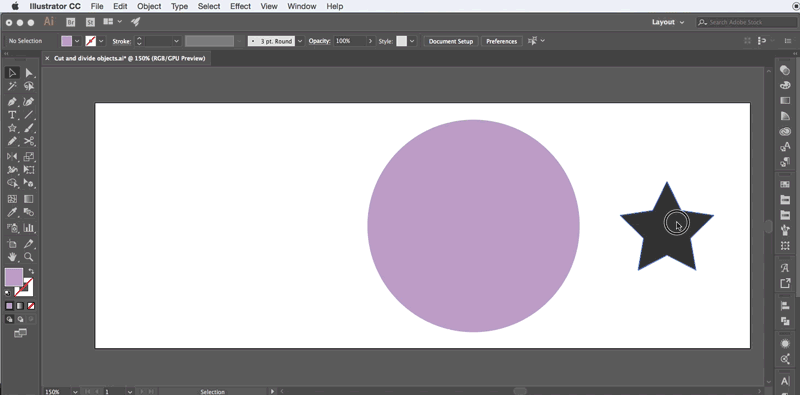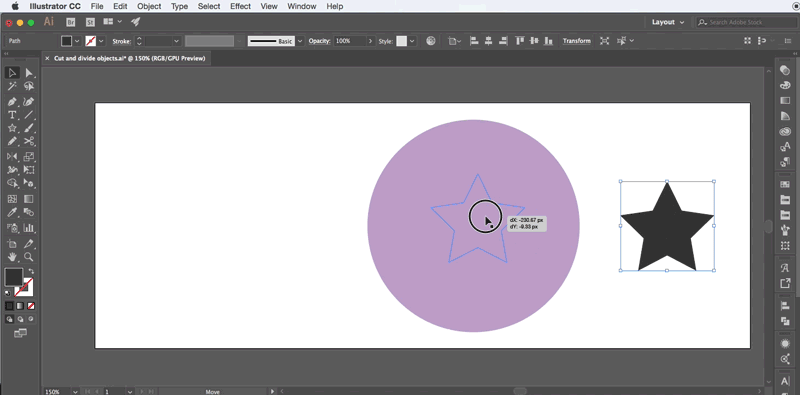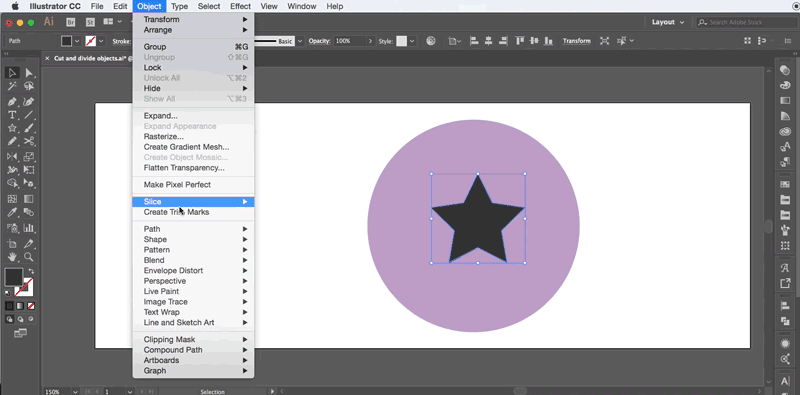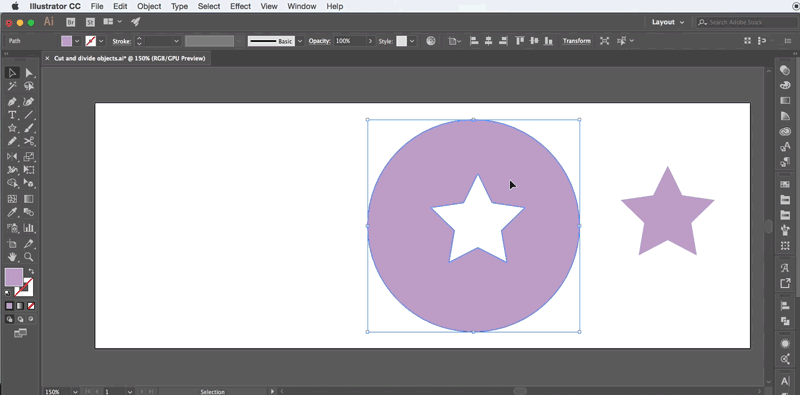
在这里小龙只提供一个可用的方法,具体代码需要亲们自主开发,小龙开发的不便放出,请见谅!
小龙在这里使用的语言是Python,版本是3.6.3,这里使用并发写入效果比较好的mongodb来存储数据。
用到的模块:
selenium
time
random
urllib
json
pymongo
hashlib
阿里妈妈的登录链接为:
https://login.taobao.com/member/login.jhtml?style=minisimple&from=alimama&full_redirect=false&c_isScure=false&quicklogin=true&forward=https%3A%2F%2Fwww.alimama.com%2Findex.htm
校验登录状态的链接为:
http://pub.alimama.com/common/getUnionPubContextInfo.json
获取JSON订单的接口为:
https://pub.alimama.com/report/getTbkPaymentDetails.json?startTime=20171219&endTime=20171219&payStatus=&queryType=1&toPage=1&perPageSize=20&total=&t=1503223605295&pvid=&_tb_token_=pTK7Mfldfvq&_input_charset=utf-8
订单接口链接部分参数说明:
startTime:获取订单列表的开始时间
endTime:获取订单列表的结束时间
payStatus:订单状态(12:已付款,13:已取消,3:已成交)
toPage:第几页
程序的设计思路为,首先使用登录地址,借助seleninm进行阿里妈妈登录,然后通过校验登录状态的链接进行登录判断,判断成功后,使用订单接口进行订单数据获取,获取到的数据为JSON格式,使用Python进行循环插入到数据库就可以了。
至于翻页问题,可以在获取到数据后进行数据数量判断,如果数量为20,则Page加1,继续执行此函数就可以了。
注意:在登录及获取数据的时候,一定要加一定时间的延迟,以避免阿里妈妈进行IP封禁。
如果有疑问,欢迎入群一起交流:611836627
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态