9.2.1 Boosting是什么
Boosting是一類算法的統稱,翻譯成中文為“自適應”算法,它們的主要
特點是使用一組弱分類器通過“迭代更新”的方式構造一個強分類器。在每輪
迭代中會在訓練集上產生一個新的弱分類器,然后使用該弱分類器對所有樣本
進行分類,從而評估每個樣本的重要性。從中文名可以看出來,Boosting算法
的每輪學習都會根據數據調整參數,不斷提升模型的準確率。
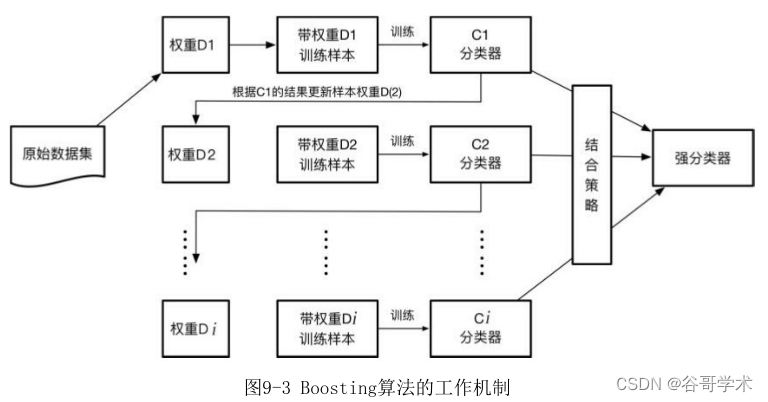
Boosting算法的工作機制如圖9-3所示。它首先基于訓練樣本生成一個弱
學習器,然后基于弱學習器的表現調整樣本分布,即增加錯誤樣本的權重,使
其在后續受到更多關注。調整好權重的訓練集后,繼續生成?一個弱學習器,
不斷循環這個過程,直到生成一定數量的弱學習器,最后基于某種結合策略來
綜合這多個弱學習器的輸出。
人工智能十大算法,這種模式類似于一個放大版的神經網絡。還記得在神經網絡中,我們需要
預設參數,再根據樣本數據訓練模型,不斷調整參數,最后才能輸出結果。在
Boosting 算法中,一個個弱分類器就像不同的神經元,每一次傳輸就像經過
一層隱藏層,然后層層輸出,不斷調整參數,最后基于某種策略綜合后得到輸
出結果。
Boosting算法并沒有規定具體的實現方法,但大多數實現算法會有以?特
點:
(1)通過迭代的方式生成多個弱分類器。
(2)將這些弱分類器組合成一個強分類器,通常會根據各個弱分類器的
準確性設置不同的權重。
(3)每生成一個弱分類器,會重新設置訓練樣本的權重,被錯誤分類的
樣本會增加其權重,正確分類的樣本會減少其權重,所以后續生成的分類器將
更多地關注前面分錯的樣本。
弱分類器訓練的目的在于,通過改變樣本分布,使得分類器聚集在那些很
難區分的樣本上,對容易錯分的樣本加強學習,增加錯分樣本的權重。這樣做
使得錯分的樣本在?一輪的迭代中有更大的作用,這也是一種對錯分樣本的懲
罰機制。這種設計有兩個好處,一方面可以根據權重的分布情況,提供數據抽
樣的依據;另一方面可以利用權重提升弱分類器的決策能力,使弱分類器也能
達到強分類器的效果。
Boosting算法通過權重投票的方式將N個弱分類器組合成一個強分類器。
只有弱分類器的分類精度高于 50%,才可以將它組合到強分類器里,這種方式
會逐漸降低強分類器的分類誤差。但是這個機制也并非最完美的,由于
Boosting 算法將注意力集中在難分的樣本上,這使得它對訓練集的噪聲點非
常敏感,把主要的精力都集中在噪聲樣本上,從而影響最終的分類性能,也容
易造成過擬合現象。
因此關于 Boosting 算法,有兩個值得深入探討的地方:一是在每一輪迭
代中如何改變訓練數據的分布情況;二是如何將多個弱分類器組合成一個強分
類器。使用的學習策略不同,算法的效果也不相同。
。
9.2.2 AdaBoost如何增強
在1995年,弗洛因德(Yoav Freund)教授與夏皮爾教授根據在線分配算
法理論提出了隨后風靡一時的AdaBoost算法,這是一種改進版的Boosting分類
算法。由于AdaBoost算法的優異性能,弗洛因德和夏皮爾教授獲得了2003年度
的哥德爾獎,該獎是理論計算機科學領域中最負盛名的獎項之一。
AdaBoost是Adaptive Boosting的縮寫,中文意思為“自適應增強”。這
個算法的“增強”體現在它設置了兩種權重:一種是數據的權重;另一種是弱
分類器的權重。數據的權重主要用于弱分類器尋找其分類誤差最小的決策點,
找到之后用這個最小誤差計算出該弱分類器的權重,表示該分類器的“發言
權”,分類器權重越大說明該弱分類器在最終決策時擁有越大的發言權。在前
一個弱分類器中被錯誤分類的樣本的權重會增大,而正確分類的樣本的權重會
減小,并再次用來訓練?一個基本分類器。同時,在每一輪迭代中,加入一個
新的弱分類器,直到達到某個預定的足夠小的錯誤率或達到預先指定的最大迭
代次數,從而確定最終的強分類器。
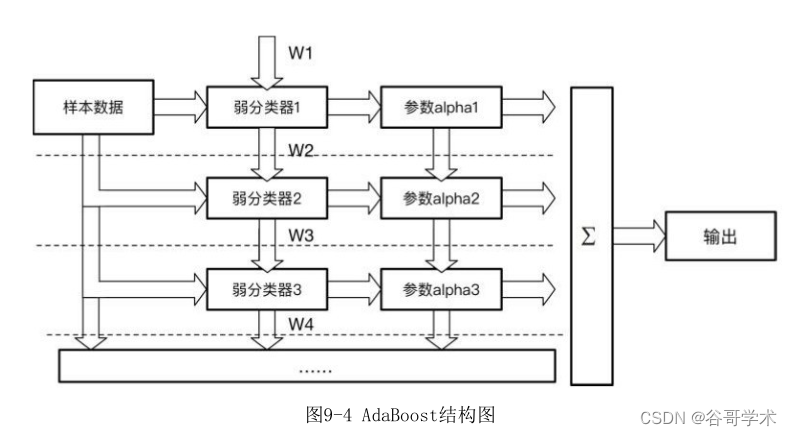
AdaBoost 分類器的整體結構如圖 9-4 所示,圖中的虛線表示不同輪次的
迭代效果。第1次迭代時,只有第1行結構;第2次迭代時,包括第1行與第2行
的結構。每次迭代都增加一行結構,不斷迭代這個過程直至所有弱分類器訓練
完?。
在這個迭代過程中,每一輪迭代都需要經過以?幾個步驟:
(1)新增一個弱分類器(i)并且賦予弱分類器一個權重值alpha(i)。
(2)通過樣本數據集與數據權重W(i)訓練弱分類器(i),并得出其分類錯
誤率,以此計算出這個弱分類器的權重alpha(i)。
(3)通過加權投票表決的方式,讓所有弱分類器進行加權投票表決得到
最終預測輸出,計算最終分類錯誤率。如果最終錯誤率低于設定閾值(比如
5%),迭代結束;如果最終錯誤率高于設定閾值,則更新數據權重得到
W(i+1)。上述步驟如圖9-4所示。
 ?
?
?面舉一個直觀的例子讓大家感受一?AdaBoost算法的分類過程。如圖9-
5所示,圖中兩種符號代表正負兩類數據,目前的樣本分布為D1,我們開始訓
練模型。
boosting算法。 ?
?
第一步采用弱分類器W1對樣本數據分類。根據這次分類的正確性,得到一
個新的樣本分布D2,如圖9-6所示。其中畫圈的樣本是被分錯的,在右邊的圖
中,比較大的“+”表示對該樣本做了加權,?一輪分類時會“重點照顧”這
些樣本,同時賦予弱分類器W1一個權值。圖中的 ε1=0.3,表示錯誤率;
α1=0.42,表示該分類器的權重,α1=1/2*ln((1- ε1)/ ε1)。
 ?
?
第二步采用弱分類器W2對樣本數據進行分類,根據這次分類的正確性,再
得到一個新的樣本分布D3,同時更新W2的權值,如圖9-7所示。
關于人工智能, ?
?
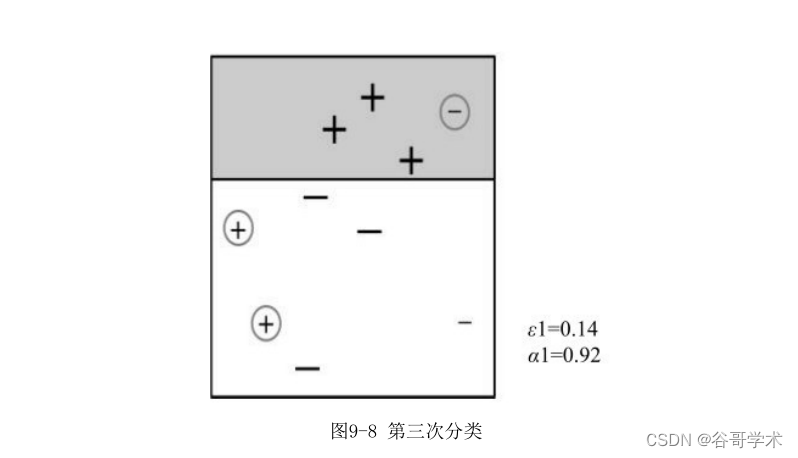
第三步采用弱分類器W3對樣本數據進行分類,根據這次分類的正確性,再
得到一個新的樣本分布D4,同時更新W3的權值,如圖9-8所示。?
最后我們整合三個分類情況。同時根據三個分類器的權值采用加權的方式
計算結果,最后的分類效果如圖9-9所示,從結果看,即使簡單的分類器,將
它們組合起來也能獲得很好的分類效果。
貝葉斯優化算法調參。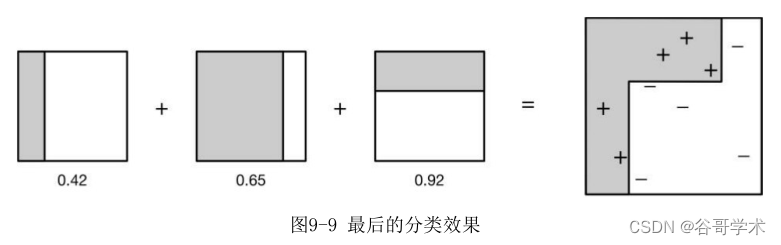 ?
?
相比普通的 Boosting 算法,AdaBoost 能夠自適應地調整弱學習算法的
錯誤率,經過若干次迭代后使得錯誤率達到預期的大小 。同時它也不需要知
道精確的樣本空間分布,在每次學習后調整樣本空間分布;更新所有訓練樣本
的權重——將樣本空間中正確分類的樣本權重降低,提高錯誤分類的樣本權
重;?次學習時分類器才會關注這些錯誤分類的樣本,提升?輪分對的概率。
如果還沒有分對,那么繼續增加錯分點的權重,一直重復這個過程,直到模型
運行結束。
AdaBoost 算法最大的優點在于,它不需要預先知道弱分類器的錯誤率上
限,最后得到的強分類器的分類精度依賴于所有弱分類器的分類精度,所以具
有深挖分類器的能力。同時它可以根據弱分類器的反饋,自適應地調整假定的
錯誤率,執行效率高。并且AdaBoost提供一種框架,在框架內可以使用各種方
法構建子分類器,不用對特征進行篩選,也不存在過擬合的現象。在理論上任
何學習器都可以用于AdaBoost算法。但在實際項目中,使用最廣泛的AdaBoost
弱學習器是決策樹和神經網絡,因為它們可以很容易地應用到實際問題中,目
前已成為最流行的Boosting算法。
AdaBoost算法并非沒有缺點,在AdaBoost訓練過程中,它會使得難于分類
的樣本的權值呈指數增長,訓練會過于偏向這類樣本,導致算法易受“噪
聲”干擾。這一點是我們在使用過程中值得注意的地方。
9.2.3 梯度下降與決策樹集成
梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)算法是近
年來受到大家廣泛關注的一個算法,這主要得益于該算法的優異性能,以及該
算法在各類數據挖掘與機器學習比賽中的卓越表現。
GBDT算法也是Boosting家族的重要成員,它是Gradient Boosting的其中
一個方法。GBDT實際上結合了梯度?降、決策樹兩種方法的優點,再采用集成
的方式訓練模型,從而得到更優的結果。以往單獨使用決策樹算法時,很容易
產生過擬合現象。而通過梯度提升的方法集成多個決策樹,能夠有效解決過擬
合的問題。由此可見,梯度提升方法和決策樹學習算法可以互相取長補短,發
揮1+1>2的價值。
GBDT算法的結構如圖9-10所示。GBDT通過多輪迭代,每輪迭代產生一個弱
分類器,每個分類器在上一輪分類器的?差基礎上進行訓練。一般選擇分類回
歸樹作為弱分類器,且這棵樹必須滿足低方差和高偏差的特點。因為 GBDT 的
訓練過程是通過降低偏差使得分類器的精度升高的。同時也因為高偏差和簡單
的要求,每個分類回歸樹的深度不會很深。最終的總分類器是將每輪訓練得到
的弱分類器加權求和得到的。由于模型中的弱學習器采用分類回歸樹,因此這
個模型可以解決回歸問題或分類問題。
 ?
?
?GBDT的主要思想是:每一次建立單個學習器時,基于以往已建立模型的損
失函數的梯度?降方向優化。我們都知道損失函數越大,模型越容易出錯。如
果我們的模型能夠讓損失函數持續?降,則說明我們的模型在不停地往好的方
向改進。而最好的?降方式就是讓損失函數在其梯度的方向?降。
我們用一個形象的例子說明。假設小李忘記了每個月自己手機流量有多
少,他想通過自己的使用情況測試總量。于是第一輪他?載了一部360MB的電
影,發現還有流量;第二輪?載了一部120MB的短片,發現還有流量;第三輪
他又?載了一本20MB的小說,發現流量終于用完了。如果此時還沒有得出結
果,則可以繼續迭代。每一輪迭代,都會往結果?近一步,最終加權所有的結
果就能夠得出流量總共有 500MB,這就是GBDT的工作方式。
再用一個例子說明GBDT和傳統決策樹之間的區別。以選房為例,假設A、
B、C、D是在市區內的四套房子,面積分別是70、80、120、130平方米。其中
A、B房子距離地鐵站都在500米以內,C、D房子則距離地鐵站比較遠。A、C房
子都在13樓以上,B、D 房子都在 13 樓以?。如果用一棵傳統的回歸決策樹
幫助我們選房,結果如圖9-11所示。????????

?現在我們使用 GBDT 算法來選房。由于數據太少,我們限定葉子節點最多
有兩個,即每棵樹都只有一個分支,并且限定只生成兩棵樹,這樣能夠得到如
圖 9-12 所示結果。

第一棵樹分支如上圖所示,首先還是將A、B分為一類,C、D分為一類。然
后用平均面積作為預測值,分別計算每個結果的?差,A 的?差為:70-
75=-5。此處需要注意,A的預測值是指前面所有樹累加的和,在這個例子中只
有一棵樹,所以結果直接為75。如果前面還有樹,則需要都累加起來作為A的
預測值。
同理可得A、B、C、D的?差分別為-5、5、-5、5。在第二輪迭代時,我們
拿上一輪得到的?差替代 A、B、C、D 原有的值。如果預測值和它們的?差相
等,只需把第二棵樹的結果累加到第一棵樹上就能得到真實的房屋面積了。第
二棵樹有兩個值5和-5,直接分成兩個節點。此時所有房子面積的?差都是0,
即每間房子面積的真實值都被預測出來了。
從上述例子可以看出 GBDT 算法與決策樹的區別,雖然兩者最后得到的結
果相同,但是決策樹算法使用了三個特征,GBDT算法只使用了兩個特征。在實
際項目中, GBDT可能只使用10個特征就能夠擬合出決策樹使用30個特征的效
果。在面對新數據時,顯然使用特征更少的算法產生過擬合現象的概率更低。
并且 GBDT 算法不是簡單的一刀切,而是通過不斷減小誤差的方法逐漸?近真
實值,能夠獲得更精確的預測結果。因其優異的性能,GBDT目前被廣泛用于欺
詐檢測、交易風險評估、搜索結果排序、文本信息處理、信息流排序等領域。
?
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态









![[Classic AUTOSAR学习] DLT模块(LogTrace)](https://img-blog.csdnimg.cn/img_convert/741a22837c882ba5e49acbcbc983c2f9.jpeg)
