最近迷上了爬蟲,看了一丟丟視頻學習之后,開始實戰,爬取圖片地址:
http://desk.zol.com.cn/
循環爬取“風景”圖片,實現代碼如下:
from urllib import request,error
import re
key_name=request.quote("fengjing")
##定義函數,將爬到的每一頁的商品url寫入到文件
def savefile(data):path="C:\\Users\\Administrator\\Desktop\\fengjing_url.txt"file=open(path,"a")file.write(data+"\n")file.close()#外層for循環控制爬取的頁數 將每頁的url寫入到本地
for p in range(0,10):url="http://desk.zol.com.cn/"+key_name+"/"+str(p)+".html"data=request.urlopen(url).read().decode("utf-8",'ignore') ######嘗試了幾次,不加ignore會報錯savefile(url)pat='<a class="pic" href="/(.*?)" target="_blank" hidefocus="true"><img width="208px" height="130px" alt=(.*?) src="https://(.*?)"'####這個正則初學,不太會寫,所以寫的很長,希望有更好方法的小伙伴多多指教img_url=re.compile(pat).findall(data)for j in range(len(img_url)):this_img=img_url[j][2]######由于正則寫的不好,所以返回的東西比較多,不過幸好謝天謝地,需要的東西都在[2]里this_img_url="http://"+this_imgprint(this_img_url)img_path="C:\\Users\\Administrator\\Desktop\\fengjing\\" + str(p)+ str(j)+".jpg"request.urlretrieve(this_img_url,img_path)
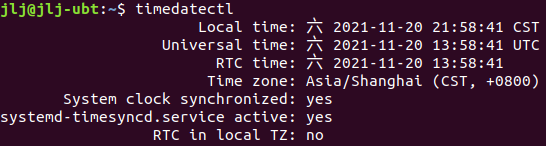
爬取結果:


把Key_name換成“dongman”(動漫),爬取的圖片如下:

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态