入操作,結果是接續寫,不管是父進程,還是子進程,在每次寫入時都是從文件的末尾寫入,很像使用了O_APPEND標志的效果。其原因也非常簡單,圖 9.6.1中便給出了答案,子進程繼承了父進程的文件描述符,兩個文件描述符都指向了一個相同的文件表,意味著它們的文件偏移量是同一個、綁定在了一起,相互影響,子進程改變了文件的位置偏移量就會作用到父進程,同理,父進程改變了文件的位置偏移量就會作用到子進程。
再來測試另外一種情況,父進程在調用fork()之后,此時父進程和子進程都去打開同一個文件,然后再對文件進行寫入操作,測試代碼如下:
示例代碼 10.6.2 父、子各自打開同一個文件實現文件共享
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main(void)
{pid_t pid;int fd;int i;pid = fork();switch (pid) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */fd = open("./test.txt", O_WRONLY);if (0 > fd) {perror("open error");_exit(-1);}for (i = 0; i < 4; i++) //循環寫入4次write(fd, "1122", 4);close(fd);_exit(0);default:/* 父進程 */fd = open("./test.txt", O_WRONLY);if (0 > fd) {perror("open error");exit(-1);}for (i = 0; i < 4; i++) //循環寫入4次write(fd, "AABB", 4);close(fd);exit(0);}
}
在上述示例中,父進程調用fork()之后,然后在父、子進程中都去打開test.txt文件,然后在對其進行寫入操作,子進程調用了4次write、每次寫入“1122”;而父進程調用了4次write、每次寫入“AABB”,測試結果如下:

圖 10.6.3 測試結果
從測試結果可知,這種文件共享方式實現的是一種兩個進程分別各自對文件進行寫入操作,因為父、子進程的這兩個文件描述符分別指向的是不同的文件表,意味著它們有各自的文件偏移量,一個進程修改了文件偏移量并不會影響另一個進程的文件偏移量,所以寫入的數據會出現覆蓋的情況。
fork()函數使用場景
fork()函數有以下兩種用法:
?父進程希望子進程復制自己,使父進程和子進程同時執行不同的代碼段。這在網絡服務進程中是常見的,父進程等待客戶端的服務請求,當接收到客戶端發送的請求事件后,調用fork()創建一個子進程,使子進程去處理此請求、而父進程可以繼續等待下一個服務請求。
?一個進程要執行不同的程序。譬如在程序app1中調用fork()函數創建了子進程,此時子進程是要去執行另一個程序app2,也就是子進程需要執行的代碼是app2程序對應的代碼,子進程將從app2程序的main函數開始運行。這種情況,通常在子進程從fork()函數返回之后立即調用exec族函數來實現,關于exec函數將在后面內容向大家介紹。
10.7系統調用vfork()
除了fork()系統調用之外,Linux系統還提供了vfork()系統調用用于創建子進程,vfork()與fork()函數在功能上是相同的,并且返回值也相同,在一些細節上存在區別,vfork()函數原型如下所示:
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
使用該函數需要包含頭文件<sys/types.h>和<unistd.h>。
從前面的介紹可知,可以將fork()認作對父進程的數據段、堆段、棧段以及其它一些數據結構創建拷貝,由此可以看出,使用fork()系統調用的代價是很大的,它復制了父進程中的數據段和堆棧段中的絕大部分內容,這將會消耗比較多的時間,效率會有所降低,而且太浪費,原因有很多,其中之一在于,fork()函數之后子進程通常會調用exec函數,也就是fork()第二種使用場景下,這使得子進程不再執行父程序中的代碼段,而是執行新程序的代碼段,從新程序的main函數開始執行、并為新程序重新初始化其數據段、堆段、棧段等;那么在這種情況下,子進程并不需要用到父進程的數據段、堆段、棧段(譬如父程序中定義的局部變量、全局變量等)中的數據,此時就會導致浪費時間、效率降低。
事實上,現代Linux系統采用了一些技術來避免這種浪費,其中很重要的一點就是內核采用了寫時復制(copy-on-write)技術,關于這種技術的實現細節就不給大家介紹了,有興趣讀者可以自己搜索相應的文檔了解。
出于這一原因,引入了vfork()系統調用,雖然在一些細節上有所不同,但其效率要高于fork()函數。類似于fork(),vfork()可以為調用該函數的進程創建一個新的子進程,然而,vfork()是為子進程立即執行exec()新的程序而專門設計的,也就是fork()函數的第二個使用場景。
vfork()與fork()函數主要有以下兩個區別:
?vfork()與fork()一樣都創建了子進程,但vfork()函數并不會將父進程的地址空間完全復制到子進程中,因為子進程會立即調用exec(或_exit),于是也就不會引用該地址空間的數據。不過在子進程調用exec或_exit之前,它在父進程的空間中運行、子進程共享父進程的內存。這種優化工作方式的實現提高的效率;但如果子進程修改了父進程的數據(除了vfork返回值的變量)、進行了函數調用、或者沒有調用exec或_exit就返回將可能帶來未知的結果。
?另一個區別在于,vfork()保證子進程先運行,子進程調用exec之后父進程才可能被調度運行。
雖然vfork()系統調用在效率上要優于fork(),但是vfork()可能會導致一些難以察覺的程序bug,所以盡量避免使用vfork()來創建子進程,雖然fork()在效率上并沒有vfork()高,但是現代的Linux系統內核已經采用了寫時復制技術來實現fork(),其效率較之于早期的fork()實現要高出許多,除非速度絕對重要的場合,我們的程序當中應舍棄vfork()而使用fork()。
使用示例
示例代碼 10.7.1 vfork()函數使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>int main(void)
{pid_t pid;int num = 100;pid = vfork();switch (pid) {case -1:perror("vfork error");exit(-1);case 0:/* 子進程 */printf("子進程打印信息\n");printf("子進程打印num: %d\n", num);_exit(0);default:/* 父進程 */printf("父進程打印信息\n");printf("父進程打印num: %d\n", num);exit(0);}
}
測試結果:
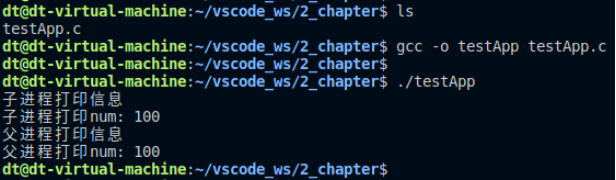
圖 10.7.1 測試結果
在正式的使用場合下,一般應在子進程中立即調用exec,如果exec調用失敗,子進程則應調用_exit()退出(vfork產生的子進程不應調用exit退出,因為這會導致對父進程stdio緩沖區的刷新和關閉)。上述示例代碼只是一個簡單地演示,并不是vfork()的真正用法,后面學習到exec的時候還會再給大家進行介紹。
10.8fork()之后的競爭條件
調用fork()之后,子進程成為了一個獨立的進程,可被系統調度運行,而父進程也繼續被系統調度運行,這里出現了一個問題,調用fork之后,無法確定父、子兩個進程誰將率先訪問CPU,也就是說無法確認誰先被系統調用運行(在多核處理器中,它們可能會同時各自訪問一個CPU),這將導致誰先運行、誰后運行這個順序是不確定的,譬如有如下示例代碼:
示例代碼 10.8.1 fork()競爭條件測試代碼
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程打印信息\n");_exit(0);default:/* 父進程 */printf("父進程打印信息\n");exit(0);}
}
示例代碼中我們是無法確認"子進程打印信息"和"父進程打印信息"誰先會被打印出來,有時子進程先被執行,打印出"子進程打印信息",而有時父進程會先被執行,打印出"子進程打印信息",測試結果如下所示:

圖 10.8.1 測試結果
從測試結果可知,雖然絕大部分情況下,父進程會先于子進程被執行,但是并不排除子進程先于父進程被執行的可能性。而對于有些特定的應用程序,它對于執行的順序有一定要求的,譬如它必須要求父進程先運行,或者必須要求子進程先運行,程序產生正確的結果它依賴于特定的執行順序,那么將可能因競爭條件而導致失敗、無法得到正確的結果。
那如何明確保證某一特性執行順序呢?這個時候可以通過采用采用某種同步技術來實現,譬如前面給大家介紹的信號,如果要讓子進程先運行,則可使父進程被阻塞,等到子進程來喚醒它,示例代碼如下所示:
示例代碼 10.8.2 利用信號來調整進程間動作
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>static void sig_handler(int sig)
{printf("接收到信號\n");
}int main(void)
{struct sigaction sig = {0};sigset_t wait_mask;/* 初始化信號集 */sigemptyset(&wait_mask);/* 設置信號處理方式 */sig.sa_handler = sig_handler;sig.sa_flags = 0;if (-1 == sigaction(SIGUSR1, &sig, NULL)) {perror("sigaction error");exit(-1);}switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程開始執行\n");printf("子進程打印信息\n");printf("~~~~~~~~~~~~~~~\n");sleep(2);kill(getppid(), SIGUSR1); //發送信號給父進程、喚醒它_exit(0);default:/* 父進程 */if (-1 != sigsuspend(&wait_mask))//掛起、阻塞exit(-1);printf("父進程開始執行\n");printf("父進程打印信息\n");exit(0);}
}
示例代碼比較簡單,這里我們希望子進程先運行打印相應信息,之后再執行父進程打印信息,在父進程分支中,直接調用了sigsuspend()使父進程進入掛起狀態,由子進程通過kill命令發送信號喚醒,測試結果如下:

圖 10.8.2 測試結果
10.9進程的誕生與終止
10.9.1進程的誕生
一個進程可以通過fork()或vfork()等系統調用創建一個子進程,一個新的進程就此誕生!事實上,Linux系統下的所有進程都是由其父進程創建而來,譬如在shell終端通過命令的方式執行一個程序./app,那么app進程就是由shell終端進程創建出來的,shell終端就是該進程的父進程。
既然所有進程都是由其父進程創建出來的,那么總有一個最原始的父進程吧,否則其它進程是怎么創建出來的呢?確實如此,在Ubuntu系統下使用"ps -aux"命令可以查看到系統下所有進程信息,如下:

圖 10.9.1 查看所有進程信息
上圖中進程號為1的進程便是所有進程的父進程,通常稱為init進程,它是Linux系統啟動之后運行的第一個進程,它管理著系統上所有其它進程,init進程是由內核啟動,因此理論上說它沒有父進程。
init進程的PID總是為1,它是所有子進程的父進程,一切從1開始、一切從init進程開始!
一個進程的生命周期便是從創建開始直至其終止。
10.9.2進程的終止
通常,進程有兩種終止方式:異常終止和正常終止,分別在3.3小節和8.11小節中給大家介紹過,如前所述,進程的正常終止有多種不同的方式,譬如在main函數中使用return返回、調用exit()函數結束進程、調用_exit()或_Exit()函數結束進程等。
異常終止通常也有多種不同的方式,譬如在程序當中調用abort()函數異常終止進程、當進程接收到某些信號導致異常終止等。
_exit()函數和exit()函數的status參數定義了進程的終止狀態(termination status),父進程可以調用wait()函數以獲取該狀態。雖然參數status定義為int類型,但僅有低8位表示它的終止狀態,一般來說,終止狀態為0表示進程成功終止,而非0值則表示進程在執行過程中出現了一些錯誤而終止,譬如文件打開失敗、讀寫失敗等等,對非0返回值的解析并無定例。
在我們的程序當中,一般使用exit()庫函數而非_exit()系統調用,原因在于exit()最終也會通過_exit()終止進程,但在此之前,它將會完成一些其它的工作,exit()函數會執行的動作如下:
?如果程序中注冊了進程終止處理函數,那么會調用終止處理函數。在9.1.2小節給大家介紹如何注冊進程的終止處理函數;
?刷新stdio流緩沖區。關于stdio流緩沖區的問題,稍后編寫一個簡單地測試程序進行說明;
?執行_exit()系統調用。
所以,由此可知,exit()函數會比_exit()會多做一些事情,包括執行終止處理函數、刷新stdio流緩沖以及調用_exit(),在前面曾提到過,在我們的程序當中,父、子進程不應都使用exit()終止,只能有一個進程使用exit()、而另一個則使用_exit()退出,當然一般推薦的是子進程使用_exit()退出、而父進程則使用exit()退出。其原因就在于調用exit()函數終止進程時會刷新進程的stdio緩沖區。接下來我們便通過一個示例代碼進行說明:
示例代碼 10.9.1 exit()之stdio緩沖測試代碼1
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{printf("Hello World!\n");switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */exit(0);default:/* 父進程 */exit(0);}
}
在上述代碼中,在fork()創建子進程之前,我們通過printf()打印了一行包括換行符\n在內字符串,在fork()創建子進程之后,都使用exit()退出進程,正常的情況下程序就只會打印一行"Hello World!",這是一個正常的情況,事實上也確實如此,如下所示:
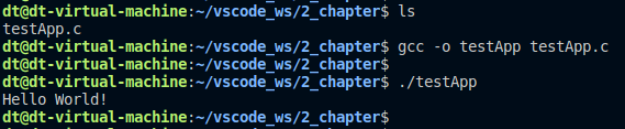
圖 10.9.2 測試結果
打印結果確實如我們所料,接下來將代碼進行簡單地修改,把printf()打印的字符串最后面的換行符\n去掉,如下所示:
示例代碼 10.9.2 exit()之stdio緩沖測試代碼2
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{printf("Hello World!");switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */exit(0);default:/* 父進程 */exit(0);}
}
printf中將字符串后面的\n換行符給去掉了,接下再進行測試,結果如下:
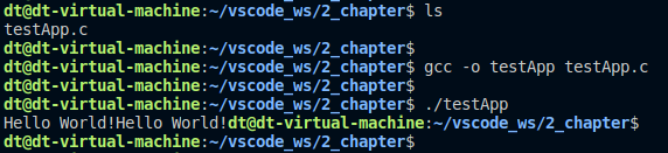
圖 10.9.3 測試結果
從打印結果可知,"Hello World!"被打印了兩次,這是怎么回事呢?在程序當中明明只使用了printf打印了一次字符串。要解釋這個問題,首先要知道,進程的用戶空間內存中維護了stdio緩沖區,4.9小節給大家介紹過,因此通過fork()創建子進程時會復制這些緩沖區。標準輸出設備默認使用的是行緩沖,當檢測到換行符\n時會立即顯示函數printf()輸出的字符串,在示例代碼 9.9.1中printf輸出的字符串中包含了換行符,所以會立即讀走緩沖區中的數據并顯示,讀走之后此時緩沖區就空了,子進程雖然拷貝了父進程的緩沖區,但是空的,雖然父、子進程使用exit()退出時會刷新各自的緩沖區,但對于空緩沖區自然無數據可讀。
而對于示例代碼 9.9.2來說,printf()并沒有添加換行符\n,當調用printf()時并不會立即讀取緩沖區中的數據進行顯示,由此fork()之后創建的子進程也自然拷貝了緩沖區的數據,當它們調用exit()函數時,都會刷新各自的緩沖區、顯示字符串,所以就會看到打印出了兩次相同的字符串。
可以采用以下任一方法來避免重復的輸出結果:
?對于行緩沖設備,可以加上對應換行符,譬如printf打印輸出字符串時在字符串后面添加\n換行符,對于puts()函數來說,本身會自動添加換行符;
?在調用fork()之前,使用函數fflush()來刷新stdio緩沖區,當然,作為另一種選擇,也可以使用setvbuf()和setbuf()來關閉stdio流的緩沖功能,這些內容在第四章中已經給大家介紹過;
?子進程調用_exit()退出進程、而非使用exit(),調用_exit()在退出時便不會刷新stdio緩沖區,這也解釋前面為什么我們要在子進程中使用_exit()退出這樣做的一個原因。將示例代碼 9.9.2中子進程的退出操作exit()替換成_exit()進行測試,打印的結果便只會顯示一次字符串,大家自己動手試一試!
關于本小節的內容,到這里就結束了,雖然筆者覺得自己已經介紹得很詳細了,如果大家覺得還有不懂的地方,可以自己編寫程序進行測試、驗證,編程是一門動手實踐性很強的工作,大家要善于從中發現一些問題,然后自己能夠編寫程序進行測試、驗證,大家加油!
10.10監視子進程
在很多應用程序的設計中,父進程需要知道子進程于何時被終止,并且需要知道子進程的終止狀態信息,是正常終止、還是異常終止亦或者被信號終止等,意味著父進程會對子進程進行監視,本小節我們就來學習下如何通過系統調用wait()以及其它變體來監視子進程的狀態改變。
10.10.1wait()函數
對于許多需要創建子進程的進程來說,有時設計需要監視子進程的終止時間以及終止時的一些狀態信息,在某些設計需求下這是很有必要的。系統調用wait()可以等待進程的任一子進程終止,同時獲取子進程的終止狀態信息,其函數原型如下所示:
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
使用該函數需要包含頭文件<sys/types.h>和<sys/wait.h>。
函數參數和返回值含義如下:
status:參數status用于存放子進程終止時的狀態信息,參數status可以為NULL,表示不接收子進程終止時的狀態信息。
返回值:若成功則返回終止的子進程對應的進程號;失敗則返回-1。
系統調用wait()將執行如下動作:
?調用wait()函數,如果其所有子進程都還在運行,則wait()會一直阻塞等待,直到某一個子進程終止;
?如果進程調用wait(),但是該進程并沒有子進程,也就意味著該進程并沒有需要等待的子進程,那么wait()將返回錯誤,也就是返回-1、并且會將errno設置為ECHILD。
?如果進程調用wait()之前,它的子進程當中已經有一個或多個子進程已經終止了,那么調用wait()也不會阻塞。wait()函數的作用除了獲取子進程的終止狀態信息之外,更重要的一點,就是回收子進程的一些資源,俗稱為子進程“收尸”,關于這個問題后面再給大家進行介紹。所以在調用wait()函數之前,已經有子進程終止了,意味著正等待著父進程為其“收尸”,所以調用wait()將不會阻塞,而是會立即替該子進程“收尸”、處理它的“后事”,然后返回到正常的程序流程中,一次wait()調用只能處理一次。
參數status不為NULL的情況下,則wait()會將子進程的終止時的狀態信息存儲在它指向的int變量中,可以通過以下宏來檢查status參數:
?WIFEXITED(status):如果子進程正常終止,則返回true;
?WEXITSTATUS(status):返回子進程退出狀態,是一個數值,其實就是子進程調用_exit()或exit()時指定的退出狀態;wait()獲取得到的status參數并不是調用_exit()或exit()時指定的狀態,可通過WEXITSTATUS宏轉換;
?WIFSIGNALED(status):如果子進程被信號終止,則返回true;
?WTERMSIG(status):返回導致子進程終止的信號編號。如果子進程是被信號所終止,則可以通過此宏獲取終止子進程的信號;
?WCOREDUMP(status):如果子進程終止時產生了核心轉儲文件,則返回true;
還有一些其它的宏定義,這里就不給一一介紹了,具體的請查看man手冊。
使用示例
示例代碼 10.10.1 wait()函數使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <errno.h>int main(void)
{int status;int ret;int i;/* 循環創建3個子進程 */for (i = 1; i <= 3; i++) {switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程<%d>被創建\n", getpid());sleep(i);_exit(i);default:/* 父進程 */break;}}sleep(1);printf("~~~~~~~~~~~~~~\n");for (i = 1; i <= 3; i++) {ret = wait(&status);if (-1 == ret) {if (ECHILD == errno) {printf("沒有需要等待回收的子進程\n");exit(0);}else {perror("wait error");exit(-1);}}printf("回收子進程<%d>, 終止狀態<%d>\n", ret,WEXITSTATUS(status));}exit(0);
}
示例代碼中,通過for循環創建了3個子進程,父進程中循環調用wait()函數等待回收子進程,并將本次回收的子進程進程號以及終止狀態打印出來,編譯測試結果如下:

圖 10.10.1 測試結果
10.10.2waitpid()函數
使用wait()系統調用存在著一些限制,這些限制包括如下:
?如果父進程創建了多個子進程,使用wait()將無法等待某個特定的子進程的完成,只能按照順序等待下一個子進程的終止,一個一個來、誰先終止就先處理誰;
?如果子進程沒有終止,正在運行,那么wait()總是保持阻塞,有時我們希望執行非阻塞等待,是否有子進程終止,通過判斷即可得知;
?使用wait()只能發現那些被終止的子進程,對于子進程因某個信號(譬如SIGSTOP信號)而停止(注意,這里停止指的暫停運行),或是已停止的子進程收到SIGCONT信號后恢復執行的情況就無能為力了。
而設計waitpid()則可以突破這些限制,waitpid()系統調用函數原型如下所示:
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
使用該函數需要包含頭文件<sys/types.h>和<sys/wait.h>。
函數參數和返回值含義如下:
pid:參數pid用于表示需要等待的某個具體子進程,關于參數pid的取值范圍如下:
?如果pid大于0,表示等待進程號為pid的子進程;
?如果pid等于0,則等待與調用進程(父進程)同一個進程組的所有子進程;
?如果pid小于-1,則會等待進程組標識符與pid絕對值相等的所有子進程;
?如果pid等于-1,則等待任意子進程。wait(&status)與waitpid(-1, &status, 0)等價。
status:與wait()函數的status參數意義相同。
options:稍后介紹。
返回值:返回值與wait()函數的返回值意義基本相同,在參數options包含了WNOHANG標志的情況下,返回值會出現0,稍后介紹。
參數options是一個位掩碼,可以包括0個或多個如下標志:
?WNOHANG:如果子進程沒有發生狀態改變(終止、暫停),則立即返回,也就是執行非阻塞等待,可以實現輪訓poll,通過返回值可以判斷是否有子進程發生狀態改變,若返回值等于0表示沒有發生改變。
?WUNTRACED:除了返回終止的子進程的狀態信息外,還返回因信號而停止(暫停運行)的子進程狀態信息;
?WCONTINUED:返回那些因收到SIGCONT信號而恢復運行的子進程的狀態信息。
從以上的介紹可知,waitpid()在功能上要強于wait()函數,它彌補了wait()函數所帶來的一些限制,具體在實際的編程使用當中,可根據自己的需求進行選擇。
使用示例
使用waitpid()替換wait(),改寫示例代碼 9.10.1。
示例代碼 10.10.2 waitpid()阻塞方式
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <errno.h>int main(void)
{int status;int ret;int i;/* 循環創建3個子進程 */for (i = 1; i <= 3; i++) {switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程<%d>被創建\n", getpid());sleep(i);_exit(i);default:/* 父進程 */break;}}sleep(1);printf("~~~~~~~~~~~~~~\n");for (i = 1; i <= 3; i++) {ret = waitpid(-1, &status, 0);if (-1 == ret) {if (ECHILD == errno) {printf("沒有需要等待回收的子進程\n");exit(0);}else {perror("wait error");exit(-1);}}printf("回收子進程<%d>, 終止狀態<%d>\n", ret,WEXITSTATUS(status));}exit(0);
}
將wait(&status)替換成了waitpid(-1, &status, 0),通過上面的介紹可知,waitpid()函數的這種參數配置情況與wait()函數是完全等價的,運行結果與示例代碼 9.10.1運行結果相同,這里不再演示!
將上述代碼進行簡單修改,將其修改成輪訓方式,如下所示:
示例代碼 10.10.3 waitpid()輪訓方式
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <errno.h>int main(void)
{int status;int ret;int i;/* 循環創建3個子進程 */for (i = 1; i <= 3; i++) {switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程<%d>被創建\n", getpid());sleep(i);_exit(i);default:/* 父進程 */break;}}sleep(1);printf("~~~~~~~~~~~~~~\n");for ( ; ; ) {ret = waitpid(-1, &status, WNOHANG);if (0 > ret) {if (ECHILD == errno)exit(0);else {perror("wait error");exit(-1);}}else if (0 == ret)continue;elseprintf("回收子進程<%d>, 終止狀態<%d>\n", ret,WEXITSTATUS(status));}exit(0);
}
將waitpid()函數的options參數添加WNOHANG標志,將waitpid()配置成非阻塞模式,使用輪訓的方式依次回收各個子進程,測試結果如下:

圖 10.10.2 測試結果
10.10.3waitid()函數
除了以上給大家介紹的wait()和waitpid()系統調用之外,還有一個waitid()系統調用,waitid()與waitpid()類似,不過waitid()提供了更多的擴展功能,具體的使用方法筆者便不再介紹,大家有興趣可以自己通過man進行學習。
10.10.4僵尸進程與孤兒進程
當一個進程創建子進程之后,它們倆就成為父子進程關系,父進程與子進程的生命周期往往是不相同的,這里就會出現兩個問題:
?父進程先于子進程結束。
?子進程先于父進程結束。
本小節我們就來討論下這兩種不同的情況。
孤兒進程
父進程先于子進程結束,也就是意味著,此時子進程變成了一個“孤兒”,我們把這種進程就稱為孤兒進程。在Linux系統當中,所有的孤兒進程都自動成為init進程(進程號為1)的子進程,換言之,某一子進程的父進程結束后,該子進程調用getppid()將返回1,init進程變成了孤兒進程的“養父”;這是判定某一子進程的“生父”是否還“在世”的方法之一,通過下面的代碼進行測試:
示例代碼 10.10.4 孤兒進程測試
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{/* 創建子進程 */switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程<%d>被創建, 父進程<%d>\n", getpid(), getppid());sleep(3); //休眠3秒鐘等父進程結束printf("父進程<%d>\n", getppid());//再次獲取父進程pid_exit(0);default:/* 父進程 */break;}sleep(1);//休眠1秒printf("父進程結束!\n");exit(0);
}
在上述代碼中,子進程休眠3秒鐘,保證父進程先結束,而父進程休眠1秒鐘,保證子進程能夠打印出第一個printf(),也就是在父進程結束前,打印子進程的父進程進程號;子進程3秒休眠時間過后,再次打印父進程的進程號,此時它的“生父”已經結束了。
我們來看看打印結果:

圖 10.10.3 測試結果
可以發現,打印結果并不是1,意味著并不是init進程,而是1911,這是怎么回事呢?通過"ps -axu"查詢可知,進程號1911對應的是upstart進程,如下所示:

圖 10.10.4 upstart進程
事實上,/sbin/upstart進程與Ubuntu系統圖形化界面有關系,是圖形化界面下的一個后臺守護進程,可負責“收養”孤兒進程,所以圖形化界面下,upstart進程就自動成為了孤兒進程的父進程,這里筆者是在Ubuntu 16.04版本下進行的測試,可能不同的版本這里看到的結果會有不同。
既然在圖形化界面下孤兒進程的父進程不是init進程,那么我們進入Ubuntu字符界面,按Ctrl + Alt + F1進入,如下所示:

圖 10.10.5 Ubuntu字符界面
輸入Linux用戶名和密碼登錄,我們在運行一次:

圖 10.10.6 測試結果
字符界面模式下無法顯示中文,所以出現了很多白色小方塊,從打印結果可以發現,此時孤兒進程的父進程就成了init進程,大家可以自己測試下,按Ctrl + Alt + F7回到Ubuntu圖形化界面。
僵尸進程
進程結束之后,通常需要其父進程為其“收尸”,回收子進程占用的一些內存資源,父進程通過調用wait()(或其變體waitpid()、waitid()等)函數回收子進程資源,歸還給系統。
如果子進程先于父進程結束,此時父進程還未來得及給子進程“收尸”,那么此時子進程就變成了一個僵尸進程。子進程結束后其父進程并沒有來得及立馬給它“收尸”,子進程處于“曝尸荒野”的狀態,在這么一個狀態下,我們就將子進程成為僵尸進程;至于名字由來,肯定是對電影情節的一種效仿!
當父進程調用wait()(或其變體,下文不再強調)為子進程“收尸”后,僵尸進程就會被內核徹底刪除。另外一種情況,如果父進程并沒有調用wait()函數然后就退出了,那么此時init進程將會接管它的子進程并自動調用wait(),故而從系統中移除僵尸進程。
如果父進程創建了某一子進程,子進程已經結束,而父進程還在正常運行,但父進程并未調用wait()回收子進程,此時子進程變成一個僵尸進程。首先來說,這樣的程序設計是有問題的,如果系統中存在大量的僵尸進程,它們勢必會填滿內核進程表,從而阻礙新進程的創建。需要注意的是,僵尸進程是無法通過信號將其殺死的,即使是“一擊必殺”信號SIGKILL也無法將其殺死,那么這種情況下,只能殺死僵尸進程的父進程(或等待其父進程終止),這樣init進程將會接管這些僵尸進程,從而將它們從系統中清理掉!所以,在我們的一個程序設計中,一定要監視子進程的狀態變化,如果子進程終止了,要調用wait()將其回收,避免僵尸進程。
示例代碼
編寫示例代碼,產生一個僵尸進程。
示例代碼 10.10.5 產生僵尸進程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{/* 創建子進程 */switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程<%d>被創建\n", getpid());sleep(1);printf("子進程結束\n");_exit(0);default:/* 父進程 */break;}for ( ; ; )sleep(1);exit(0);
}
在上述代碼中,子進程已經退出,但其父進程并沒調用wait()為其“收尸”,使得子進程成為一個僵尸進程,使用命令"ps -aux"可以查看到該僵尸進程,測試結果如下:
圖 10.10.7 測試結果
通過命令可以查看到子進程113456依然存在,可以看到它的狀態欄顯示的是“Z”(zombie,僵尸),表示它是一個僵尸進程。僵尸進程無法被信號殺死,大家可以試試,要么等待其父進程終止、要么殺死其父進程,讓init進程來處理,當我們殺死其父進程之后,僵尸進程也會被隨之清理。
10.10.5SIGCHLD信號
SIGCHLD信號在第八章中給大家介紹過,當發生以下兩種情況時,父進程會收到該信號:
?當父進程的某個子進程終止時,父進程會收到SIGCHLD信號;
?當父進程的某個子進程因收到信號而停止(暫停運行)或恢復時,內核也可能向父進程發送該信號。
子進程的終止屬于異步事件,父進程事先是無法預知的,如果父進程有自己需要做的事情,它不能一直wait()阻塞等待子進程終止(或輪訓),這樣父進程將啥事也做不了,那么有什么辦法來解決這樣的尷尬情況,當然有辦法,那就是通過SIGCHLD信號。
那既然子進程狀態改變時(終止、暫停或恢復),父進程會收到SIGCHLD信號,SIGCHLD信號的系統默認處理方式是將其忽略,所以我們要捕獲它、綁定信號處理函數,在信號處理函數中調用wait()收回子進程,回收完畢之后再回到父進程自己的工作流程中。
不過,使用這一方式時需要掌握一些竅門!
由8.4.1和8.4.2小節的介紹可知,當調用信號處理函數時,會暫時將引發調用的信號添加到進程的信號掩碼中(除非sigaction()指定了SA_NODEFER標志),這樣一來,當SIGCHLD信號處理函數正在為一個終止的子進程“收尸”時,如果相繼有兩個子進程終止,即使產生了兩次SIGCHLD信號,父進程也只能捕獲到一次SIGCHLD信號,結果是,父進程的SIGCHLD信號處理函數每次只調用一次wait(),那么就會導致有些僵尸進程成為“漏網之魚”。
解決方案就是:在SIGCHLD信號處理函數中循環以非阻塞方式來調用waitpid(),直至再無其它終止的子進程需要處理為止,所以,通常SIGCHLD信號處理函數內部代碼如下所示:
while (waitpid(-1, NULL, WNOHANG) > 0)
continue;
上述代碼一直循環下去,直至waitpid()返回0,表明再無僵尸進程存在;或者返回-1,表明有錯誤發生。應在創建任何子進程之前,為SIGCHLD信號綁定處理函數。
使用示例
通過SIGCHLD信號實現異步方式監視子進程。
示例代碼 10.10.6 異步方式監視wait回收子進程
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>static void wait_child(int sig)
{/* 替子進程收尸 */printf("父進程回收子進程\n");while (waitpid(-1, NULL, WNOHANG) > 0)continue;
}int main(void)
{struct sigaction sig = {0};/* 為SIGCHLD信號綁定處理函數 */sigemptyset(sig.sa_mask);sig.sa_handler = wait_child;sig.sa_flags = 0;if (-1 == sigaction(SIGCHLD, &sig, NULL)) {perror("sigaction error");exit(-1);}/* 創建子進程 */switch (fork()) {case -1:perror("fork error");exit(-1);case 0:/* 子進程 */printf("子進程<%d>被創建\n", getpid());sleep(1);printf("子進程結束\n");_exit(0);default:/* 父進程 */break;}sleep(3);exit(0);
}
運行結果如下:

圖 10.10.8 測試結果
10.11執行新程序
在前面已經大家提到了exec函數,當子進程的工作不再是運行父進程的代碼段,而是運行另一個新程序的代碼,那么這個時候子進程可以通過exec函數來實現運行另一個新的程序。本小節我們就來學習下,如何在程序中運行一個新的程序,從新程序的main()函數開始運行。
10.11.1execve()函數
系統調用execve()可以將新程序加載到某一進程的內存空間,通過調用execve()函數將一個外部的可執行文件加載到進程的內存空間運行,使用新的程序替換舊的程序,而進程的棧、數據、以及堆數據會被新程序的相應部件所替換,然后從新程序的main()函數開始執行。
execve()函數原型如下所示:
#include <unistd.h>
int execve(const char *filename, char *const argv[], char *const envp[]);
使用該函數需要包含頭文件<unistd.h>。
函數參數和返回值含義如下:
filename:參數filename指向需要載入當前進程空間的新程序的路徑名,既可以是絕對路徑、也可以是相對路徑。
argv:參數argv則指定了傳遞給新程序的命令行參數。是一個字符串數組,該數組對應于main(int argc, char *argv[])函數的第二個參數argv,且格式也與之相同,是由字符串指針所組成的數組,以NULL結束。argv[0]對應的便是新程序自身路徑名。
envp:參數envp也是一個字符串指針數組,指定了新程序的環境變量列表,參數envp其實對應于新程序的environ數組,同樣也是以NULL結束,所指向的字符串格式為name=value。
返回值:execve調用成功將不會返回;失敗將返回-1,并設置errno。
對execve()的成功調用將永不返回,而且也無需檢查它的返回值,實際上,一旦該函數返回,就表明它發生了錯誤。
基于系統調用execve(),還提供了一系列以exec為前綴命名的庫函數,雖然函數參數各異,當其功能相同,通常將這些函數(包括系統調用execve())稱為exec族函數,所以exec函數并不是指某一個函數、而是exec族函數,下一小節將會向大家介紹這些庫函數。
通常將調用這些exec函數加載一個外部新程序的過程稱為exec操作。
使用示例
編寫一個簡單地程序,在測試程序testApp當中通過execve()函數運行另一個新程序newApp。
示例代碼 10.11.1 execve()函數使用示例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(int argc, char *argv[])
{char *arg_arr[5];char *env_arr[5] = {"NAME=app", "AGE=25","SEX=man", NULL};if (2 > argc)exit(-1);arg_arr[0] = argv[1];arg_arr[1] = "Hello";arg_arr[2] = "World";arg_arr[3] = NULL;execve(argv[1], arg_arr, env_arr);perror("execve error");exit(-1);
}
將上述程序編譯成一個可執行文件testApp。
接著編寫新程序,在新程序當中打印出環境變量和傳參,如下所示:
示例代碼 10.11.2 新程序
#include <stdio.h>
#include <stdlib.h>extern char **environ;int main(int argc, char *argv[])
{char **ep = NULL;int j;for (j = 0; j < argc; j++)printf("argv[%d]: %s\n", j, argv[j]);puts("env:");for (ep = environ; *ep != NULL; ep++)printf(" %s\n", *ep);exit(0);
}
將新程序編譯成newApp可執行文件,兩份程序編譯好之后,如下所示:

圖 10.11.1 編譯程序
接下來進行測試,運行testApp程序,傳入一個參數,該參數便是新程序newApp的可執行文件路徑:

圖 10.11.2 測試結果
由上圖打印結果可知,在我們的testApp程序中,成功通過execve()運行了另一個新的程序newApp,當newApp程序運行完成退出后,testApp進程就結束了。
示例代碼 9.11.1中execve()函數的使用并不是它真正的應用場景,通常由fork()生成的子進程對execve()的調用最為頻繁,也就是子進程執行exec操作;示例代碼 9.11.1中的execve用法在實際的應用不常見,這里只是給大家進行演示說明。
說到這里,我們來分析一個問題,為什么需要在子進程中執行新程序?其實這個問題非常簡單,雖然可以直接在子進程分支編寫子進程需要運行的代碼,但是不夠靈活,擴展性不夠好,直接將子進程需要運行的代碼單獨放在一個可執行文件中不是更好嗎,所以就出現了exec操作。
10.11.2exec庫函數
exec族函數包括多個不同的函數,這些函數命名都以exec為前綴,上一小節給大家介紹的execve()函數也屬于exec族函數中的一員,但它屬于系統調用;本小節我們介紹exec族函數中的庫函數,這些庫函數都是基于系統調用execve()而實現的,雖然參數各異、但功能相同,包括:execl()、execlp()、execle()、execv()、execvp()、execvpe(),它們的函數原型如下所示:
#include <unistd.h>extern char **environ;int execl(const char *path, const char *arg, ... /* (char *) NULL */);
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
int execle(const char *path, const char *arg, ... /*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
使用這些函數需要包含頭文件<unistd.h>。
接下來簡單地介紹下它們之間的區別:
?execl()和execv()都是基本的exec函數,都可用于執行一個新程序,它們之間的區別在于參數格式不同;參數path意義和格式都相同,與系統調用execve()的filename參數相同,指向新程序的路徑名,既可以是絕對路徑、也可以是相對路徑。execl()和execv()不同的在于第二個參數,execv()的argv參數與execve()的argv參數相同,也是字符串指針數組;而execl()把參數列表依次排列,使用可變參數形式傳遞,本質上也是多個字符串,以NULL結尾,如下所示:
// execv傳參
char *arg_arr[5];
arg_arr[0] = “./newApp”;
arg_arr[1] = “Hello”;
arg_arr[2] = “World”;
arg_arr[3] = NULL;
execv("./newApp", arg_arr);
// execl傳參
execl("./newApp", “./newApp”, “Hello”, “World”, NULL);
?execlp()和execvp()在execl()和execv()基礎上加了一個p,這個p其實表示的是PATH;execl()和execv()要求提供新程序的路徑名,而execlp()和execvp()則允許只提供新程序文件名,系統會在由環境變量PATH所指定的目錄列表中尋找相應的可執行文件,如果執行的新程序是一個Linux命令,這將很有用;當然,execlp()和execvp()函數也兼容相對路徑和絕對路徑的方式。
?execle()和execvpe()這兩個函數在命名上加了一個e,這個e其實表示的是environment環境變量,意味著這兩個函數可以指定自定義的環境變量列表給新程序,參數envp與系統調用execve()的envp參數相同,也是字符串指針數組,使用方式如下所示:
// execvpe傳參
char *env_arr[5] = {“NAME=app”, “AGE=25”,
“SEX=man”, NULL};
char *arg_arr[5];
arg_arr[0] = “./newApp”;
arg_arr[1] = “Hello”;
arg_arr[2] = “World”;
arg_arr[3] = NULL;
execvpe("./newApp", arg_arr, env_arr);
// execle傳參
execle("./newApp", “./newApp”, “Hello”, “World”, NULL, env_arr);
給大家介紹完這些exec函數之后,下面將進行實戰。
10.11.3exec族函數使用示例
使用以上給大家介紹的6個exec庫函數運行ls命令,并加入參數-a和-l。
1、execl()函數運行ls命令。
示例代碼 10.11.3 execl執行ls命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{execl("/bin/ls", "ls", "-a", "-l", NULL);perror("execl error");exit(-1);
}
2、execv()函數運行ls命令。
示例代碼 10.11.4 execv()執行ls命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{char *arg_arr[5];arg_arr[0] = "ls";arg_arr[1] = "-a";arg_arr[2] = "-l";arg_arr[3] = NULL;execv("/bin/ls", arg_arr);perror("execv error");exit(-1);
}
3、execlp()函數運行ls命令。
示例代碼 10.11.5 execlp()執行ls命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{execlp("ls", "ls", "-a", "-l", NULL);perror("execlp error");exit(-1);
}
4、execvp()函數運行ls命令。
示例代碼 10.11.6 execvp()執行ls命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{char *arg_arr[5];arg_arr[0] = "ls";arg_arr[1] = "-a";arg_arr[2] = "-l";arg_arr[3] = NULL;execvp("ls", arg_arr);perror("execvp error");exit(-1);
}
5、execle()函數運行ls命令。
示例代碼 10.11.7 execle()執行ls命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>extern char **environ;int main(void)
{execle("/bin/ls", "ls", "-a", "-l", NULL, environ);perror("execle error");exit(-1);
}
6、execvpe()函數運行ls命令。
示例代碼 10.11.8 execvpe()執行ls命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>extern char **environ;int main(void)
{char *arg_arr[5];arg_arr[0] = "ls";arg_arr[1] = "-a";arg_arr[2] = "-l";arg_arr[3] = NULL;execvpe("ls", arg_arr, environ);perror("execvpe error");exit(-1);
}
以上所有的這些示例代碼,運行結果都是一樣的,與"ls -al"命令效果相同,如下所示:
圖 10.11.3 測試結果
10.11.4system()函數
使用system()函數可以很方便地在我們的程序當中執行任意shell命令,本小節來學習下system()函數的用法,以及介紹system()函數的實現方法。
首先來看看system()函數原型,如下所示:
#include <stdlib.h>
int system(const char *command);
這是一個庫函數,使用該函數需要包含頭文件<stdlib.h>。
函數參數和返回值含義如下:
command:參數command指向需要執行的shell命令,以字符串的形式提供,譬如"ls -al"、"echo HelloWorld"等。
返回值:關于system()函數的返回值有多種不同的情況,稍后給大家介紹。
system()函數其內部的是通過調用fork()、execl()以及waitpid()這三個函數來實現它的功能,首先system()會調用fork()創建一個子進程來運行shell(可以把這個子進程成為shell進程),并通過shell執行參數command所指定的命令。譬如:
system(“ls -la”)
system(“echo HelloWorld”)
system()的返回值如下:
?當參數command為NULL,如果shell可用則返回一個非0值,若不可用則返回0;針對一些非UNIX系統,該系統上可能是沒有shell的,這樣就會導致shell不可能;如果command參數不為NULL,則返回值從以下的各種情況所決定。
?如果無法創建子進程或無法獲取子進程的終止狀態,那么system()返回-1;
?如果子進程不能執行shell,則system()的返回值就好像是子進程通過調用_exit(127)終止了;
?如果所有的系統調用都成功,system()函數會返回執行command的shell進程的終止狀態。
system()的主要優點在于使用上方便簡單,編程時無需自己處理對fork()、exec函數、waitpid()以及exit()等調用細節,system()內部會代為處理;當然這些優點通常是以犧牲效率為代價的,使用system()運行shell命令需要至少創建兩個進程,一個進程用于運行shell、另外一個或多個進程則用于運行參數command中解析出來的命令,每一個命令都會調用一次exec函數來執行;所以從這里可以看出,使用system()函數其效率會大打折扣,如果我們的程序對效率或速度有所要求,那么建議大家不是直接使用system()。
使用示例
以下示例代碼演示了system()函數的用法,執行測試程序時,將需要執行的命令通過參數傳遞給main()函數,在main函數中調用system()來執行該條命令。
示例代碼 10.11.9 system()函數使用示例
#include <stdio.h>
#include <stdlib.h>int main(int argc, char *argv[])
{int ret;if (2 > argc)exit(-1);ret = system(argv[1]);if (-1 == ret)fputs("system error.\n", stderr);else {if (WIFEXITED(ret) && (127 == WEXITSTATUS(ret)))fputs("could not invoke shell.\n", stderr);}exit(0);
}
運行測試:

圖 10.11.4 測試結果
10.12進程狀態與進程關系
本小節來聊一聊關于進程狀態與進程關系相關的話題。
10.12.1進程狀態
Linux系統下進程通常存在6種不同的狀態,分為:就緒態、運行態、僵尸態、可中斷睡眠狀態(淺度睡眠)、不可中斷睡眠狀態(深度睡眠)以及暫停態。
?就緒態(Ready):指該進程滿足被CPU調度的所有條件但此時并沒有被調度執行,只要得到CPU就能夠直接運行;意味著該進程已經準備好被CPU執行,當一個進程的時間片到達,操作系統調度程序會從就緒態鏈表中調度一個進程;
?運行態:指該進程當前正在被CPU調度運行,處于就緒態的進程得到CPU調度就會進入運行態;
?僵尸態:僵尸態進程其實指的就是僵尸進程,指該進程已經結束、但其父進程還未給它“收尸”;
?可中斷睡眠狀態:可中斷睡眠也稱為淺度睡眠,表示睡的不夠“死”,還可以被喚醒,一般來說可以通過信號來喚醒;
?不可中斷睡眠狀態:不可中斷睡眠稱為深度睡眠,深度睡眠無法被信號喚醒,只能等待相應的條件成立才能結束睡眠狀態。把淺度睡眠和深度睡眠統稱為等待態(或者叫阻塞態),表示進程處于一種等待狀態,等待某種條件成立之后便會進入到就緒態;所以,處于等待態的進程是無法參與進程系統調度的。
?暫停態:暫停并不是進程的終止,表示進程暫停運行,一般可通過信號將進程暫停,譬如SIGSTOP信號;處于暫停態的進程是可以恢復進入到就緒態的,譬如收到SIGCONT信號。
一個新創建的進程會處于就緒態,只要得到CPU就能被執行。以下列出了進程各個狀態之間的轉換關系,如下所示:

圖 10.12.1 進程各狀態之間的切換
10.12.2進程關系
介紹完進程狀態之后,接下來聊一聊進程關系,在Linux系統下,每個進程都有自己唯一的標識:進程號(進程ID、PID),也有自己的生命周期,進程都有自己的父進程、而父進程也有父進程,這就形成了一個以init進程為根的進程家族樹;當子進程終止時,父進程會得到通知并能取得子進程的退出狀態。
除此之外,進程間還存在著其它一些層次關系,譬如進程組和會話;所以,由此可知,進程間存在著多種不同的關系,主要包括:無關系(相互獨立)、父子進程關系、進程組以及會話。
1、無關系
兩個進程間沒有任何關系,相互獨立。
2、父子進程關系
兩個進程間構成父子進程關系,譬如一個進程fork()創建出了另一個進程,那么這兩個進程間就構成了父子進程關系,調用fork()的進程稱為父進程、而被fork()創建出來的進程稱為子進程;當然,如果“生父”先與子進程結束,那么init進程(“養父”)就會成為子進程的父進程,它們之間同樣也是父子進程關系。
3、進程組
每個進程除了有一個進程ID、父進程ID之外,還有一個進程組ID,用于標識該進程屬于哪一個進程組,進程組是一個或多個進程的集合,這些進程并不是孤立的,它們彼此之間或者存在父子、兄弟關系,或者在功能上有聯系。
Linux系統設計進程組實質上是為了方便對進程進行管理。假設為了完成一個任務,需要并發運行100個進程,但當處于某種場景時需要終止這100個進程,若沒有進程組就需要一個一個去終止,這樣非常麻煩且容易出現一些問題;有了進程組的概念之后,就可以將這100個進程設置為一個進程組,這些進程共享一個進程組ID,這樣一來,終止這100個進程只需要終止該進程組即可。
關于進程組需要注意以下以下內容:
?每個進程必定屬于某一個進程組、且只能屬于一個進程組;
?每一個進程組有一個組長進程,組長進程的ID就等于進程組ID;
?在組長進程的ID前面加上一個負號即是操作進程組;
?組長進程不能再創建新的進程組;
?只要進程組中還存在一個進程,則該進程組就存在,這與其組長進程是否終止無關;
?一個進程組可以包含一個或多個進程,進程組的生命周期從被創建開始,到其內所有進程終止或離開該進程組;
?默認情況下,新創建的進程會繼承父進程的進程組ID。
通過系統調用getpgrp()或getpgid()可以獲取進程對應的進程組ID,其函數原型如下所示:
#include <unistd.h>
pid_t getpgid(pid_t pid);
pid_t getpgrp(void);
首先使用該函數需要包含頭文件<unistd.h>。
這兩個函數都用于獲取進程組ID,getpgrp()沒有參數,返回值總是調用者進程對應的進程組ID;而對于getpgid()函數來說,可通過參數pid指定獲取對應進程的進程組ID,如果參數pid為0表示獲取調用者進程的進程組ID。
getpgid()函數成功將返回進程組ID;失敗將返回-1、并設置errno。
所以由此可知,getpgrp()就等價于getpgid(0)。
使用示例
示例代碼 10.12.1 獲取進程組ID
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{pid_t pid = getpid();printf("進程組ID<%d>---getpgrp()\n", getpgrp());printf("進程組ID<%d>---getpgid(0)\n", getpgid(0));printf("進程組ID<%d>---getpgid(%d)\n", getpgid(pid), pid);exit(0);
}
測試結果:

圖 10.12.2 測試結果
從上面的結果可以發現,其新創建的進程對應的進程組ID等于該進程的ID。
調用系統調用setpgid()或setpgrp()可以加入一個現有的進程組或創建一個新的進程組,其函數原型如下所示:
#include <unistd.h>
int setpgid(pid_t pid, pid_t pgid);
int setpgrp(void);
使用這些函數同樣需要包含頭文件<unistd.h>。
setpgid()函數將參數pid指定的進程的進程組ID設置為參數gpid。如果這兩個參數相等(pid==gpid),則由pid指定的進程變成為進程組的組長進程,創建了一個新的進程;如果參數pid等于0,則使用調用者的進程ID;另外,如果參數gpid等于0,則創建一個新的進程組,由參數pid指定的進程作為進程組組長進程。
setpgrp()函數等價于setpgid(0, 0)。
一個進程只能為它自己或它的子進程設置進程組ID,在它的子進程調用exec函數后,它就不能更改該子進程的進程組ID了。
使用示例
示例代碼 10.12.2 創建進程組或加入一個現有進程組
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{printf("更改前進程組ID<%d>\n", getpgrp());setpgrp();printf("更改后進程組ID<%d>\n", getpgrp());exit(0);
}
4、會話
介紹完進程組之后,再來看下會話,會話是一個或多個進程組的集合,其與進程組、進程之間的關系如下圖所示:

圖 10.12.3 會話
一個會話可包含一個或多個進程組,但只能有一個前臺進程組,其它的是后臺進程組;每個會話都有一個會話首領(leader),即創建會話的進程。一個會話可以有控制終端、也可沒有控制終端,在有控制終端的情況下也只能連接一個控制終端,這通常是登錄到其上的終端設備(在終端登錄情況下)或偽終端設備(譬如通過SSH協議網絡登錄),一個會話中的進程組可被分為一個前臺進程組以及一個或多個后臺進程組。
會話的首領進程連接一個終端之后,該終端就成為會話的控制終端,與控制終端建立連接的會話首領進程被稱為控制進程;產生在終端上的輸入和信號將發送給會話的前臺進程組中的所有進程,譬如Ctrl + C(產生SIGINT信號)、Ctrl + Z(產生SIGTSTP信號)、Ctrl + \(產生SIGQUIT信號)等等這些由控制終端產生的信號。
當用戶在某個終端登錄時,一個新的會話就開始了;當我們在Linux系統下打開了多個終端窗口時,實際上就是創建了多個終端會話。
一個進程組由組長進程的ID標識,而對于會話來說,會話的首領進程的進程組ID將作為該會話的標識,也就是會話ID(sid),在默認情況下,新創建的進程會繼承父進程的會話ID。通過系統調用getsid()可以獲取進程的會話ID,其函數原型如下所示:
#include <unistd.h>
pid_t getsid(pid_t pid);
使用該函數需要包含頭文件<unistd.h>,如果參數pid為0,則返回調用者進程的會話ID;如果參數pid不為0,則返回參數pid指定的進程對應的會話ID。成功情況下,該函數返回會話ID,失敗則返回-1、并設置errno。
使用示例
示例代碼 10.12.3 獲取進程的會話ID
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int main(void)
{printf("會話ID<%d>\n", getsid(0));exit(0);
}
打印結果:

圖 10.12.4 測試結果
使用系統調用setsid()可以創建一個會話,其函數原型如下所示:
#include <unistd.h>
pid_t setsid(void);
如果調用者進程不是進程組的組長進程,調用setsid()將創建一個新的會話,調用者進程是新會話的首領進程,同樣也是一個新的進程組的組長進程,調用setsid()創建的會話將沒有控制終端。
setsid()調用成功將返回新會話的會話ID;失敗將返回-1,并設置errno。
10.13守護進程
本小節學習守護進程,將對守護進程的概念以及如何編寫一個守護進程程序進行介紹。
10.13.1何為守護進程
守護進程(Daemon)也稱為精靈進程,是運行在后臺的一種特殊進程,它獨立于控制終端并且周期性地執行某種任務或等待處理某些事情的發生,主要表現為以下兩個特點:
?長期運行。守護進程是一種生存期很長的一種進程,它們一般在系統啟動時開始運行,除非強行終止,否則直到系統關機都會保持運行。與守護進程相比,普通進程都是在用戶登錄或運行程序時創建,在運行結束或用戶注銷時終止,但守護進程不受用戶登錄注銷的影響,它們將會一直運行著、直到系統關機。
?與控制終端脫離。在Linux中,系統與用戶交互的界面稱為終端,每一個從終端開始運行的進程都會依附于這個終端,這是上一小節給大家介紹的控制終端,也就是會話的控制終端。當控制終端被關閉的時候,該會話就會退出,由控制終端運行的所有進程都會被終止,這使得普通進程都是和運行該進程的終端相綁定的;但守護進程能突破這種限制,它脫離終端并且在后臺運行,脫離終端的目的是為了避免進程在運行的過程中的信息在終端顯示并且進程也不會被任何終端所產生的信息所打斷。
守護進程是一種很有用的進程。Linux中大多數服務器就是用守護進程實現的,譬如,Internet服務器inetd、Web服務器httpd等。同時,守護進程完成許多系統任務,譬如作業規劃進程crond等。
守護進程Daemon,通常簡稱為d,一般進程名后面帶有d就表示它是一個守護進程。守護進程與終端無任何關聯,用戶的登錄與注銷與守護進程無關、不受其影響,守護進程自成進程組、自成會話,即pid=gid=sid。通過命令"ps -ajx"查看系統所有的進程,如下所示:

圖 10.13.1 查看系統中的所有進程
TTY一欄是問號?表示該進程沒有控制終端,也就是守護進程,其中COMMAND一欄使用中括號[]括起來的表示內核線程,這些線程是在內核里創建,沒有用戶空間代碼,因此沒有程序文件名和命令行,通常采用k開頭的名字,表示Kernel。
10.13.2編寫守護進程程序
如何將自己編寫的程序運行之后變成一個守護進程呢?本小節就來學習如何編寫守護進程程序,編寫守護進程一般包含如下幾個步驟:
1)創建子進程、終止父進程
父進程調用fork()創建子進程,然后父進程使用exit()退出,這樣做實現了下面幾點。第一,如果該守護進程是作為一條簡單地shell命令啟動,那么父進程終止會讓shell認為這條命令已經執行完畢。第二,雖然子進程繼承了父進程的進程組ID,但它有自己獨立的進程ID,這保證了子進程不是一個進程組的組長進程,這是下面將要調用setsid函數的先決條件!
2)子進程調用setsid創建會話
這步是關鍵,在子進程中調用上一小節給大家介紹的setsid()函數創建新的會話,由于之前子進程并不是進程組的組長進程,所以調用setsid()會使得子進程創建一個新的會話,子進程成為新會話的首領進程,同樣也創建了新的進程組、子進程成為組長進程,此時創建的會話將沒有控制終端。所以這里調用setsid有三個作用:讓子進程擺脫原會話的控制、讓子進程擺脫原進程組的控制和讓子進程擺脫原控制終端的控制。
在調用fork函數時,子進程繼承了父進程的會話、進程組、控制終端等,雖然父進程退出了,但原先的會話期、進程組、控制終端等并沒有改變,因此,那還不是真正意義上使兩者獨立開來。setsid函數能夠使子進程完全獨立出來,從而脫離所有其他進程的控制。
3)將工作目錄更改為根目錄
子進程是繼承了父進程的當前工作目錄,由于在進程運行中,當前目錄所在的文件系統是不能卸載的,這對以后使用會造成很多的麻煩。因此通常的做法是讓“/”作為守護進程的當前目錄,當然也可以指定其它目錄來作為守護進程的工作目錄。
4)重設文件權限掩碼umask
文件權限掩碼umask用于對新建文件的權限位進行屏蔽,在5.5.5小節中有介紹。由于使用fork函數新建的子進程繼承了父進程的文件權限掩碼,這就給子進程使用文件帶來了諸多的麻煩。因此,把文件權限掩碼設置為0,確保子進程有最大操作權限、這樣可以大大增強該守護進程的靈活性。設置文件權限掩碼的函數是umask,通常的使用方法為umask(0)。
5)關閉不再需要的文件描述符
子進程繼承了父進程的所有文件描述符,這些被打開的文件可能永遠不會被守護進程(此時守護進程指的就是子進程,父進程退出、子進程成為守護進程)讀或寫,但它們一樣消耗系統資源,可能導致所在的文件系統無法卸載,所以必須關閉這些文件,這使得守護進程不再持有從其父進程繼承過來的任何文件描述符。
6)將文件描述符號為0、1、2定位到/dev/null
將守護進程的標準輸入、標準輸出以及標準錯誤重定向到/dev/null,這使得守護進程的輸出無處顯示、也無處從交互式用戶那里接收輸入。
7)其它:忽略SIGCHLD信號
處理SIGCHLD信號不是必須的,但對于某些進程,特別是并發服務器進程往往是特別重要的,服務器進程在接收到客戶端請求時會創建子進程去處理該請求,如果子進程結束之后,父進程沒有去wait回收子進程,則子進程將成為僵尸進程;如果父進程wait等待子進程退出,將又會增加父進程的負擔、也就是增加服務器的負擔,影響服務器進程的并發性能,在Linux下,可以將SIGCHLD信號的處理方式設置為SIG_IGN,也就是忽略該信號,可讓內核將僵尸進程轉交給init進程去處理,這樣既不會產生僵尸進程、又省去了服務器進程回收子進程所占用的時間。
守護進程一般以單例模式運行,關于單例模式運行請看9.14小節內容。
接下來,我們根據上面的介紹的步驟,來編寫一個守護進程程序,示例代碼如下所示:
示例代碼 10.13.1 守護進程示例代碼
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>int main(void)
{pid_t pid;int i;/* 創建子進程 */pid = fork();if (0 > pid) {perror("fork error");exit(-1);}else if (0 < pid)//父進程exit(0); //直接退出/**子進程*//* 1.創建新的會話、脫離控制終端 */if (0 > setsid()) {perror("setsid error");exit(-1);}/* 2.設置當前工作目錄為根目錄 */if (0 > chdir("/")) {perror("chdir error");exit(-1);}/* 3.重設文件權限掩碼umask */umask(0);/* 4.關閉所有文件描述符 */for (i = 0; i < sysconf(_SC_OPEN_MAX); i++)close(i);/* 5.將文件描述符號為0、1、2定位到/dev/null */open("/dev/null", O_RDWR);dup(0);dup(0);/* 6.忽略SIGCHLD信號 */signal(SIGCHLD, SIG_IGN);/* 正式進入到守護進程 */for ( ; ; ) {sleep(1);puts("守護進程運行中......");}exit(0);
}
整個代碼的編寫都是根據上面的介紹來完成的,這里就不再啰嗦,示例代碼中使用到的函數在前面都已經學習過,其中第4步中調用sysconf(_SC_OPEN_MAX)用于獲取當前系統允許進程打開的最大文件數量。
我們在守護進程中添加了死循環,每隔1秒鐘打印一行字符串信息,接下來編譯運行:
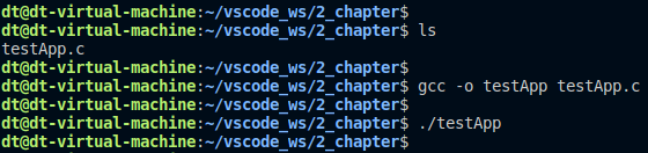
圖 10.13.2 測試結果
運行之后,沒有任何打印信息輸出,原因在于守護進程已經脫離了控制終端,它的打印信息并不會輸出顯示到終端,在代碼中已經將標準輸入、輸出以及錯誤重定位到了/dev/null,/dev/null是一個黑洞文件,自然是看不到輸出信息。
使用"ps -ajx"命令查看進程,如下所示:

圖 10.13.3 查看守護進程
從上圖可知,testApp進程成為了一個守護進程,與控制臺脫離,當關閉當前控制終端時,testApp進程并不會受到影響,依然會正常繼續運行;而對于普通進程來說,終端關閉,那么由該終端運行的所有進程都會被強制關閉,因為它們處于同一個會話。關于這個問題,大家可以自己去測試下,對比測試普通進程與守護進程,當終端關閉之后是否還在繼續運行。
守護進程可以通過終端命令行啟動,但通常它們是由系統初始化腳本進行啟動,譬如/etc/rc*或/etc/init.d/*等。
10.13.3SIGHUP信號
當用戶準備退出會話時,系統向該會話發出SIGHUP信號,會話將SIGHUP信號發送給所有子進程,子進程接收到SIGHUP信號后,便會自動終止,當所有會話中的所有進程都退出時,會話也就終止了;因為程序當中一般不會對SIGHUP信號進行處理,所以對應的處理方式為系統默認方式,SIGHUP信號的系統默認處理方式便是終止進程。
上面解釋了,為什么子進程會隨著會話的退出而退出,因為它收到了SIGHUP信號。不管是前臺進程還是后臺進程都會收到該信號。如果忽略該信號,將會出現什么樣的結果?接下來我們編寫一個簡單地測試程序,示例代碼如下所示:
示例代碼 10.13.2 忽略SIGHUP示例代碼
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>int main(void)
{signal(SIGHUP, SIG_IGN);for ( ; ; ) {sleep(1);puts("進程運行中......");}
}
代碼很簡單,調用signal()函數將SIGHUP信號的處理方式設置為忽略。測試運行

圖 10.13.4 測試結果
成功運行之后,關閉終端

圖 10.13.5 關閉終端
再重新打開終端,使用ps命令查看testApp進程是否存在,如下所示:

圖 10.13.6 查看testApp進程
可以發現testApp進程依然還在運行,但此時它已經變成了守護進程,脫離了控制終端,所以由此可知,當程序當中忽略SIGHUP信號之后,進程不會隨著終端退出而退出,事實上,控制終端只是會話中的一個進程,只有會話中的所有進程退出后,會話才會結束;很顯然當程序中忽略了SIGHUP信號,導致該進程不會終止,所以會話也依然會存在,從上圖可知,其會話ID等于23601,但此時會話已經沒有控制終端了。
10.14單例模式運行
通常情況下,一個程序可以被多次執行,即程序在還沒有結束的情況下,又再次執行該程序,也就是系統中同時存在多個該程序的實例化對象(進程),譬如大家所熟悉的聊天軟件QQ,我們可以在電腦上同時登陸多個QQ賬號,譬如還有一些游戲也是如此,在一臺電腦上同時登陸多個游戲賬號,只要你電腦不卡機、隨便你開幾個號。
但對于有些程序設計來說,不允許出現這種情況,程序只能被執行一次,只要該程序沒有結束,就無法再次運行,我們把這種情況稱為單例模式運行。譬如系統中守護進程,這些守護進程一般都是服務器進程,服務器程序只需要運行一次即可,能夠在系統整個的運行過程中提供相應的服務支持,多次同時運行并沒有意義、甚至還會帶來錯誤!
如果希望我們的程序具有單例模式運行的功能,應該如何去實現呢?
10.14.1通過文件存在與否進行判斷
首先這是一個非常簡單且容易想到的方法:用一個文件的存在與否來做標志,在程序運行正式代碼之前,先判斷一個特定的文件是否存在,如果存在則表明進程已經運行,此時應該立馬退出;如果不存在則表明進程沒有運行,然后創建該文件,當程序結束時再刪除該文件即可!
這種方法是大家比較容易想到的,通過一個特定文件的存在與否來做判斷,當然這個特定的文件的命名要弄的特殊一點,避免在文件系統中不會真的存在該文件,接下來我們編寫一個程序進行測試。
示例代碼 10.14.1 簡單方式實現單例模式運行
#include <stdio.h>
#include <stdlib.h>
#include <sys/file.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>#define LOCK_FILE "./testApp.lock"static void delete_file(void)
{remove(LOCK_FILE);
}int main(void)
{/* 打開文件 */int fd = open(LOCK_FILE, O_RDONLY | O_CREAT | O_EXCL, 0666);if (-1 == fd) {fputs("不能重復執行該程序!\n", stderr);exit(-1);}/* 注冊進程終止處理函數 */if (atexit(delete_file))exit(-1);puts("程序運行中...");sleep(10);puts("程序結束");close(fd); //關閉文件exit(0);
}
在上述示例代碼中,通過當前目錄下的testApp.lock文件作為特定文件進行判斷該文件是否存在,當然這里只是舉個例子,如果在實際應用編程中使用了這種方法,這個特定文件需要存放在一個特定的路徑下。
代碼中以O_RDONLY | O_CREAT | O_EXCL的方式打開文件,如果文件不存在則創建文件,如果文件存在則open會報錯返回-1;使用atexit注冊進程終止處理函數,當程序退出時,使用remove()刪除該文件。
運行測試:

圖 10.14.1 測試結果
在上面測試中,首先第一次以后臺方式運行了testApp程序,之后再運行testApp程序,由于文件已經存在,所以open()調用會失敗,所以意味著進程正在運行中,所以會打印相應的字符串然后退出。直到第一次運行的程序結束時,才能執行testApp程序,這樣就實現了一個簡單地具有單例模式運行功能的程序。
雖然上面實現了一個簡單地單例模式運行的程序,但是仔細一想其實有很大的問題,主要包括如下三個方面:
?程序中使用_exit()退出,那么將無法執行delete_file()函數,意味著無法刪除這個特定的文件;
?程序異常退出。程序異常同樣無法執行到進程終止處理函數delete_file(),同樣將導致無法刪除這個特定的文件;
?計算機掉電關機。這種情況就更加直接了,計算機可能在程序運行到任意位置時發生掉電關機的情況,這是無法預料的;如果文件沒有刪除就發生了這種情況,計算機重啟之后文件依然存在,導致程序無法執行。
針對第一種情況,我們使用exit()代替_exit()可以很好的解決這種問題;但是對于第二種情況來說,異常退出,譬如進程接收到信號導致異常終止,有一種解決辦法便是設置信號處理方式為忽略信號,這樣當進程接收到信號時就會被忽略,或者是針對某些信號注冊信號處理函數,譬如SIGTERM、SIGINT等,在信號處理函數中刪除文件然后再退出進程;但依然有個問題,并不是所有信號都可被忽略或捕獲的,譬如SIGKILL和SIGSTOP,這兩個信號是無法被忽略和捕獲的,故而這種也不靠譜。
針對第三種情況的解決辦法便是,使得該特定文件會隨著系統的重啟而銷毀,這個怎么做呢?其實這個非常簡單,將文件放置到系統/tmp目錄下,/tmp是一個臨時文件系統,當系統重啟之后/tmp目錄下的文件就會被銷毀,所以該目錄下的文件的生命周期便是系統運行周期。
由此可知,雖然針對第一種情況和第三種情況都有相應的解決辦法,但對于第二種情況來說,其解決辦法并不靠譜,所以使用這種方法實現單例模式運行并不靠譜。
10.14.2使用文件鎖
介紹完上面第一種比較容易想到的方法外,接下來介紹一種靠譜的方法,使用文件鎖來實現,事實上這種方式才是實現單例模式運行靠譜的方法。
同樣也需要通過一個特定的文件來實現,當程序啟動之后,首先打開該文件,調用open時一般使用O_WRONLY | O_CREAT標志,當文件不存在則創建該文件,然后嘗試去獲取文件鎖,若是成功,則將程序的進程號(PID)寫入到該文件中,寫入后不要關閉文件或解鎖(釋放文件鎖),保證進程一直持有該文件鎖;若是程序獲取鎖失敗,代表程序已經被運行、則退出本次啟動。
Tips:當程序退出或文件關閉之后,文件鎖會自動解鎖!
文件鎖屬于本書高級I/O章節內容,在13.6小節對此做了詳細介紹,這里就不再說明,通過系統調用flock()、fcntl()或庫函數lockf()均可實現對文件進行上鎖,本小節我們以系統調用flock()為例,系統調用flock()產生的是咨詢鎖(建議性鎖)、并不能產生強制性鎖。
接下來編寫一個示例代碼,使用flock()函數對文件上鎖,實現程序以單例模式運行,如下所示:
示例代碼 10.14.2 使用文件鎖實現單利模式運行
#include <stdio.h>
#include <stdlib.h>
#include <sys/file.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <string.h>#define LOCK_FILE "./testApp.pid"int main(void)
{char str[20] = {0};int fd;/* 打開lock文件,如果文件不存在則創建 */fd = open(LOCK_FILE, O_WRONLY | O_CREAT, 0666);if (-1 == fd) {perror("open error");exit(-1);}/* 以非阻塞方式獲取文件鎖 */if (-1 == flock(fd, LOCK_EX | LOCK_NB)) {fputs("不能重復執行該程序!\n", stderr);close(fd);exit(-1);}puts("程序運行中...");ftruncate(fd, 0); //將文件長度截斷為0sprintf(str, "%d\n", getpid());write(fd, str, strlen(str));//寫入pidfor ( ; ; )sleep(1);exit(0);
}
程序啟動首先打開一個特定的文件,這里只是舉例,以當前目錄下的testApp.pid文件作為特定文件,以O_WRONLY | O_CREAT方式打開,如果文件不存在則創建該文件;打開文件之后使用flock嘗試獲取文件鎖,調用flock()時指定了互斥鎖標志LOCK_NB,意味著同時只能有一個進程擁有該鎖,如果獲取鎖失敗,表示該程序已經啟動了,無需再次執行,然后退出;如果獲取鎖成功,將進程的PID寫入到該文件中,當程序退出時,會自動解鎖、關閉文件。
運行測試:

圖 10.14.2 測試結果
這種機制在一些程序尤其是服務器程序中很常見,服務器程序使用這種方法來保證程序的單例模式運行;在Linux系統中/var/run/目錄下有很多以.pid為后綴結尾的文件,這個實際上是為了保證程序以單例模式運行而設計的,作為程序實現單例模式運行所需的特定文件,如下所示:

圖 10.14.3 /var/run目錄下的文件
這些以.pid為后綴的文件,命名方式通常是程序名+.pid,譬如acpid.pid對應的程序便是acpid、lightdm.pid對應的程序便是lightdm等等。如果我們要去實現一個以單例模式運行的程序,譬如一個守護進程,那么也應該將這個特定文件放置于Linux系統/var/run/目錄下,并且文件的命名方式為name.pid(name表示進程名)。
關于實現單例模式運行相關內容就給大家介紹這么多,最常用的還是使用文件鎖,第一種方法通過文件存在否與進行判斷事實上并不靠譜;除此之外,還有其它一些方法也可用于實現單例模式運行,譬如在程序啟動時通過ps判斷進程是否存在等,關于更多的方法,歡迎大家留言!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态