白噪聲(white noise)是指功率譜密度在整個頻域內均勻分布的噪聲。 所有頻率具有相同功率密度的隨機噪聲稱為白噪聲。
按幅度分布方式又可以分為均勻分布和高斯分布。
均勻分布百度百科
在概率論和統計學中,均勻分布也叫矩形分布,它是對稱概率分布,在相同長度間隔的分布概率是等可能的。 均勻分布由兩個參數a和b定義,它們是數軸上的最小值和最大值,通常縮寫為U(a,b);
屬性:
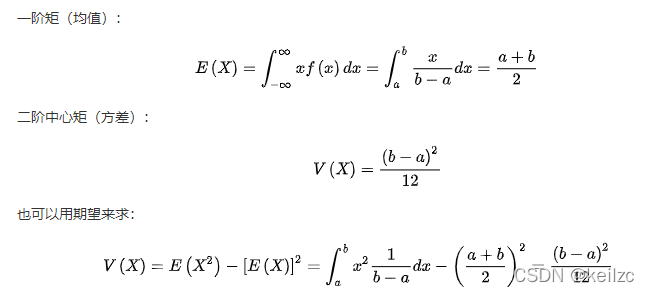
rand函數用來產生(0, 1)之間均勻分布的隨機數組成的數組,即單位均勻分布。
Y = rand(n) 返回一個n x n的隨機矩陣。如果n不是數量,則返回錯誤信息。
Y = rand(m,n) 或 Y = rand([m n]) 返回一個m x n的隨機矩陣。
Y = rand(m,n,p,…) 或 Y = rand([m n p…]) 產生隨機數組。
Y = rand(size(A)) 返回一個和A有相同尺寸的隨機矩陣。
根據1.1章節可知,rand函數生成的數據均值為(0+1)/2=0.5;方差(功率)為1/12。
n=10000;
x=rand(1,n); %產生(0-1)單位均勻信號,1行,n列
subplot(211)
plot(x); %輸出信號圖
set(gca,'FontSize',20);
title('0-1服從均勻分布的隨機序列信號');
subplot(212)
hist(x,50)
set(gca,'FontSize',20);
title('0-1服從均勻分布的隨機序列直方圖');

驗證其均值為0.5,方差(功率)為1/12,即0.08333。
mean_x = mean(x) %驗證均值為0.5
power_x = var(x) %驗證功率為1/12
運行結果:
mean_x =
0.4987
白噪聲的自相關函數?power_x =
0.0831
符合要求。
實現均值為1,功率為8.3333的均勻分布噪聲
方法1:
p = 8.3333;
N = 10000;
average = 1;
temp1 = rand(1, N); %產生(0-1)單位均勻信號,1行,n列
temp2 = temp1 - mean(temp1);%減去均值,得到均值為0
temp3 = temp2 * sqrt(p*12);%調整幅度,改變功率,默認功率為1/12
x = temp3 + average; %調整均值
figure
plot(x);
set(gca,'FontSize',20);
title('服從均勻分布的隨機序列信號');

驗證其均值為1,方差(功率)為8.3333。
power_x = var(x)
mean_x = mean(x)
運行結果:
白噪聲與高斯白噪聲的區別?power_x =
8.4519
mean_x =
1.0000
符合要求。
方法2:
rand函數默認均值為0.5,功率為0.083333,分析目標信號,獲取上下限a、b即可:目標信號均值為1,即(a+b)/2=1;功率為8.3333,相比于單位均勻分布的功率增大100倍,即對應幅度增大10倍,因此b-a=10*(1-0),計算得b=6,a=-4
a=-4; %(a-b)均勻分布下限
b=6; %(a-b)均勻分布上限
fs=1e6; %采樣率,單位:Hz
t=1e-2; %隨機序列長度,單位:s
n=t*fs;
rand('state',0); %把均勻分布偽隨機發生器置為0狀態
u=rand(1,n); %產生(0-1)單位均勻信號,1行,n列
x=(b-a)*u+a; %廣義均勻分布與單位均勻分布之間的關系
subplot(211);
plot(x); %輸出信號圖
set(gca,'FontSize',20);
title('服從均勻分布的隨機序列信號');
subplot(212)
hist(x,50)
set(gca,'FontSize',20);
title('服從均勻分布的隨機序列直方圖');

驗證其均值為1,方差(功率)為8.3333。
power_x = var(x) %驗證功率
mean_x = mean(x) %驗證均值
運行結果:
mean_x =
1.0515
均勻分布的白噪聲通過線性系統。power_x =
8.4122
符合要求。
高斯分布百度百科
正態分布(Normal distribution),也稱“常態分布”,又名高斯分布(Gaussian distribution),正態曲線呈鐘型,兩頭低,中間高,左右對稱因其曲線呈鐘形,因此人們又經常稱之為鐘形曲線。
若隨機變量X服從一個數學期望為μ、方差為σ2的正態分布,記為N(μ,σ2)。其概率密度函數為正態分布的期望值μ決定了其位置,其標準差σ決定了分布的幅度。當μ = 0,σ = 1時的正態分布是標準正態分布。
matlab語法與rand函數基本一致,所不同的是,randn產生的數值服從正態分布,即均值為0,方差為1。
y=randn(1,10000); subplot(2,1,1);plot(y); set(gca,'FontSize',20);
title('服從高斯分布的隨機序列信號'); subplot (2,1,2);hist(y,50); set(gca,'FontSize',20);
title('服從高斯分布的隨機序列直方圖');

驗證其均值為0,方差為1。
power_y = var(y) %驗證功率
mean_y = mean(y) %驗證均值
運行結果:
power_y =
0.9823
高斯白噪聲服從什么分布、mean_y =
0.0088
符合要求。
產生一個隨機分布的指定均值和方差的偽隨機數:將randn產生的結果乘以標準差,然后加上期望均值即可。例如,產生均值為2,方差為0.01的一個1×10000隨機數,方式如下:
temp = randn(1,10000);var_value= 0.01;average = 2;y=temp*sqrt(var_value) + average;subplot(2,1,1);plot(y); set(gca,'FontSize',20);
title('服從高斯分布的隨機序列信號'); subplot (2,1,2);hist(y,50); set(gca,'FontSize',20);
title('服從高斯分布的隨機序列直方圖');

驗證其均值為2,方差為0.01。
power_y = var(y) %驗證功率
mean_y = mean(y) %驗證均值
運行結果:
power_y =
0.0099
白噪聲的均值等于0么。mean_y =
2.0004
符合要求。
語法:
R=normrnd(MU,SIGMA)
R=normrnd(MU,SIGMA,m)
R=normrnd(MU,SIGMA,m,n)
說 明:
R=normrnd(MU,SIGMA):生成服從正態分布(MU參數代表均值,SIGMA參數代表標準差)的隨機數。輸入的向量或矩陣MU和SIGMA必須形式相同,輸出R也和它們形式相同。標量輸入將被擴展成和其它輸入具有 相同維數的矩陣。
R=norrmrnd(MU,SIGMA,m):生成服從正態分布(MU參數代表均值,SIGMA參數代表標準差)的 隨機數矩陣,矩陣的形式由m定義。m是一個1×2向量,其中的兩個元素分別代表返回值R中行與列的維數。
R=normrnd(MU,SIGMA,m,n): 生成m×n形式的正態分布的隨機數矩陣。
clear
clc
close all
y=normrnd(2,0.1,1,10000); %第一個參數均值,第二個參數標準差,第三、四參數行數和列數
%目標信號方差為0.01,即標準差0.1subplot(2,1,1);plot(y)
set(gca,'FontSize',20);
title('均值為2,方差為0.01服從高斯分布的隨機序列信號');
subplot (2,1,2);hist(y,50); set(gca,'FontSize',20);
title('均值為2,方差為0.01服從高斯分布的隨機序列直方圖');

power_y = var(y) %驗證功率
mean_y = mean(y) %驗證均值
白噪聲與熱噪聲、power_y =
0.0100
mean_y =
2.0019
符合要求。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态







![[论文阅读]《Discovering Graph Functional Dependencies》阅读笔记](https://img-blog.csdnimg.cn/20201226184241732.png)



