我们先来选定爬取目标,我爬取的网站是https://www.17k.com/ ,一些大型的网站(如起点、豆瓣等)做了反爬虫的部署,这会大大增加我们抓取的难度,所以尽量还是选一些不那么热门的网站。
爬虫的第一步,也是最重要的一步,就是分析网页的结构,定位到我们想要抓取的内容。首先点开一本书的某一章节,这里以小说《第九特区》的第一章《初来乍到》为例展开(https://www.17k.com/chapter/3038645/38755562.html),分析某一章的页面内容结构。
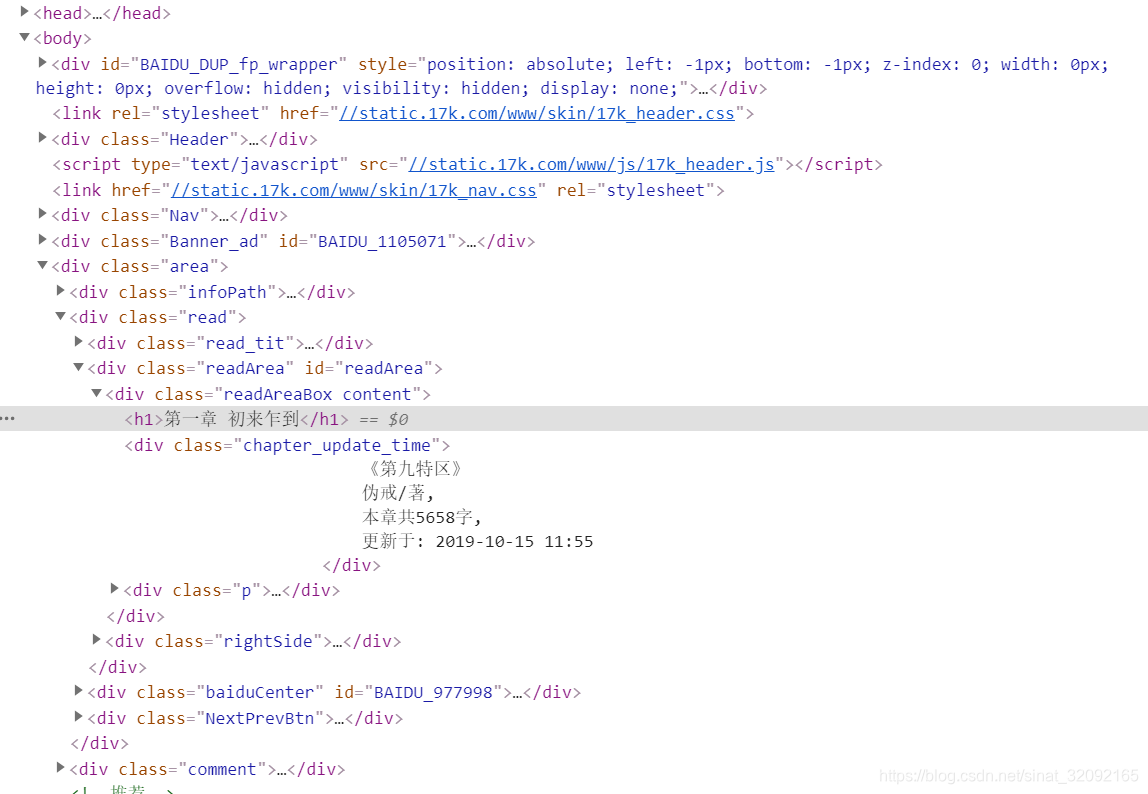
爬虫如何抓取网页数据、首先来看标题,这个非常简单,标题直接存在于<h1>标签中,我们指导html中<h1>通常是用来标记主标题的,那么理所当然<h1>标签应该只有一个,所以直接放心的用BeautifulSoup的select()方法将找到的第一个<h1>标签找到即可,里面的文本内容就是这一章的标题。主要代码如下:
title = bs.select('h1')[0]得到了标题,我们再来看正文。

不难发现,所有的文章正文都被包裹在了一个class为“p"的<div>标签里,这个div应该就是用来封装所有正文内容的。所以,我们通过select方法找到CSS类名为”p“的<div>标签,在将里面所有的<p>标签找到,提取出文本内容即可。主要代码如下:
body = bs.select('div.p')[0]paragraphs = body.find_all('p')content = []for p in paragraphs:content.append(p.text)content.append("\n")python为什么叫爬虫。
这里用了一个列表来存储所有的段落,并且在每一段后面手动添加了换行"\n"。这样操作的好处是,后面保存文件的时候可以一次性写入,节省了IO的时间。
基于以上的核心代码,再配合上文件读写,url请求等常见操作,我们就可以写出得到一个章节的全部内容并保存的代码getASection,代码如下
def getASection(url,bookName):bookName+=".txt"f = open(bookName,"a",encoding='utf-8')#利用追加的方式打开文件,这样后面章节的内容不会覆盖前面章节rsp = requests.get(url,headers = headers)rsp.encoding = 'utf-8'bs = BeautifulSoup(rsp.text,'html.parser')title = bs.select('h1')[0]f.write(title.text)f.write("\n")# print(title.text)body = bs.select('div.p')[0]paragraphs = body.find_all('p')content = []for p in paragraphs:content.append(p.text)content.append("\n")f.writelines(content)f.close()测试以上代码,没有问题,这就完成了项目的第一步,得到得到一个章节的全部内容并保存成txt。那么接下来的任务是什么?就是将一本书的全部章节的链接获取,再分别对这些链接调用上面的函数getASection,就可以得到一本书的全部内容了。
利用爬虫数据做论文,为此,我们来分析一本书全部章节的页面,看看用怎样的方式,来得到每个章节的链接。

分析html代码,发现所有章节都包裹于类名为”Volume“的<dl>标签中

python爬小说,所以,我们可以先用select方法找到class为”Volume"的dl标签:
sections = bs.select('dl.Volume')[0]然后,再在这里面找到所有的a标签,其中的链接就在href属性中。
sections = bs.select('dl.Volume')[0]links = sections.select('a')我们将每一个章节的url作为参数传入第一个函数getASection中,就可将一本书的全部内容保存了。得到一本书全部章节的函数getSections代码如下:
def getSections(url,bookName):rsp = requests.get(url,headers = headers)rsp.encoding = 'utf-8'bs = BeautifulSoup(rsp.text,'html.parser')sections = bs.select('dl.Volume')[0]links = sections.select('a')del links[0]#第一个a标签为“收起”,将其删除for link in links:if link.attrs["href"] is not None:newUrl = urljoin(url,link.attrs['href'])getASection(newUrl,bookName)分析我们之前构造的两个函数,第一个函数getASection可以保存一个章节的全部内容,第二个函数getSections可以得到所有的章节,并调用函数getASection分别保存每个章节,这样只需要调用第二个函数getSections,就可以得到一本小说的全部内容了。
利用爬虫赚钱?那么,如果我们想保存全站(部分)的小说内容,需要怎么做?
基于相同的逻辑,如果找到一个页面,里面存有各个小说的链接,将这里链接分别作为参数,调用上一个函数getSections,不是就可以得到所有书的内容了?
在主页中,就保存着不同书的目录。

爬虫分析。我们以“男生作品电击榜”为例,来分析这个目录下的书的链接如何得到。其余的目录同理可以获得。

观察html代码,可以发现,所有的书的链接被包裹在类名为“NS_CONT” 和 "Top1" 的ul标签下。在这个标签下,第二个<a>标签存放着书名和这本书相对应的链接。那么如何找到第二个<a>标签?我们可以先找到第一个<a>标签,然后通过find_next()方法找到第二个<a>结点即可。
bookList = bs.select('ul.NS_CONT.Top1')[0]sorts = bookList.select('a.sign')for sort in sorts:book = sort.findNext('a')
获取一个目录下所有小说的函数getBooks()代码如下:
def getBooks(url):bookUrls = dict() #用字典来存放小说信息,键为书名,值为链接地址rsp = requests.get(url,headers = headers)rsp.encoding = 'utf-8'bs = BeautifulSoup(rsp.text,'html.parser')bookList = bs.select('ul.NS_CONT.Top1')[0]sorts = bookList.select('a.sign')for sort in sorts:book = sort.findNext('a')if book.attrs['href'] is not None:href = 'http:'+book.attrs['href']href = href.replace('book','list')#需要把url中的book替换为list,直接进入章节页面bookName = book.textif bookName not in bookUrls:bookUrls[bookName] = href# print("{}:{}".format(bookName,href))for bookName in bookUrls.keys():getSections(bookUrls[bookName],bookName)python 爬虫、通过getBooks()函数,我们一次可以得到一个目录下的多本书的地址,并且将url作为参数分别调用函数getSections,这样就可以一次保存多本书的内容了。
最后,将网站主页作为参数,主函数中调用getBooks即可:
getBooks('https://www.17k.com/')全部代码如下:
from bs4 import BeautifulSoup
import requests
from requests.compat import urljoin
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}def getASection(url,bookName):bookName+=".txt"f = open(bookName,"a",encoding='utf-8')#利用追加的方式打开文件,这样后面章节的内容不会覆盖前面章节rsp = requests.get(url,headers = headers)rsp.encoding = 'utf-8'bs = BeautifulSoup(rsp.text,'html.parser')title = bs.select('h1')[0]f.write(title.text)f.write("\n")body = bs.select('div.p')[0]paragraphs = body.find_all('p')content = []for p in paragraphs:content.append(p.text)content.append("\n")f.writelines(content)f.close()def getSections(url,bookName):rsp = requests.get(url,headers = headers)rsp.encoding = 'utf-8'bs = BeautifulSoup(rsp.text,'html.parser')sections = bs.select('dl.Volume')[0]links = sections.select('a')del links[0]#第一个a标签为“收起”,将其删除for link in links:if link.attrs["href"] is not None:newUrl = urljoin(url,link.attrs['href'])getASection(newUrl,bookName)def getBooks(url):bookUrls = dict() #用字典来存放小说信息,键为书名,值为链接地址rsp = requests.get(url,headers = headers)rsp.encoding = 'utf-8'bs = BeautifulSoup(rsp.text,'html.parser')bookList = bs.select('ul.NS_CONT.Top1')[0]sorts = bookList.select('a.sign')for sort in sorts:book = sort.findNext('a')if book.attrs['href'] is not None:href = 'http:'+book.attrs['href']href = href.replace('book','list')#需要把url中的book替换为list,直接进入章节页面bookName = book.textif bookName not in bookUrls:bookUrls[bookName] = href# print("{}:{}".format(bookName,href))for bookName in bookUrls.keys():getSections(bookUrls[bookName],bookName)getBooks('https://www.17k.com/')
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态







![Elasticsearch错误 “low disk watermark [85%]”或“high disk watermark [90%]”](/upload/rand_pic/2-952.jpg)



