创建好的项目
python为什么叫爬虫、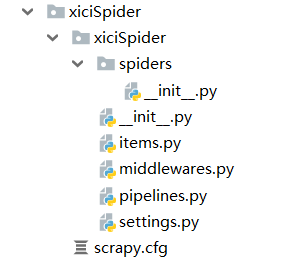
一定要先进入刚才创建的爬虫项目文件中再创建爬虫
python ip地址处理。


对比未创建爬虫,发现多了一个xici.py文件




可以参考我以前的博客
(1)正则表达式
(2)Xpath:从html中提取数据的语法
(3)CSS:从html中提取数据语法
(4)BeautifulSoup


selectors = response.xpath('//tr') # 先选择所有的tr标签
for selector in selectors:# 第一种获取方法get()ip = selector.xpath('./td[2]/text()').get() # get表示获取一个元素,getall表示获取所有元素port = selector.xpath('./td[3]/text()').get()# 第二种获取方法extract()ip = selector.xpath('./td[2]/text()').extract_first() # extract_first表示获取第一个元素,extract表示获取所有元素port = selector.xpath('./td[3]/text()').extract_first()

import scrapy # 导入scrapy# 创建爬虫类,并且继承自scrapy.Spider类(最基础的类,另外几个类都继承自这个)
class XiciSpider(scrapy.Spider):name = 'xici' # 爬虫名字 必须唯一allowed_domains = ['xicidaili.com'] # 允许采集的域名start_urls = ['https://www.xicidaili.com/nn/5'] # 开始采集的网站# 解析响应数据,提取数据或网址等 response就是网页源码def parse(self, response):"""提取数据"""# 提取IPselectors = response.xpath('//tr') # 先选择所有的tr标签for selector in selectors:ip = selector.xpath('./td[2]/text()').get() # get表示获取一个元素,getall表示获取所有元素port = selector.xpath('./td[3]/text()').get()# ip = selector.xpath('./td[2]/text()').extract_first() # extract_first表示获取第一个元素,extract表示获取所有元素# port = selector.xpath('./td[3]/text()').extract_first()print(ip, port)


# 翻页处理(找到“下一页”的源代码)next_page = response.xpath('//a[@class="next_page"]/@href').get()if next_page:# 拼接网址next_url = 'https://www.xicidaili.com' + next_page# 发出请求Request ,callback表示回调函数,将请求得到的响应交给自己处理yield scrapy.Request(next_url, callback=self.parse) # 生成器
可以将文件保存在json格式、html格式、csv格式等的文件中
scrapy crawl xici -o ip.json

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态