首页
HTML
前端
框架
JavaScript
CSS
首页
/
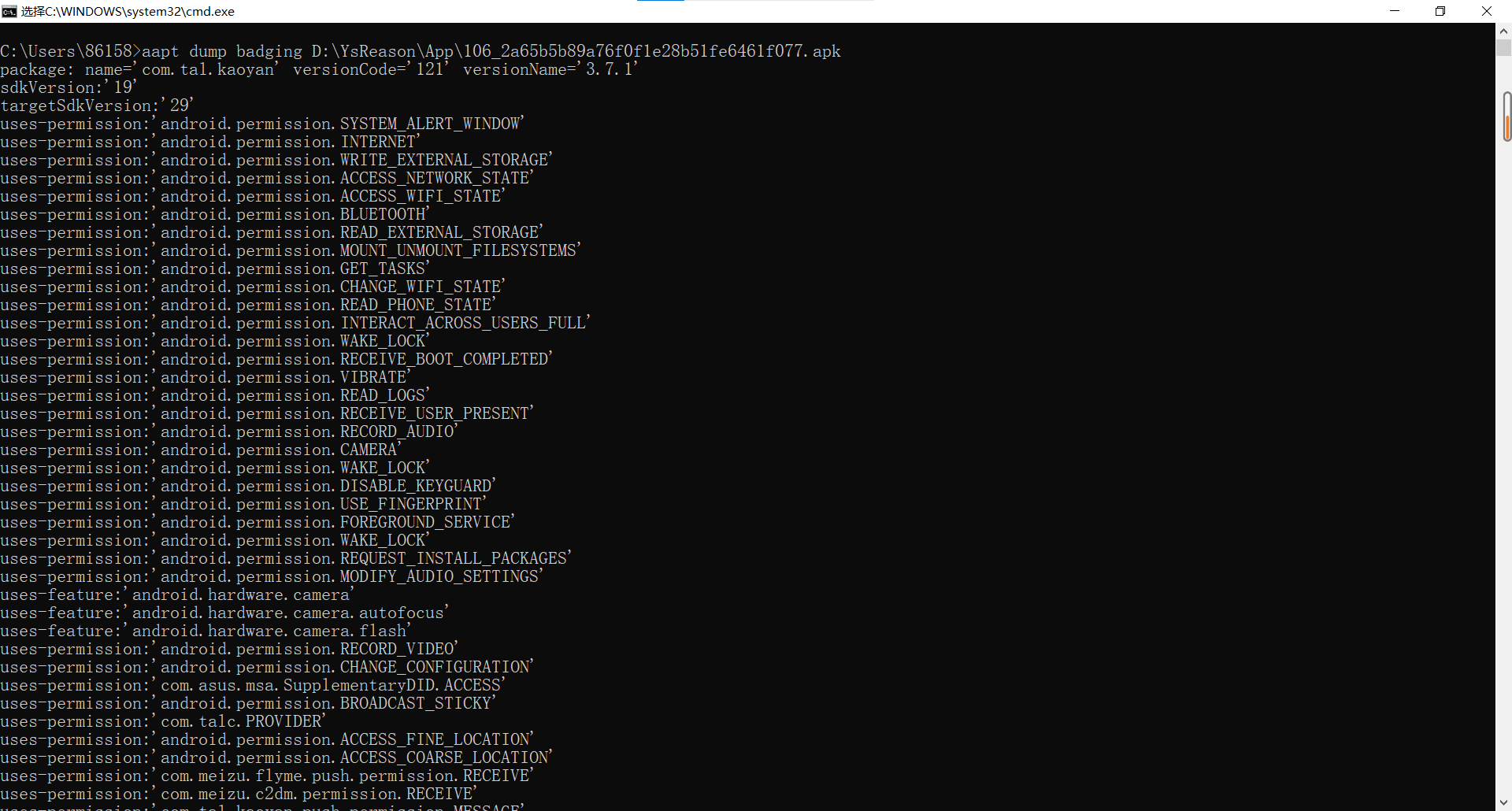
爬虫爬数据有痕迹么
python爬虫最全教程,Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查…还是蛮多的,技术高手千千万,总有五花八门的反爬技术出现,对于爬虫coder来说,干!就完了,反正也996了~ python爬虫最全教程?作为
时间:2023-09-25 | 阅读:27
爬虫获取数据,[爬虫]4.数据解析及应用 之 bs4【爬取一部小说的文本】
回顾,上节课我们学了什么? 聚焦爬虫 数据解析方式分类:正则表达式;bs4模块;xpath模块 F12查看网页标签的html格式 正则表达式详细表示方法 爬虫获取数据。正则匹配 import re list=re.findall(pattern,string,flags) 创建文件夹 爬取
时间:2023-09-25 | 阅读:26
爬虫代码,爬虫第六课:爬取携程酒店数据
首先打开携程所有北京的酒店http://hotels.ctrip.com/hotel/beijing1 简简单单,源代码中包含我们需要的酒店数据,你以为这样就结束了?携程的这些数据这么廉价地就给我们得到了?事实并不是如此,当我们点击第二页的时候出现问题:虽然
时间:2023-09-23 | 阅读:26
爬虫爬数据有痕迹么,使用爬虫爬取移动端数据
这里写自定义目录标题1:移动端的前导知识1.1:移动端数据爬取数据的背景介绍1.2:移动端数据的作用1.3:课外拓展2:Uiautomator介绍2.1:ua是什么2.2:Uiautomator能够做什么2.3:AccessibilityService3:安卓系统中
时间:2023-09-22 | 阅读:27
爬虫数据查询
这东西对我大一新生而言真是太不友善了555...弄了好久、头晕眼花,研究这老师的代码,对着一个个改成自己数据库对应的东西,总算是把数据查询所涉及的这些东西都大致搞完搞明白了...吧?下面就来聊聊我这几天到处找人帮忙、问问题终于整出来的成果..
时间:2023-09-15 | 阅读:23
爬虫:Ajax数据爬取
目录 1、什么是Ajax 1.1 实例的引入 1.2 基本原理 2、Ajax分析方法 1、查看请求 2、过滤请求 3、Ajax结果提取 1、分析请求 2、分析响应 3、例子 我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数
时间:2023-09-11 | 阅读:29
Node.js之Cheerio爬数据!~
爬数据!~ 本意是想写一些接口感受一下Nodejs魅力,奈何没有数据,延伸了一下爬虫数据采集,让咱的数据库不太假。 cheerio 数据截取 是的,没想到有一天咱也会爬别人玩~ 哈哈哈! 引入模块为了搞数据 const cheerio = require("cheerio
时间:2023-09-10 | 阅读:28
使用爬虫爬取豆瓣电影影评数据Java版
2019独角兽企业重金招聘Python工程师标准>>> 近期被《我不是药神》这部国产神剧刷屏了,为了分析观众对于这部电影的真实感受,我爬取了豆瓣电影影评数据。当然本文仅讲爬虫部分(暂不涉及分析部分),属于比较基础的爬虫实现,
时间:2023-09-07 | 阅读:17
【Python】去哪儿旅游景点数据爬虫
爬虫需要模块:BeautifulSoup、requests 爬虫网站:去哪儿-https://travel.qunar.com/place/ 1.爬取城市ID链接 例如:https://travel.qunar.com/p-cs300148-haikou # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import pandas as pd import re
时间:2023-09-06 | 阅读:19
吃西瓜--爬虫系列之数据解析
XPath语法 xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。 开发工具 Chrome插件XPath Helper。 选取节点: XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表
时间:2023-09-06 | 阅读:19
1
2
»
阅读排行
806℃
1
职业性格测试
787℃
2
【小程序项目开发-- 京东商...
730℃
3
ORA-14402:updating parti...
725℃
4
Android系统操作的50个实用...
685℃
5
mac上tflite编译
635℃
6
一分钟自我介绍 建议
559℃
7
IT人不要一直做技术
556℃
8
多線程調用同一個對象的方...
猜你喜欢
去年日本国内汽车销售榜单公布
react前端环境搭建
别人的爬虫在干啥
网易、腾讯、阿里竞相押宝的NFT,还有多大的想象空间?
怎样搜索计算机中docx格式的文件,教您电脑docx文件怎样打开呢?教你正确打开docx文件...
六字诀养生法--吹、呼、嘻、呵、嘘、呬
搜索引擎的概念鄂州_搜索引擎的概念
项目文件2 问题日志 经验教训登记册 里程碑清单 实物资源分配单 项目日历 项目沟通记录 项目进度计划 项目进度网络图
manjaro时间不对,恢复正确时间
前端包管理器的依赖管理原理
关于颜色与颜色空间
电子标签的LF, HF, UHF都分别代表什么?
热门标签
python3
python有什么用
python和java
python爬虫教程
python为什么叫爬虫
Spring Boot
UNIXLINUX
LINUX教程
python爬蟲教程
python编程
springboot
Mybatis
linux
Java
python怎么用
python編程
什么是LINUX
android
我要关灯
我要开灯
客户电话
808629
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部

![爬虫获取数据,[爬虫]4.数据解析及应用 之 bs4【爬取一部小说的文本】](https://img-blog.csdnimg.cn/7797cc47f7264127b6b781a3295caf28.jpeg)