參考:bagging和boosting算法(集成學習算法)
? ? ? ? ? ? ? ??Bagging算法和Boosting區別和聯系
? ? ? ? ? ? ? ??機器學習筆記-集成學習之Bagging,Boosting,隨機森林三者特性對比
目錄
1. 集成學習
2. bagging算法?
2.1 bagging算法思想?
2.2 bagging算法特點
2.3 bagging算法案例?
3. boosting算法?
3.1 boosting算法的基本思想?
3.2 代表算法
3.3 boosting算法的案例?
4 Bagging和Boosting算法的區別?
4.1 樣本選擇:
4.2 樣例權重:
4.3 預測函數:
4.4 并行計算:
? ? ? ?集成中只包含同種類型的個體學習器,這樣的個體學習器稱為“基學習器”,相應地學習算法為“基學習算法”,例如決策樹集成中全是決策樹,神經網絡集成中全是神經網絡。(基學習器也稱為弱學習器)
? ? ? ?集成中包含不同類型的個體學習器,這樣的每個個體學習器稱為“組件學習器”,此時不再有“基學習算法”,例如同時包含決策樹和神經網絡
? ? ? ? (1)序列化方法:個體學習器間存在強大依賴關系、必須串行生成,代表算法:Boosting;
? ? ? ? (2)并行化方法:個體學習器間不存在依賴關系、可同時生成,代表算法Bagging和隨機森林。
集成學習是構建多個學習器并通過一定的策略結合成一個性能更佳的學習器。
bagging是bootstrap aggregating的縮寫,是一種并行集成算法。該算法的思想分別構造多個基學習器(弱學習器),多個基學習器相互之間是并行的關系,通過自助采樣法進行訓練(每個基分類器的每個訓練數據都是從初始的訓練集中有放回隨機抽取),最終將多個基學習器結合。對分類問題采用投票方式,對回歸問題采用簡單平均方法對新示例進行判別。上面的算法思想可通過下圖來進行理解:?
自助采樣法
在含有 m 個樣本的數據集中,有放回地重復隨機抽取一個樣本,共抽取n次。創建一個與原數據大小相同的數據集,這個新數據集就是訓練集。這樣有些樣本可能在訓練集中出現多次,有些則可能從未出現。原數據集中大概有 36.8% 的樣本不會出現在新數據集中。因此,我們把這些未出現在新數據集中的樣本作為驗證集。
為什么原數據集中大概有 36.8% 的樣本不會出現在新數據集中?假設數據集中有m個樣本,那么每次每一個樣本被抽取到的概率是1/m,抽樣m次,某個樣本始終不被抽取到的概率是(1-1/m)m。當m的取值趨近于無窮大時,樣本未被抽中的概率為e的負一次方 ,結果約等于0.368。
算法的基本流程為:?
??輸入為樣本集D={(x1,y1),(x2,y2),…(xm,ym)},弱分類器迭代次數為T。?輸出為最終的強分類器f(x)
??(1)對于t=1,2…,T:
? ? ? ? ? ? ? ?(a)對訓練集進行隨機采樣,共采集m次,得到包含m個樣本的采樣集Dm;
? ? ? ? ? ? ? ?(b)用采樣集Dm訓練第t個弱學習器Gt(x);?
??(2) 如果是分類算法預測,則T個弱學習器投出最多票數的類別或者類別之一為最終類別。如果是回歸算法,T個弱學習器得到的回歸結果進行算術平均得到的值為最終的模型輸出。?
(1)bagging算法更傾向于以偏差低、方差高的模型作為基學習器,如決策樹、神經網絡,通過增加樣本擾動,可以增強融合后模型的泛化能力,降低方差。
(2)其性能依賴于基分類器的穩定性;若采用的是不穩定基學習器,bagging有助于降低訓練數據的隨機波動導致的誤差,即增強了穩定性和泛化能力;若采用的是穩定基學習器,則集成分類器的誤差主要由基分類器的偏差引起(見為什么更傾向于融合低偏差的模型);?
(3)由于每個樣本被選中的概率相同,因此bagging并不側重于訓練數據集中的任何特定實例。
1.為什么bagging可以降低方差?
方差刻畫了模型對數據擾動的敏感程度,越敏感說明數據的微小變動就能導致學習出的模型產生較大差異,因而方差大。
我們將容易受到數據干擾(方差高)的模型稱為不穩定模型,如決策樹、神經網絡,而SVM就是典型的穩定學習器(很容易理解,SVM的超平面僅由支持向量決定,增加一個擾動數據,并不會對決策面產生影響)。
我們假設有n個獨立同分布的基學習器,每個基學習器的方差為σ2,對一個樣本的預測值為
的。那么bagging的輸出就是將每個基學習器的預測值求以平均,即
,根據獨立隨機變量的方差特性,對其求取方差有:
但是實際上Bagging的抽樣是有放回抽樣,這樣數據集之間會有重復的樣本,因而違反了上式子的獨立性假設。在這種情況下設單模型之間具有相關系數?0<ρ<1,則實際的方差為:
上式中隨著n增大,第一項趨于0,第二項趨于ρσ2,所以Bagging能夠降低整體方差。
2.為什么更傾向于融合低偏差的模型?
設單模型的期望為μ,則Bagging的期望預測為:
說明Bagging整體模型的期望近似于單模型的期望,這意味整體模型的偏差也與單模型的偏差近似,所以Bagging通常選用偏差低的強學習器。?
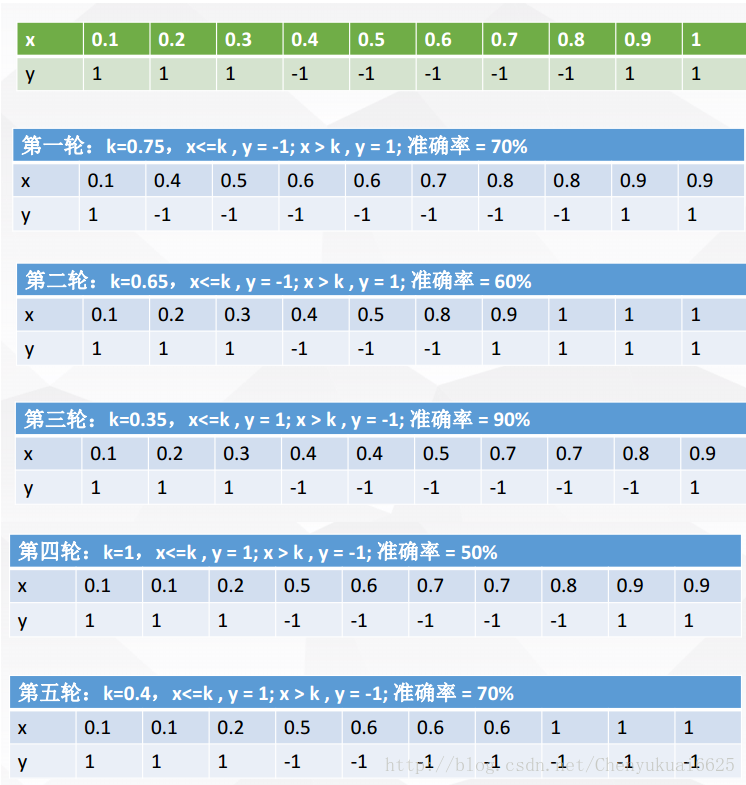
? ? ? ? 為了更好理解bagging的概念,提供下面一個例子。?
? ? ? ? ?X 表示一維屬性,Y 表示類標號(1或-1)測試條件:當x<=k時,y=?;當x>k時,y=?;k為最佳分裂點?
??下表(綠色)為屬性x對應的唯一正確的y類別。?
? ? ? ? ?現在進行5輪隨機抽樣(藍色),結果如下:?
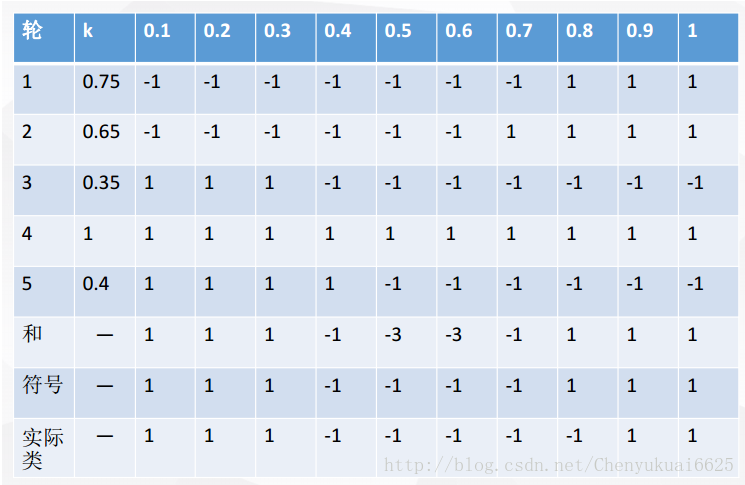
??每一輪隨機抽樣后,都生成一個分類器。然后再將五輪分類融合。?
??對比符號和實際類,我們可以發現:在該例子中,Bagging使得準確率可達90%。
? ? ? ? boosting算法是Adaptive boosting的縮寫,是一種迭代算法。每輪迭代中會在訓練集上產生一個新的分類器,然后使用該分類器對所有樣本進行分類,以評估每個樣本的重要性(informative)。?
廣義的定義:
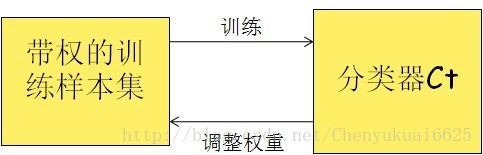
? ? ? ? 算法會為每個訓練樣本賦予一個權值。每次用訓練完的新分類器更新訓練樣本的權重,若某個樣本點已被分類正確,則將其權值降低,若樣本點分類錯誤,則提高其權值,使得先前基學習器做錯的訓練樣本在后續受到更多關注。整個迭代過程直到錯誤率足夠小或達到一定次數T才停止,最終將這T個基學習器進行加權結合。

準確的定義:?
Boosting算法是將“弱學習算法“提升為“強學習算法”的過程。Boosting算法要涉及到兩個部分,加法模型和前向分步算法。加法模型就是說強分類器由一系列弱分類器線性相加而成。一般組合形式如下:

其中,![]() 就是一個個的弱分類器,
就是一個個的弱分類器,![]() 是弱分類器學習到的最優參數,βm就是弱學習在強分類器中所占比重,P是所有
是弱分類器學習到的最優參數,βm就是弱學習在強分類器中所占比重,P是所有![]() 和βm的組合。這些弱分類器線性相加組成強分類器。
和βm的組合。這些弱分類器線性相加組成強分類器。
前向分步就是說在訓練過程中,下一輪迭代產生的分類器是在上一輪的基礎上訓練得來的。也就是可以寫成這樣的形式:
![]()
由于采用的損失函數不同,Boosting算法也因此有了不同的算法,代表有adaboost。
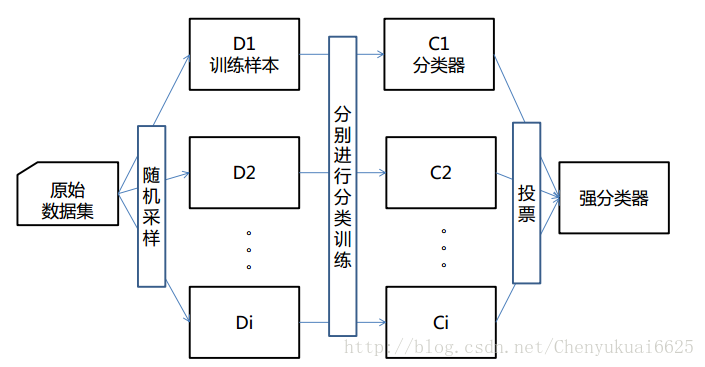
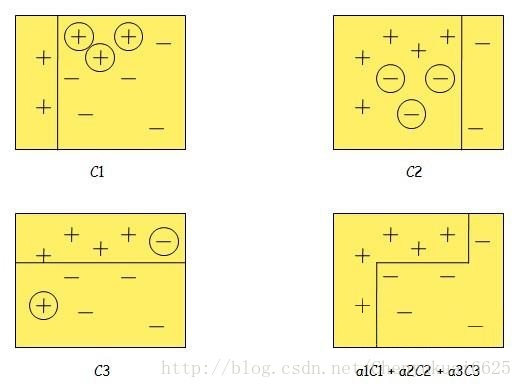
? ? ? ? 以下圖為例,來說明boosting算法的核心思想:
? ? ? ? ?由圖可以發現,boosting算法在迭代的過程中不斷加強識別錯誤樣本的學習比重,從而實現最終的強化學習。
(1)樣本選擇:
(2)樣例權重:
(3)預測函數:
(4)并行計算:
()預測結果:
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











![[转载]逆向工程不是炫耀者用来装B的工具](/upload/rand_pic/2-1359.jpg)


