?一、基礎數據類型
基礎數據類型,有7種類型,存在即合理。
char是什么數據類型,?
1.int 整數
python 前端?主要是做運算的 。比如加減乘除,冪,取余? + - * / ** %...
2.bool 布爾值
判斷真假以及作為條件變量
3.str 字符串
python str、存儲少量的數據。‘太白’,'password'... 操作簡單,便于傳輸。
4.list?列表
?[1,2,'alex',{name:'zhang'}] 存放大量的數據,大量的數據放到列表中便于操作
5.tuple 元組
也叫只讀列表。(1,2,'alex',{name:'zhang'}) 一些重要的數據或者不想被更改的數據,使用元組
6.dict 字典
{‘name_list’:'[zhang,lisi]'},存儲關系型的數據,查詢速度非常快,二分查找。
7.set 集合
交集,并集,差集...
?
分別舉例
int整形
i = 4
#轉化成二進制的最小位數
print(i.bit_length())
'''
1 0000 0001
1 0000 0010
3 0000 0011
4 0000 0100
'''
執行輸出: 3
?
str 這里就不舉了
bool 布爾值
說一下
數據類型轉換:
int --> str
n = str(1)執行輸出: 1
int --> bool
n = bool(1)
執行輸出: True
str --> bool
n = bool('')
執行輸出:?False
空字符串是False,其他都是True?
?
str 字符串索引與切片
先講索引
字符串是有序的,有索引的,索引從0開始,默認取值是從左至右
s = 'python是最好的語言'
#取第一個字符
s1 = s[0]
#取索引值為2的元素
s2 = s[2]
#最后一個
s3 = s[-1]
print(s1)
print(s2)
print(s3)
執行輸出:
p
t
言
?
切片
語法:?
[起始索引:截止索引:步長]
步長默認為1,表示從頭開始取
切片,也就是取連續的多個值
切片原則,顧頭不顧尾
什么意思?舉例說明
s = 'python是最好的語言'
s1 = s[0:2]
print(s1)
執行輸出:
py
?
先看字符串的索引對應
p? y? t? h? o? n
↓? ↓? ↓? ↓? ?↓? ↓
0 1? 2? 3? 4? 5
?
我是取 0~2 的,發現t沒有顯示出來,因為根據切片原則,末尾的不顯示
如果想輸出末尾的,需要加1即可。比如s[0:3]
?
中文字符串也是同樣的,一個中文字,即一個索引
s = 'python是最好的語言'
s1 = s[7:9]
print(s1)
執行輸出:
最好
?
全取
s = 'python是最好的語言'
s1 = s[:]
print(s1)
執行輸出:
python是最好的語言
?
切片會產生新的變量,在內存中,原字符串和切片后的字符串,是2個變量
s4 = s[:] 雖然結果是一樣的,但它是2個變量
對字符串操作,都會產生新的變量,除了賦值以外。
?
取最后5個字符串
s = 'python是最好的語言'
s1 = s[-5:]
print(s1)
執行輸出:
最好的語言
?
步長
默認步長為1
隔一個取1個,步長為2
反向取值,也就是從后向前取,步長為-1
?
隔1個,取一個
s = 'python是最好的語言'
s1 = s[::2]
print(s1)
執行輸出:
pto是好語
?
反向取5個
s = 'python是最好的語言'
s1 = s[:-5:-1]
print(s1)
執行輸出:
言語的好
?
反向全取
s = 'python是最好的語言'
s1 = s[::-1]
print(s1)
執行輸出:
言語的好最是nohtyp
?
字符串常用操作方法
用以下?表示使用程度
??? 非常
?? 常用
? 一般
?
???capitalize()??首字母大寫,其他字母小寫
s = 'laoshi'
s1 = s.capitalize()
print(s1)
執行輸出:
Laoshi
?
???upper()? 全部大寫
???lower()? 全部小寫
s = 'laoshi'
s1 = s.upper()
s2 = s.lower()
print(s1)
print(s2)
執行輸出:
LAOSHI
laoshi
?
比如驗證碼判斷功能
code = 'aeQu'
your_code = input('請輸入驗證碼:')
if your_code == 'aequ' or your_code == 'Aequ'...
如果不使用字符串內置方法,這需要寫16個if,代碼質量非常low
下面使用字符串內置方法
code = 'aeQu'
your_code = input('請輸入驗證碼:')
if your_code.upper() == code.upper():print('驗證碼驗證成功')
執行輸出:

代碼優化一下
code = 'aeQu'.upper()
your_code = input('請輸入驗證碼:').upper()
if your_code == code:print('驗證碼驗證成功')
執行效果同上
?
?center()? 居中
s = 'laoshi'
#總寬度為30,并且字符串居中,不足30,默認用空格填充
s1 = s.center(30)
#使用*填充
s2 = s.center(30,'*')
print(s1)
print(s2)執行輸出:

如果寬度小于字符串,按照原來的字符串顯示
s = 'laoshi'
s1 = s.center(3)
print(s1)
執行輸出:
laoshi
?
??swapcase() 大小寫反轉
s = 'LaoShi'
s1 = s.swapcase()
print(s1)
執行輸出:
lAOsHI
?
??title() 每個單詞的首字母大寫(非字母隔開)
s = 'xiao wusir*nanhai21shui'
s1 = s.title()
print(s1)
執行輸出:
Xiao Wusir*Nanhai21Shui
?
???startswith() 判斷以什么為開頭
???endswith() 以什么為結尾
startswith 的start和end參數是切片
如果想取到最后,end參數,不需要指定
s = 'xiao wusir*nanhai21shui'
s1 = s.startswith('a')
s2 = s.endswith('i')
#切片,取索引訪問1~4,再判斷是否以i開頭
s3 = s.startswith('i',1,4)
#切片,取索引范圍5~結束,結束位置參數沒給,默認一直取到尾
s4 = s.startswith('w',5)
print(s1)
print(s2)
print(s3)
print(s4)
執行輸出:
False
True
True
True
?
???strip() 去除首尾的空格,換行符(\n),tab鍵(4個空格 用\t表示)
s = '\nlaoshi\t '
s1 = s.strip()
print(s1)
執行輸出:?laoshi
?
在input程序中,會經常使用
name = input('請輸入用戶名:')
if name == 'xiao':print('ok')
如果用戶輸入的,不小心包含了空格,會導致驗證失敗
下面加入strip()
即使輸入有空格,也可以驗證通過
name = input('請輸入用戶名:').strip()
if name == 'xiao':print('ok')
執行輸出:

?
后續操作文件讀取一行內容的時候,也會帶有換行符,雖然你看不見,使用strip(),就可以去除了
類似功能的2個的方法
?lstrip() 去除左邊的空格、換行符、tab鍵
?rstrip() 去除右邊的空格、換行符、tab鍵
?
strip()還可以去除指定的字符串
s = 'laoshijintianzalill'
#去除字符串l
s1 = s.strip('l')
print(s1)執行輸出:
aoshijintianzali
解釋一下執行過程
??→ string ← ?
strip()相當于??,就像吃豆游戲一樣。
strip()會同時向左右2邊,挨個挨個字符尋找字符串l 如果發現了l,就去除,如果沒有發現,終止尋找,最后輸入結果
比如頭部的lao? 找到了字符串l,開始刪除。再繼續找下一個字符a,發現不匹配,終止尋找
同時,尾部的lill,找到l,開始刪除。繼續找下一個,找到l,刪除。再繼續下一個,發現字符串i,不匹配,終止尋找
最終輸出:?aoshijintianzali
?
???find() 通過元素找索引
還有一個函數index(),也是同樣的功能
不同的是,index()找不到,直接報錯
find()找不到時,會返回-1
s = 'xiaoxx'
s1 = s.find('a')
s2 = s.index('a')
print(s1)
print(s2)執行輸出: 2
?
???count() 尋找元素出現的個數,可切片
s = 'xiaomingtongxue'
s1 = s.count('x')
#從第5個索引一直到最后,尋找字符串o出現的次數
s2 = s.count('o',5)
print(s1)
print(s2)
執行輸出:
2
1
?
???replace() 替換
s = '我的老家在東北,東北有很多人'
#默認是全文替換
s1 = s.replace('東北','黑龍江')
#替換一次
s2 = s.replace('東北','黑龍江',1)
print(s1)
print(s2)
執行輸出:
我的老家在黑龍江,黑龍江有很多人
我的老家在黑龍江,東北有很多人
?
替換,是從左至右的
如果想要替換中間某部分,需要用到正則表達式
?
???split() 分割,將字符串轉換為列表
默認按照空格分隔
s = 'wo zai tai bei'
s1 = s.split()
print(s1)
執行輸出:
['wo', 'zai', 'tai', 'bei']
?
指定分割符
s = 'wo,zai,tai,bei'
s1 = s.split()
print(s1)
執行輸出,效果同上
?
指定字符串a
s = 'awozaiataiabei'
s1 = s.split('a')
print(s1)
執行輸出:
['', 'woz', 'i', 't', 'i', 'bei']
?
注意:如果關鍵字左邊沒有字符串,那么結果為[],也就是空字符串
結果不包含關鍵字,被剔除了
比如面試題:
有下面一段日志,包含了IP地址和時間...需要切割日志
216.244.66.227,[20/Mar/2018:17:03:52 +0800],"Mozilla/5.0"
114.215.45.101,[20/Mar/2018:17:16:30 +0800],"BUbiNG"
106.11.152.107,[20/Mar/2018:17:22:40 +0800],"YisouSpider"
可以用正則表達式,但是比較麻煩,有沒有更簡單的辦法呢?用split(),指定逗號分割,就可以實現
???format() 格式化輸出
這個很牛逼,一定要重點掌握!
有三種用法:
第一種用法:
s = '我叫{},今年{},愛好{}'.format('MT',18,'打怪')
print(s)
執行輸出:
我叫MT,今年18,愛好打怪
{}表示一個占位符
?
第二種用法:
s = '我叫{0},今年{1},愛好{2},我依然叫{0}'.format('MT',18,'打怪')
print(s)
執行輸出:
我叫MT,今年18,愛好打怪,我依然叫MT
?
比如一篇文章,名字出現了幾十次,那么可以直接用個{0}表示
修改format后面的參數,就可以生效了
{0} 表示索引值,如果使用這種方式,索引值必須指定,否則報錯
?
第三種用法:?鍵值對
s = '我叫{name},今年{age},愛好{hobby}'.format(age=18,name='MT',hobby='打怪')
print(s)
執行輸出:
我叫MT,今年18,愛好打怪
?
?isalnum() 字符串由字母或數字組成
?isalpha() 字符串只能由字母組成
???isdigit() 字符串只能由數字組成
name = 'jingsan123'
s1 = name.isalnum()
s2 = name.isalpha()
s3 = name.isdigit()
print(s1)
print(s2)
print(s3)
執行輸出:
True
False
False
?
isdigit()比較常用,比如判斷用戶輸入的,是否是數字。
或者將字符串轉換為數字類型時,要判斷字符串是否由純數字組成,否則報錯。
name = '123a'
if name.isdigit():name = int(name)
else:print('您輸入的含有非數字元素')
執行輸出:
您輸入的含有非數字元素
?
???len() 查看數據的長度
name = 'zhangsan'
print(len(name))
執行輸出: 8
?
二、for循環
先來使用while循環,打印每一個字符串
s = 'abcdef'
count = 0
while count < len(s):print(s[count])count += 1
執行輸出:
a
b
c
d
e
f
?
使用for循環完成上面的功能
s = 'abcdef'
for i in s:print(i)
執行程序,效果同上
?
for循環和while循環的區別在于
for 循環是有限循環
while 循環是無限循環
有些情況,在不需要終止條件的情況下,使用for循環
有終止條件的,使用while循環
for循環會自動停止
?
使用for循環實現九九乘法表:
for i in range(1, 10):for j in range(1, i + 1):print('{}x{}={}\t'.format(j, i, i * j), end='')print('\n')
執行輸出:
1x1=1 1x2=2 2x2=4 1x3=3 2x3=6 3x3=9 1x4=4 2x4=8 3x4=12 4x4=16 1x5=5 2x5=10 3x5=15 4x5=20 5x5=25 1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36 1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49 1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64 1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81?
今日作業:
1,有變量name = "aleX leNb" 完成如下操作:1) 移除 name 變量對應的值兩邊的空格,并輸出處理結果2) 移除name變量左邊的'al'并輸出處理結果3) 移除name變量右面的'Nb',并輸出處理結果4) 移除name變量開頭的a'與最后的'b',并輸出處理結果5) 判斷 name 變量是否以 "al" 開頭,并輸出結果6) 判斷name變量是否以"Nb"結尾,并輸出結果7) 將 name 變量對應的值中的 所有的"l" 替換為 "p",并輸出結果 8) 將name變量對應的值中的第一個'l'替換成'p',并輸出結果9) 將 name 變量對應的值根據 所有的"l" 分割,并輸出結果。10) 將name變量對應的值根據第一個'l'分割,并輸出結果。 11) 將 name 變量對應的值變大寫,并輸出結果12) 將 name 變量對應的值變小寫,并輸出結果13) 將name變量對應的值首字母'a'大寫,并輸出結果14) 判斷name變量對應的值字母'l'出現幾次,并輸出結果15) 如果判斷name變量對應的值前四位'l'出現幾次,并輸出結果16) 從name變量對應的值中找到'N'對應的索引(如果找不到則報錯),并輸出結果17) 從name變量對應的值中找到'N'對應的索引(如果找不到則返回-1)輸出結果18) 從name變量對應的值中找到'X le'對應的索引,并輸出結果19) 請輸出 name 變量對應的值的第 2 個字符? 20) 請輸出 name 變量對應的值的前 3 個字符? 21) 請輸出 name 變量對應的值的后 2 個字符?22) 請輸出 name 變量對應的值中 "e" 所在索引位置?23)獲取子序列,去掉最后一個字符。如: oldboy 則獲取 oldbo。2,有字符串s = '123a4b5c'1)通過對li列表的切片形成新的字符串s1,s1 = '123'2)通過對li列表的切片形成新的字符串s2,s2 = 'a4b'3)通過對li列表的切片形成新的字符串s3,s3 = '1345'4)通過對li列表的切片形成字符串s4,s4 = '2ab'5)通過對li列表的切片形成字符串s5,s5 = 'c'6)通過對li列表的切片形成字符串s6,s6 = 'ba2'3,使用while和for循環分別打印字符串s='asdfer'中每個元素。
4,實現一個整數加法計算器(兩個數相加):
如:content = input('請輸入內容:') # 如用戶輸入:5+9或5+ 9或5 + 9,然后進行分割再進行計算。
5,計算用戶輸入的內容中有幾個整數(以個位數為單位)。
如:content = input('請輸入內容:') # 如fhdal234slfh98769fjdla
?
答案:
1,有變量name = "aleX leNb" 完成如下操作:
...(具體需求看上面作業)
1.1~1.4
name = "aleX leNb"
s1 = name.strip()
s2 = name.lstrip('al')
s3 = name.rstrip('Nb')
s4 = name.lstrip('a').rstrip('b')
print(s1)
print(s2)
print(s3)
print(s4)
執行輸出:
aleX leNb
eX leNb
aleX le
leX leN
?
?1.5~1.6
s5 = name.startswith('al')
s6 = name.endswith('Nb')
print(s5)
print(s6)
執行輸出:
True
True
?
1.7~1.8
s7 = name.replace('l','p')
s8 = name.replace('1','p',1)
print(s7)
print(s8)
執行輸出:
apeX peNb
aleX leNb
?
1.9~1.10
s9 = name.split('l')
s10 = name.split('l',1)
print(s9)
print(s10)
執行輸出:
['a', 'eX ', 'eNb']
['a', 'eX leNb']
?
1.11~1.12
s11 = name.upper()
s12 = name.lower()
print(s11)
print(s12)
執行輸出:
ALEX LENB
alex lenb
?
1.13~1.15
s13 = name.capitalize()
s14 = name.count('l')
s15 = name.count('l',4)
print(s13)
print(s14)
print(s15)
執行輸出:
Alex lenb
2
1
?
1.16~1.18
s16 = name.index('N')
s17 = name.find('N')
s18 = name.find('X le')
print(s16)
print(s17)
print(s18)執行輸出:
7
7
3
?
1.19~1.22
s19 = name[2]
s20 = name[:3]
s21 = name[-2:]
s22 = name.find('e')
s23 = name[:-1:]
print(s19)
print(s20)
print(s21)
print(s22)執行輸出:
e
ale
Nb
2
1.23?獲取子序列,去掉最后一個字符。如: oldboy 則獲取 oldbo
序列,就表示是一個列表。之序列,表示列表中的一個元素。
字符串轉換為列表,有種方法:
1.直接使用list 強制轉換。比如
name = "oldboay"
s1 = list(name)
2.使用split切割成字符串
?
題目表示需要去掉最后一個字符,并獲取之序列,那么就需要使用第2種方法
先獲取最后一個字符
name = "oldboay"
#獲取最后一個字符
s1 = name[-1]
print(s1)
執行輸出: y
再使用split指定最后一個字符,進行切割
name = "oldboay"
#使用split對最后一個字符分割
s2 = name.split(name[-1])
print(s2)
執行輸出:
['oldboa', '']
最后取第一個元素,最終代碼如下:
name = "oldboay"
#使用split對最后一個字符分割,并取第一個元素
s3 = name.split(name[-1])[0]
print(s3)
執行輸出:
oldboa
?
2,有字符串s = '123a4b5c'
...(具體需求看上面作業)
s = '123a4b5c'
s1 = s[0:3]
s2 = s[3:6]
s3 = s[0]+s[2]+s[4]+s[6]
s4 = s[1]+s[3]+s[5]
s5 = s[-1]
s6 = s[5]+s[3]+s[1]
print(s1)
print(s2)
print(s3)
print(s4)
print(s5)
print(s6)
執行輸出:
123
a4b
1345
2ab
c
ba2
?
3,使用while和for循環分別打印字符串s='asdfer'中每個元素。
s = 'asdfer'
count = 0
while count < len(s):print(s[count])count += 1
執行輸出:
a
s
d
f
e
r
?
4,實現一個整數加法計算器(兩個數相加):
如:content = input('請輸入內容:') # 如用戶輸入:5+9或5+ 9或5 + 9,然后進行分割再進行計算。
先定義一個變量表示用戶輸入的內容,使用split()分割,指定+為分隔符
content = '5+9'
num = content.split('+')
for i in num:print(i)
執行輸出:
5
9
?
再定義一個變量計算總和
content = '5+9'
the_sum = 0
num = content.split('+')
for i in num:the_sum += i
執行報錯
TypeError: unsupported operand type(s) for +=: 'int' and 'str'
為什么呢?因為split分割出來的是字符串,需要轉換一下。
content = '5+9'
the_sum = 0
num = content.split('+')
for i in num:the_sum += int(i)print(the_sum)
執行輸出:?14
?
5+9是連續一起的,如果是5 + 9 呢?分割的時候,會有空格,使用strip()方法,就可以去除
content = '5 + 9'
the_sum = 0
num = content.split('+')
for i in num:the_sum += int(i.strip())print(the_sum)
執行輸出:?14
最后再把content 換成input(),終極代碼如下:
content = input('請輸入內容:').strip()
the_sum = 0
num = content.split('+')
for i in num:the_sum += int(i.strip())print(the_sum)執行輸出:
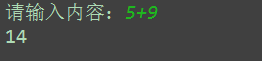
?
5,計算用戶輸入的內容中有幾個整數(以個位數為單位)。
如:content = input('請輸入內容:') # 如fhdal234slfh98769fjdla
先把字符串,一個個打印出來
content = 'fhdal234slfh98769fjdla'
the_sum = 1
for i in content:print(i)
再定義變量the_sum計算總數,使用isdigit()方法判斷是否為數字,如果是,總數加1
content = 'fhdal234slfh98769fjdla'
the_sum = 0
for i in content:#print(i)if i.isdigit():the_sum += 1print(the_sum)
執行輸出: 8
最終代碼如下:
content = input('請輸入內容:').strip()
the_sum = 0
for i in content:if i.isdigit():the_sum += 1print(the_sum)
執行輸出:

請注意:234前面的字符串是字母l,而不是數字1
?
明日默寫內容:
分別用while,for循環輸出字符串s = input('你想輸入的內容')的每一個字符。
while方式
s = input('請輸入你想的內容:')
count = 0
while count < len(s):print(s[count])count += 1
執行輸出:
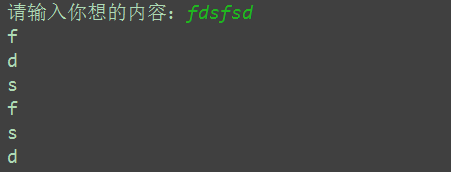
?
for方式
s = input('請輸入你想的內容:')
for i in s:print(i)
執行程序,效果同上
?