Linux就這個范兒?第11章? 獨霸網絡的蜘蛛神功 ?第11章
?
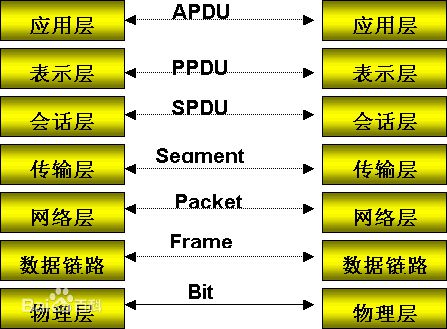
應用層 (Application):
網絡服務與最終用戶的一個接口。
協議有:HTTP FTP TFTP SMTP SNMP DNS
表示層(Presentation Layer):
數據的表示、安全、壓縮。(在五層模型里面已經合并到了應用層)
格式有,JPEG、ASCll、DECOIC、加密格式等
會話層(Session Layer):
建立、管理、終止會話。(在五層模型里面已經合并到了應用層)
對應主機進程,指本地主機與遠程主機正在進行的會話
傳輸層 (Transport):
定義傳輸數據的協議端口號,以及流控和差錯效驗。
協議有:TCP UDP,數據包一旦離開網卡即進入網絡傳輸層
網絡層 (Network):
進行邏輯地址尋址,實現不同網絡之間的路徑選擇。
協議有:ICMP IGMP IP(IPV4 IPV6) ARP RARP
數據鏈路層 (Link):
建立邏輯連接、進行硬件地址尋址、差錯校驗等功能。(由底層網絡定義協議)
將比特組合成字節進而組合成幀,用MAC地址訪問介質,錯誤發現但不能糾正。
物理層(Physical Layer):
建立、維護、斷開物理連接。(由底層網絡定義協議)
?
更有趣的是我們能把所有物品通過射頻識別信息傳感設備與互聯網連接起來,實現智能
化地識別和管理。Linux這個開發平臺,通過模塊化的驅動,對Zigbee無線傳感網絡、藍牙、
WiFi、射頻識別RFID、遠程網絡和多網絡融合技術的有力的支持,可實現許多令人向往的
應用場景:出家門時大門提醒主人需要帶什么東西;衣服“告訴”洗衣機對顏色和水溫的要
求;坐在家里可以檢測身體的情況并接受遠程醫生的治療等等。
更神奇的是在2010年底,思科在不利用任何地面基站的情況下,完成了業界首次網絡
通話,讓互聯網走出了地球。看來網絡的未來發展空間將是整個寧宙,不久的將來“馬丁叔
叔①’也能在火星上瀏覽網頁了。
現如今,Linux憑借其精湛的“蜘蛛神功”,聯網特性極其剛猛,加之深厚的內核功力,
“織網”能力日臻純熟。Linux獨霸網絡一統江湖只在朝夕,這主要表現在:
(1)內建了HTTP、FTP,DNS等功能,支持所有常見的網絡服務。加上超強的穩定性,
讓很多ISP (Internet Service Providers)都樂意采用Linux來架設郵件、FTP以及
Web等各種服務器。
(2) 支持幾乎所有的通用網絡協議。比如IPv4、IPv6、AX.25、X.25、IPX、DDP (Appletalk)、
NetBEUI、Netrom等。
(3) 通過一些簡單的Linux命令就能完成內部信息或文件的傳輸,系統管理員和技術人
員通過系統提供的遠程訪問功能可有效地為多個系統服務。
(4) 支持Netware的客戶機和服務器,甚至支持讓用戶共享Microsoft Network資源的
Samba服務。
有這么多創新的應用,這么神奇的服務,你還在等什么?萬丈高樓平地起,雖然“蜘蛛
神功”很好很強大,可我們還得從基礎學起。
?
?
11.1 功夫理論:網絡知識
首先聲明:若練神功,不必自宮。但是沒有網絡方面的理論基礎則是萬萬不行。提到網
絡理論基礎,無一例外地我們都會想到OSI七層模型和TCP/IP網絡參考模型。這兩個模型
都具有網絡結構化分層的特點。現在形形色色的系統框架都提倡分層和組件化。那么分層究
竟有什么好處呢?網絡分層的主要好處就是可以屏蔽其他層的實現細節,各層只需提供與自
己相鄰層的接口即可。在各層之問接口標準化的另一個好處是不同的產品可以提供不同層次
的功能,這樣就簡化了設計,例如路由器只實現一到三層。除此之外,分層還創造了更好的
集成環境,減少復雜性,每層都有headers和tailers,可以利用它們進行排錯。這種分層的
思想在軟件架構設計當中也是非常普遍的。
我們知道中國人是很講究論資排輩的,那么OSI和TCP/IP兩個誰的輩分更大呢?論時
間它們年紀相仿,但嚴格說來應該是TCP/IP資格更老。因為在OSI的七層模型誕生之前,
ARPANET已經存在了。TCP/IP生于20世紀60年代,是從美國國防部研究所計劃局DARPA
開發異種網絡互連與互通項目中誕生的。它是從實踐中走來,先有協議后有4層模型的。它
的模型主要起解釋作用,象征意義大于實際作用。為了更好地推廣TCP/IP,DARPA還資肋
一些機構在UNIX操作系統上開發TCP/IP協議。而OSI模型則生于20世紀70年代,全稱是開
放系統互聯,由國際標準化組織ISO提出。它相當’F學院派的作品,設計先于實現,許多設計也過于理想化。OSI強調提供可靠的數據傳輸服務,每一層都要進行檢測和處理錯誤。在這方面,TCP/IP和OSJ觀點不同。TCP/IP認為可靠要由端對端來保證,不要把系統搞得太復雜。傳輸層利用檢驗和、ACK和超時等手段實現錯誤檢測和恢復來保證可靠性控制就可以了。隨著歲月的流逝,證明簡單才是硬道理,TCP/IP已成為國際互連事實上的國際標準和工業標準。
但以發展的眼光來看,OSI也有它積極的意義,它適用于更多類型的網絡,而不僅僅是
計算機網絡。OSI與TCP/IP也有一定的對應關系,具體可參考表11-1:
?
表11-1?0SI與TCP/IP的對應關系
| OSI | TCP/IP | |
| 分??層 | 描??述 | 分??層 |
| 實體層 | 以二進制數據形式在物理媒體上傳輸數據 | 網絡接口層 |
| 數據鏈路層 | 傳輸有地址的幀以及錯誤檢測功能 | |
| 網絡層 | 為數據包選擇路由 | 網絡互聯層(IP層) |
| 傳輸層 | 提供端對端的接口 | 傳輸層 |
| 會話層 | 解除或建立與別的接點的聯系 | 應用層 |
| 表示層 | 數據格式化,代碼轉換,數據加密 | |
| 應用層 | 文件傳輸,電子郎件,文件服務,虛擬終端 | |
?
OSI七層模型
物理層
數據鏈路層
網絡層
傳輸層
會話層
表示層
應用層
?11.2??“蜘蛛神功”第一層:網絡工具
我們現在開始修煉第一層的功夫,是基本功。需要從最基本的“馬步”開始練起,增加
你的耐力和身體的穩定性。在這之后我們就要開始學習“套路”了,這包括“掌法”、“腿功”、
“眼力”和“身法”。閑話不多說,馬上開始。
11 .2.1 馬步:ifconfig
ifconfig是一個用來查看、配置和開關網絡接口的常用工具,屬于最基本的工具。只有
掌握了它的使用,你才能駕馭好“蜘蛛神功”。我們可以利用它臨時性地配置網卡的IP地址、
子網掩碼、廣播地址、網關等。也可以把它寫入/etc/rc.d/rc.local文件中,在系統引導時為網
卡設置IP地址。
首先我們看一下“馬步”的基本架勢,用它查看一下網絡接口狀態:
# ifconfig
etho Link encap : Ethernet HWaddr 00 : CO : 9F : 94 : 78 : OE
inet addr : 192 . 168 .1. 88 Bcast : 192 . 168 .1. 255 Mask : 255 . 255 .255 . 0
inet6 addr : fe80 : : 2c0 : 9fff : fe94 : 780e/64 Scope : Link
UP BROADCAST RUNNING MULTICAST MTU : 1500 Metric : 1
RX packets : 850 errors : 0 dropped : 0 0verruns : 0 frame : 0
TX packets : 628 errors : 0 dropped : 0 0verruns : 0 carrier: 0
collisions : 0 txqueuelen : 1000
RX bytes:369135 (360.4 KiB) TX bytes:75945 (74.1 KiB)
lo Link encap: Local Loopback
inet addr: 127.0.0.1 Mask: 255.0.0.O
inet6 addr: ::1/128 Scope: Host
UP LOOPBACK RUNNING MTU: 1643 6 Metric:1
RX packets: 57 errors:O dropped:0 0verruns:0 frame:O
TX packets: 57 errors:0 dropped:O overruns:0 carrier:O
collisions:0txqueuelen:0
RX bytes: 8121 (7.9 KiB) TX bytes: 8121 (7.9 KiB)
達個命令的輸出信息量還是很大的。大致分為上下兩個部分,上面是eth0酌信息,下面是lo的信息(在你的實際系統中可能會有更多部分)。其中IP地址、子網掩碼、MAC地址等重要信息基本上也是一目了然的。但是也有一些是看不懂的,比如RX和TX后面那些都代表什么呢?lo又代表什么呢?
在搞清楚這些問題前,我們首先要搞清楚第四行中的內容,也就是:
UP BROADCAST RUNNING MULTICAST
這樣的內容都代表什么含義。這其實是代表網卡的狀態。有些狀態是可以同時出現的,
有些則不能,表11-2列舉了能夠出現的狀態標志,你可以分析一下哪些是能共存的,哪些
不能。
表11-2網卡能夠出現的狀態標志
| 狀態標志 | ?說??明? |
| UP? | 這個標志指出這個接口是開放的,可以發送和接收數據 |
| ?DOWN??? | 個標志指出這個接口是關閉的,也就是說,此時不能為主機發送和轉發包 |
| NOTRAILERS | 這個標志指出了一個報文尾不包括以太幀的尾部。報文尾是在Berkerley?Unix系?統中使用的把信息頭加到包尾的一種方式。在Solaris2.x系統中已經不支持 |
| ?RUNNING? | 這個標志指出,該接口已經被系統識別??? |
| MULTICAST? | 這表示接口支持多路傳送地址?? |
| BROADCAST? | 這表示接口支持廣播地址? |
?
?
?
現在我們來看RX和TX。它們代表這塊網卡從啟動到現在的封包收發情況,RX是收,
TX是發。packets就代表包數,多少都沒事兒;其他的各代表一種錯誤,數值應該越少越好,
0是最好的。至于這些錯誤都代表什么,由什么引起的則不屬于本書負責的范圍。
從ifconfig的輸出的格式上看,Io和eth0應該具有同等地位,都是網絡設備。其實不然,
Io表示的是主機的回環地址。這個一般是用來測試一個網絡程序,但又不想讓局域網或外網
的用戶能夠查看,只能在此臺主機上運行和查看所用的網絡接口。比如把httpd服務器的地
址指定為回環地址,在瀏覽器輸入127.0.0.1就能看到你所架設的Web網站了。
基本的“馬步”架式已經掌握,接下來就要折騰一些花樣,使用ifconfig配置網絡接口
讓網絡通起來:
# ifconfig eth0 192. 168.1.252 hw ether 00: 11: 00: 00: 11: 11\ > netmask 255 .255.255.O broadcast 192. 168 .1.255 up
這個例子中我們為eth0設置了IP地址、子網掩碼、廣播地址,MAC地址,并且激活了
它。這里比較讓人頭痛的可能就是“hw”這個參數,其后面所接的是網絡接口類型,ether
表示以太網。
?
有時我們為了滿足不同的需求還需要給一個網絡接口指定多個IP地址,比如我們期望在同一臺機器上用不同的IP地址來運行多個httpd服務器。這就要用到“虛擬網絡接口”這個概念了。虛擬網絡接口就是在網絡接口名后面接著冒號“:”和數字,比如:eth0:0、eth0:1、eth0:2......ethO:N。假設真實的網絡接口是eth0的話,我們可以用下面的方法配置虛擬網絡接口。
# ifconfig eth0 :0 192 . 168 .1.250 netmask 255 .255 .255 . 0 # ifconfig eth0 :1 192 .168 . 1. 249 netmask 255 .255 .255 . 0
但是用ifconfig為網卡指定IP地址只是用來調試網絡用的,并不會更改系統關于網卡
的配置文件。若要把IP地址固定下來,請參考第2章中解決上網問題那節我們所講述的三
種配置IP地址的方法。
在虛擬網絡接口上配置的IP地址實際上并沒有與這臺計算機做綁定。換句話說,不同
的計算機上的虛擬網絡接口可以配置相同的IP地址。而這個時候的IP地址還有一個專用的
名稱——VIP,即虛擬IP。VIP是非常有用的,本書在后面介紹LVS的時候還要用到。
好了,如果你已經把ifconfig用熟了,那么就證明你的“馬步”已經練成扎穩了。在面
對接下來的各種套路招式的時候,就應該不會手忙腳亂走火入魔了。
?
?
11 .2.2掌法:route
首先我們要學習的是“掌法”路由的概念。路由是此網和彼網溝通的紐帶,route命令
用于查詢和設置路由表。在同一個子網內的主機通信不需要路由,比如192.168.1.2/24和
192.168.1.3/24之間的溝通;不同的子網絡內的主機通信才需要路由比如192.168.1.1/24和
192.168.2.1/24之間的溝通。路由器(或者稱網關)就是用來給不同子網內的主機之間的數
掘包規劃“傳輸路徑”的網絡設備。
我們先小試一下:
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255 .255.0.0 U 1002 0 0 eth0
0.0.0.0 192 .168 .1. 254 0.0.0.0 UG 0 0 0 eth0
這個命令就是查看我機器的路由表信息。這個路由表各字段的含義如下:
● Destination、Genmask共同組合成一個完整的子網。
● Gateway定義從哪個gateway連接出去。如果是0.0.0.0表示該路由是直接由本機
傳送;如果顯示有IP的話,表示該路由需要得到路由器的幫忙才能夠傳送出去。
● Flags可能出現的標志及其意義如下:
□ U (route is up):該路由是啟動的。
□ H (target is a host):目標是一部主機(IP)而非網域。
□ G (use gateway):需要透過外部的主機(gateway)來通信。
□ R (reinstate route for dynamic routing):使用動態路由時,恢復路由信息的標志。
□ D (dynamically installed by daemon or redirect):已經由服務或轉pofl功能設定為
動態路由。
□ M (modified from routing daemon or redirect):路由已經被修改了。
□ ! (reject route):這條路由將不會被接受(用來抵擋不安全的網域!)。
本例中Destination 0.0.0.0行中的Flags列中顯示UG,表示這條路由已啟動,
需要通過外部主機192.168.1.254來通信。
● Metric路由的躍點數,范圍是0-9999。這個相當于是路由的權重,決定路由優先
級,數值越小優先級就越高。這是一個比較高級話題,可以參考專門的著作。
● Ref路由引用計數。這個值恒為0,因為在Linux系統中就沒有實現它。
● Use該路由被使用的次數,可以粗略估計通向指定網絡地址的網絡流量。但是在本
書中是0,因為還要取決于“一F”和“-C”參數。
● iface數據傳遞出去的硬件接L]。
路由的排列順序是從小網域(192.168.1.0/24是Class C),逐步到大網域(169.254.0.0/16
Class B)最后到默認路由(0.0.0.0/0.0.0.0)。當我們要判斷某個數據包應該如何傳送的時候,可經過這個路由過程來判斷!
?
本例中的三條路由,如果有一個目的地址為192.168.1.66的數據包要發出去,首選找到
了192.168.1.0/24遮個網域的路由,就直接由eth0發出去了!那么從我這臺機器上發送到
www.alibaba.com主機的數據的路由情況又是怎樣的呢?假設其IP是110.75.216.92,第一和第二條路由都不符合,結果到達第三條default=0.0.0.0/0.0.0.0默認路由時滿足條件。這時就通過eth0將數據包傳給192.168.1.254那部gateway主機,求它幫忙把數據包傳到外網。我們可以利用traceroute命令來跟蹤一下發往www.alibaba.com的數據包所要經歷的路徑,其輸出結果的第1行就是離我們最近的路由器的192.168.1.254這個IP地址。
route命令除了可以查看路由,還可以用來添加和刪除路由。比如:
# route del -net 169 .254.0.0 netmask 255 .255.0.0 dev eth0
刪除掉169.254.0.0/16這個網域。別偷懶,netmask和dev等參數一定要寫全!
# route add -net 192. 168.1.0 netmask 255 .255 .255.0 dev eth0
增加一條路由!路由的設定必須能夠與你的網段能夠互通。如果你的主機僅有
192.168.1.X這個IP,添加下面的路由就會顯示錯誤:
# route add -net 192. 168.2.0 netmask 255 .255 .255.O gw 192. 168.2.254
下面是增加默認路由的方法!默認路由一個就夠了。
# route add default gw 192.168.1.250
還有你的主機要和192.168.1.250能夠通信才行,否則路由被重置后果自負。
?
11 .2.3腿功:netstat
掌上的功夫練好了就可以練習“腿功”netstat命令了。netstat命令可以顯示路由表、實際的網絡連接以及每一網絡接口設備的狀態信息。
如果你想查看本機都啟動了什么服務,端口是什么以及當前網絡狀態的話,netstat就可以幫你搞定。如果啟動了某個服務它卻表現異常,netstat也可幫你找出原因。
事實上,netstat并不是一個人在戰斗,是若干工具的匯總 包括/etc/services文件。
netstat -r 跟route -n是一樣的
[root@steven ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 192.168.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0 [root@steven ~]# netstat -r Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface link-local * 255.255.0.0 U 0 0 0 eth0 192.168.0.0 * 255.255.0.0 U 0 0 0 eth0 default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
現在我們用netstat查看當前的網絡連接信息:
# netstat -nta Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0 .0.1:2208 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:1002 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:111 0.0.0.O:* LISTEN tcp 0 0 127.0.0.1: 631 0.0.0.O:* LISTEN tcp 0 0 127.0.0.1: 25 0.0.0.O:* LISTEN tcp 0 0 127 .0.0 .1:2207 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:3306 :::* LISTEN
netstat輸出可以分為兩大部分:一個是TCP/IP的網絡部分,另一個Unix socket部分。
Unix socket只能用于本機內的進程間通信。由于Unix socket連接非常多,為了更清楚地查看
網絡情況,本例使用-nta要求只列出所有TCP的網絡情況。各字段的解釋如下:
?
● Proto連接的封包協議。
● Recv-Q非連接本Socket的用戶程序所復制的總bytes數。
● Send-Q沒有被遠端主機ACK的總bytes數,主要指SYN或其他標志的數據包所占
的bytes數。
● Local Address本地地址與端口
● Foreign Address遠程地址與端口
● Stat內部地址與外部地址的連接狀態:
□ ESTABLISED:經過TCP三次握手已建立連接。
□ SYN—SENT:表示請求連接。SYN SENT狀態應該是非常短暫。
□ SYN—RECV:接收到一個要求連線的主動連線封包。
□ FIN—WAIT1:socket已中斷,該連線正在斷線中。
□ FIN—WAIT2:該連線已掛斷,但正在等待對方回應斷線確認包。
□ CLOSE-WAIT:當客戶端向服務器發送請求等待超時后,客戶端就會發FIN包到服務端,但FIN包因為服務器沒有空閑線程池而得不到及時處理,所以TCP連接請求只能處于CLOSE-WAIT狀態,同時新請求也被阻塞,有了這個基礎之后,再通過代碼調試跟蹤,最后發現處理邏輯是同步的,要改為異步。 ?(蜘蛛神功第二層 套接字)
□ TIME—WAIT:該連線已掛斷,但socket還在網絡上等待結束。
□ LISTEN:表示處于偵聽狀態,該端口是殲放的,等待連接。可使用專門的“-ll”
參數單獨查閱。
?
SYN_SENT狀態應該是非常短暫。如果發現SYN_SENT非常多且在向不同的機器發出,
那你的機器可能中了沖擊波或震蕩波之類的病毒。這類病毒為了感染別的計算機,它就要掃描別的計算機,在掃描的過程中對每個要掃描的計算機都要發出同步請求,這就是出現許多
SYN_SENT的原因。當然,這些情況大多是發生在Windows下,既然你已經選擇了Linux,
應該是很少再為病毒所惱的。
作為服務器,重點要看的是LISTEN狀態和ESTABLISHED狀態。LISTEN是本機開了
哪些端口;ESTABLISHED是誰在訪問你的機器,從哪個地址訪問的,是不是一個正常程序
發起的。在Windows系統上看ESTABLISHED狀態時一定要注意是不是IEXPLORE.EXE程
序(IE)發起的連接,如果是IEXPLORE.EXE之類的程序發起的連接,也許是你的計算機
中了木馬。
?
在本例中我們通過netstat查看到了當前所打開的端口號。那么順便提一下Linux服務端
口的設置問題。在大多數Linux發行版下都能夠找到/etc/services這個文件,它實際上是一個
字典文件,用來說明服務與端口的對應關系。有如下類似的內容:
ftp 20/tcp ftp 20/tcp ssh 22/tcp telnet 23/tcp
這看起來是給服務分配端口用,但是實際上這個文件并沒有這個作用。它只是給netstat
命令參考的,因為當你不給它傳遞“-n”這個命令選項時,足能夠輸出服務名的。netstat之所以能夠做到這一點,就是/etc/services文件起的作用。
為了驗證這一點,你可以嘗試著修改一下它。
?
?
11 .2.4 眼力:DNS二把刀
到目前為止你已經習得了“蜘蛛神功”的“掌法”和“腿功”,已經可以列入“一等一
高手”的行列里了,只是還缺乏一些臨戰經驗。其實所謂的臨戰經驗也不過就是一個“快”
字,只有出手快才能占據主動權。而要“快”就必須有非常好的“眼力”去洞察目標。“蜘
蛛神功”有專門的套路來提升“眼力”,那就是DNS二把刀。Linux上的DNS二把刀就是:
host和nslookup。這兩個命令都是非常常用的DNS工具。
既然說到了DNS,順便就介紹一下與DNS有關的東東吧。主要有三個:一是主機自己
的名字;二是DNS服務器;三是HOST文件。
在Linux中可以用hostname命令來查看主機自己的名字。設置主機自己的名字一般可
以通過/etc/sysconfig/network文件完成。它的主要內容一般是:
/etc/sysconfig/network NETWORKING=yes HOSTNAME=localhost.localdomain
HOSTNAME后面緊跟的是主機名,這里是系統默認的localhost.localdomain,更改主機
名后需要重新啟動才能生效。
為了能夠正常上網,DNS服務器是必不可少的設置環節。/etc/resolv.conf文件就是用來
設置固定DNS服務器的,其主要內容如下:
/etc/resolv.conf nameserver 8 . 8 . 8 . 8 nameserver 202 . 96 . 128 . 86
nameserver后面緊跟著的就是DNS服務器了。如果你通過nameserver指定了幾個DNS
服務器,則先后順序決定主從服務器。目前最多支持3個域名服務器。
所謂HOST文件,實際上就是主機名靜態查詢表。在Linux下是/etc/hosts文件,它告訴
本主機哪些域名或主機名對應哪些IP,其內容差不多是這樣:
#網絡IP 主機名或域名 主機名別名(可選)
/etc/hosts 127 . 0 . 0 .1 localhost. Localdomain localhost 192 168 . 21. 100 webserver. cn77888.com webserver 192 .168 . 21. 111 ftp.cn7788.com ftp
主機名通常在局域網內使用,通過hosts文件被解析到對應的IP地址上。而域名通常在
Internet上使用。Linux做域名解析的時候先查hosts文件,所以如果本機不想使用Internet
土的域名解析,可以更改hosts文件,加入自己的域名解析。
host命令非常簡單,功能也很單一,就是查詢某個域名或豐機名所對應的所有IP地址,
比如:
# host www. google.com www. google. com has address 74. 125. 31. 106 www. google. com has address 74. 125.31. 147 www. google. com has address 74. 125.31. 99 www. google. com has address 74. 125.31. 103 www. google. com has address 74. 125.31. 104 www. google. com has address 74. 125.31. 105 www. google. com has IPv6 address 2404: 6800: 4008: c01::63
這是我能解析到的google這個域名所對應的所有IP。一個域名綁定多個IP最直接的作
用就是
(1)容災:當某個IP不可用時可以立即換用其他lP,防DDOS攻擊;
另外一作用就是
(2)使得用戶能夠就近訪問,給用戶提供最為流暢的體驗,因為可以根據用戶的不同來源提供不同的IP地址。
nslookup和host墓本是一樣的,用來查詢一臺機器的IP地址和其對應的域名。這個命令有兩種模式:交互式和非交互式。如果你不給它傳遞任何參數,它就會進入交互模式,例如:
# nslookup > WWW . taobao . com Server: 10 . 0 . 1. I Address : 10 . 0 . I . 1#53 Non-authoritative answer: www. taobao. com canonical name=www. gslb.taobao. com. danuoyi. tbcache. com. www. gslb.taobao. com. danuoyi. tbcache. com canonical name: scorpio. danuoyi.tbcache. com. Name: scorpio. danuoyi.tbcache. com Address:124. 193. 226.251 Name: scorpio. danuoyi.tbcache. com Address:124. 193. 226. 241 > nslookup比較特別的地方就是可以手動指定DNS服務器來得到不同解析結果,例如: # nslookup www. sina. com. cn Server: 10.0-1.1 Address: 10.0.1.1#53 Non-authoritative answer : www . sina . com . cn canonical name = j upiter . sina . com . cn . jupiter . sina . com _ cn canonical name = polaris . sina . com . cn . Name : polaris . sina . com. cn Address : 202 . 108 . 33 . 60 # nslookup www. sina . com. cn 8 . 8 . 8 . 8 Server : 8 . 8 . 4 . 4 Address : 8 . 8 . 4 . 4#53 Non-authoritative answer : www . sina . com . cn canonical name = j upiter . sina . com . cn . jupiter . sina . com . cn canonical name = ara . sina . com _ cn . Name : ara . sina . com . cn Address : 58. 63 .236 . 50 Name : ara . sina . com . Cn Address : 58 . 63 . 236 . 26 ...... Name : ara . sina . com. cn Address : 58 . 63 .236 .41
?
?
11 .2.5身法:tcpdump
做網絡開發和維護的工程師如果說自己不會用tcpdump就真沒法在江湖上混了,因為那是“蜘蛛神功”的“身法”。段譽之所以每次都能夠逢兇化吉,就是因為練就了“凌波微步”那曼妙的身法。
tcpdump是網絡運維人員查找問題的利器。通過不同的命令行選項來改變抓包狀態。利
用正則表達式組合成多種過濾報文的條件,數據包滿足表達式的條件就會被捕獲。如果沒有
給出任何條件,那么網絡上所有的數據包將會被截獲。
舉個例子,如果想捕獲119.75.219.38接收或發送的http包,將其結果生成詳細報告,
可以使用如下命令:
# tcpdump tcp port 80 and host 119 .75.219. 38>net_stat. txt
這樣你就可以使用V1等工具讀取net_stat.txt文件來分析問題了。不知道你是否感覺到使用VI等工具來閱讀抓包文件不太直觀。
其實比較好的辦法是把tcpdump抓下來的內容存成pcap文件(-w選項),然后使用圖形界面的網絡協議分析工具例如Wireshark(它的前身就是很黃很暴力的開源網絡協議分析工具Ethereal)進行數據包分析。例如,某家電子商務網站曾經碰到過一次很嚴重的線上故障,造成了N百萬的資損,最終是通過tcpdump在相關服務器上抓包排查出問題的。比如在Apache服務器上監控80端口的數據包,可使用如下命令:
#tcpdump tcp port 80 -S 0 -w http .pcap
然后將截獲到的http.pcap數據包文件使用Wireshark或Packetyzer之類的工具打開
查看。
當然,工具只是幫助你解決問題的一種手段。使用好抓包工具的關鍵還是要對網絡協
議有深入的理解,根據實際情況列出過濾條件,快速找到自己想要的數據包進行分析。例
如我要分析WLAN設備的工作情況,若是對802.11的探測、身份驗證、關聯過程、控制
以及數據包的協議格式都不了解的話,就算把抓到的數據包給我,我也看不懂,如同看火
星文一樣。
曾經遇到過這么一個情況,公司網絡突然變得非常慢,近乎癱瘓。請來網絡運維的人員,
他要做的事情就是在網絡內一臺主機上運行抓包軟件,捕獲所有到達本機的數據包進行分
析。如果是Linux主機的話,使用tcpdump就可以執行監聽網絡數據的任務。網絡變慢常常
和由ARP病毒造成帶寬資源耗盡有關。ARP病毒很狡猾,它欺騙網關或網內的所有主機。
在網關的ARP緩存表中,網內所有活動主機的MAC地址均為中毒主機的MAC地址;網內
所有主機的ARP緩存表中,網關的MAC地址也成為中毒主機的MAC地址。前者保證了從
網關到網內主機的數據包被發到中毒主杌。后者相反,使得主機發往網關的數據包均發送到
中毒主機。
tcpdump是一個非常強大的命令,就算利用整本書去講解它也未必就能做到面面俱到。
本書在這個地方只能起到拋磚引玉的作用,期望繼續深入的你還需尋找更為專業的著作來滿
足你那求知若渴的心。
?
?
?
11.3 “蜘蛛神功”第二層:套接字
有了網絡基礎知識,學會了操作命令,我們就要開始修煉第二層功夫,嘗試一下網絡編程了。
搞過網絡編程的人都接觸過Socket。
這東西年頭久遠了,可追溯到20世紀60年代,那個時候網絡才剛剛起步。Berkeley計算機研究組就開始研究如何編寫網絡程序,如何回調網
絡應用,從而開發出了Socket的原始版本。Socket的這個原始版本經過多個廠商與組織的
共同努力,最后形成一套成熟的Socket API。不能不說Socket API是經典中的經典,數十年后的今天我們還在使用。
但由于歷史原因,經典中稍微帶有那么一點點小瑕疵。比如說,Socket里面有PF開頭的一組枚舉值來表示協議簇,還有AF開頭的一組枚舉值來表示地址簇,
有點多余。到目前為止所有的協議簇和地址簇都是一一對應的,還沒有出現一個協議簇支持多個地址簇的情況。
事實上現在我們也不認為同時需要這兩個概念,但在寫程序的時候我們卻要生生地區分它們。
又比如說,sockaddr這個結構體類型,它的存在只是為方便傳遞一個結構指針,但是用戶卻從來沒有真正使用過這個類型。
盡管Socket API有上面小個的瑕疵,但這并不影響它在網絡編程中的生命力,在網絡協
議棧中可以看作是獨立的一個Socket層。這個Socket層設計得非常巧妙,不服不行,它和網絡協議層聯系起來,屏蔽了網絡協議的不同,
只把數據部分通過系統調用接口呈獻給應用層。
這種協議無關性,讓程序員用起來感覺很方便,一個網絡程序只需要幾個簡單的socket系統調用,整體的資源就都可以使用了。
socket->connect->read->write->close構成了一個TCP客戶端;
而在這個客戶端上加入bind、listen、accept三個調用就構成了一個TCP服務器程序。
天下沒有完美的事情。盡管Socket API使用很方便,但是網絡非常不穩定,可能隨時崩潰。
操作系統也不是萬能的,應用程序不僅要完成自己的業務,還要關心網絡可能出現的各種情況。做好網絡流量控制、異常監控和故障轉移等工作,是每一個擁有聯網功能程序的基
本義務。網絡本身的復雜性,也給程序員帶來了很大的挑戰,寫好Socket網絡程序從來就不是一件容易的事情。
?
下面是一段關于網絡出現異常的真實故事······
很多年以前,我在開發一個網絡服務器的時候,發現服務器某個端口堆積著大量
CLOSE_WAIT狀態。有時應用能夠恢復,有時應用就癱瘓了,不能響應TCP請求。
我第一反應就是要搞清楚導致CLOSE_WAIT狀態是在什么情況下發生的?理論上分析:
當客戶端向服務器發送請求等待超時后,客戶端就會發FIN包到服務端。但FIN包因
為服務器沒有空閑的線程而得不到及時處理,所以TCP的連接請求只能處于CLOSE_WAIT
狀態,同時新請求也被阻塞。有了這個基礎后,再通過對代碼的調試跟蹤。最后我發現請求
處理邏輯是同步的,這個做法是有問題的。如果業務處理得慢,就會造成擁塞。我用異步方
式處理業務請求把I/O線程解放出來,問題隨之解決。
好了,有關“蜘蛛神功”第二層的東西我們暫時就介紹到這里,因為本書已經將epoll
編為“七種武器”中的一種武器——碧玉刀,在后面的章節中會有更詳盡的介紹。接下來我們還要修煉一下內功心法!
?
?
?
?
11.4 內功心法:TCP/IP協議棧初探①
“我們一直在克服這樣或那樣的障礙,好像在翻山越嶺一樣,爬到頂,然后落下來,再釋放能量。”
——TCP/IP發明人Vinton G Cerf博士
十幾年前第一次下載Linux內核源碼,研讀net和drivers/net里面代碼時的那種剪不斷
理還亂的復雜心情依然在胸。那時候中國網絡還不算那么發達,關于Linux內核方面的資料
少之又少。我只能告誡自己沉下心來,從變量定義和數據結構開始,然后從上層調用到底層
調用,從底層調用再到上層調用,一點一點地研究。學習的過程是艱苦的,也是有收狀的。
在利用列車供電線傳輸組播視頻流的項目中,我就利用對Linux TCP/IP協議棧的理解,在
電力貓設備上定制實現了自己的Linux TCP/IP協議棧以提高傳輸數據的質量,解決了馬賽克
問題(牛)。其實,就算不做內核開發的工作,對協議棧酌理解也會對你寫好網絡應用程序
有所幫助的。
掌握Linux TCP/IP棧需要理解系統調用、socketfs文件系統和sk_buff這三個關鍵知識點。
理解它們之后,我們就比較容易看懂Linux TCP/IP方面的內核代碼了。在此基礎上依靠個人
修煉,逐步釋放能量,在領悟大師們的設計思想的過程中不斷進步!
?
?
11.4.1 枯樹盤根:系統調用
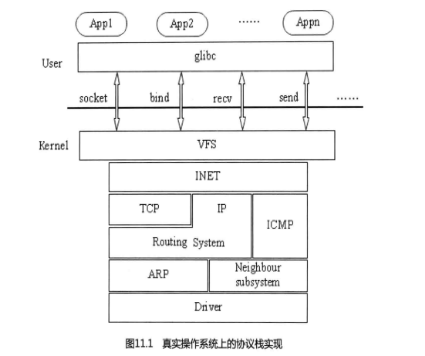
圖11.1描述了Linux的TCP/IP協議棧的實現方式。看了以后,希望能夠幫助你在協議
棧的理解上增加點感性認識。
①沒有網絡編程經驗的工程師要績悸這仃有一定難度,fH足領會Linux TCP/IP協議棧的設計
思想還是大有好處。
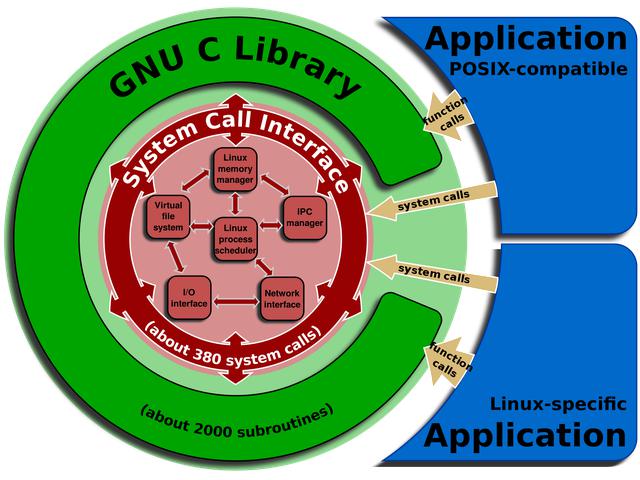
glibc庫是什么?沒有glibc庫,就沒有Linux。我們平時用過的malloc和strcpy等函數
都是glibc這位仁兄提供的。除此之外,它還提供了網絡編程中要用到的Socket API接口。之前曝光的glibc庫漏洞
?
glibc版本
rpm -qa |grep glibc glibc-2.12-1.166.el6_7.3.x86_64 glibc-headers-2.12-1.166.el6_7.3.x86_64 glibc-2.12-1.166.el6_7.3.i686 glibc-devel-2.12-1.166.el6_7.3.x86_64 glibc-common-2.12-1.166.el6_7.3.x86_64
?
glibc CVE-2015-7547漏洞的分析和修復方法
http://bbs.qcloud.com/thread-13780-1-1.html
漏洞概述
glibc中處理DNS查詢的代碼中存在棧溢出漏洞,遠端攻擊者可以通過回應特定構造的DNS響應數據包導致glibc相關的應用程序crash或者利用棧溢出運行任意代碼。應用程序調用使用getaddrinfo 函數將會收到該漏洞的影響。
這樣TCP/IP接口通過INET層就能訪問各種操作,這些操作要在網絡初始化時注冊。socket、
bind、connect、send和recv等系統接口超有能力,不僅支持你上網(AF INET),還支持你
的應用程序之間的通信(AF_ UNIX),以及內核與用戶程序之間的通信(AF- NETLINK),
就連比較少見的協議,例如AF_IPX也支持。有一點需要注意的是,IP層不完全在TCP之
下,應用程序可以繞過TCP層而直接5IP層協作,比如ping命令。
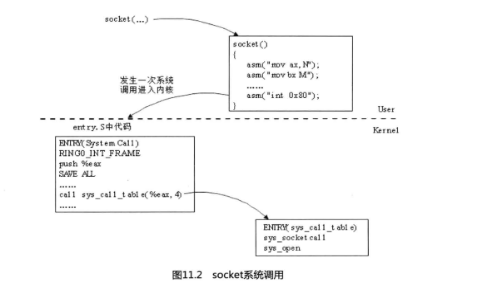
下面我們來揭開網絡系統調用的神秘面紗,請看圖11.2。
我們平時編寫的網絡程序運行在用戶模式( user mode)下,它有自己的內存映射(即地
址空間)。而TCP/IP棧運行在內核模式(kemel mode)下,在不同的地址空間里運行。這樣分開的好處是系統調用主要考慮如何更好地滿足實時性和多處理機的并行處理,而用戶的主要精力就是把自己的網絡應用邏輯做好。那么應用層程序與Linux系統內核如何進行交互通
信的呢?讓我來告訴你這個秘密Ⅱ巴。它是通過一個軟中斷,中斷號是0x80。通過int 0x80指令就可使用內核資源了。不過,通常應用程序都是使用具有標準接口定義的C函數庫。它間接使用內核的系統調用,即應用程序調用C函數庫中的函數,C函數庫中再通過int Ox80進行系統調用。所以,系統調用過程是這樣的:
1. 應用程序調用glibc中的函數;
2. glibc中的函數引用系統調用宏;
3. 系統調用宏中使用int Ox80完成系統調用并返回。
程序-》glibc-》系統調用宏-》系統調用
在上面系統調用的步驟中出現了匯編語言。匯編是最接近計算機底層的語言,學習匯編
能讓你明白底層編程的原理。具有匯編知識才可能真正看懂內核啟動部分的伐碼。如果你想
進·步提高自己的內力,學習和使用匯編還是很有用的。
?
11 .4.2凝神靜態:sockfs文件系統
Linux的文件無處不在,設備有設備文件,嘲絡有網絡文件……創建一個套接口就是在sockfs文件系統中創建一個特殊文件,并建立起為實現套接口功能的相關數據結構。
首先sock_init函數將socket注冊為一個偽文件系統,并mount在相應的mount點上。掛載完系統后,就要創建socket了。
每次創建一個socket,都要依賴于當前的protocol family類型的。
protocol family類型有AF_INET、AF_NETLINK和AF_UNIX等。在內核中,每種類型的protocol family都會有一個相對應的net_proto_family結構,然后將這個結構注冊到內核的net_families數組中。我們創建socket的時候,實際上就是調用這個數組來創建socket。
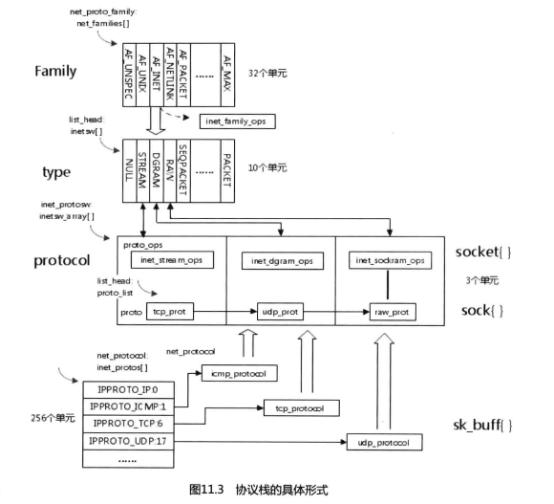
如圖11.3所示,每個協議簇和相應的套接口都對應有好多種組合,在協議簇的實現中保存了一個相應的結構來保存這些組合。通過family和套接口類型來得到這個結構,并賦值
給sock。需要鄭重聲明的是內核里的socket和sock是兩個不同的數據結構,其中socket是
一個general BSD socket,也就是應用程序和4層協議之間的一個接口,屏蔽掉了相關的4
層協議部分。而sock結構保存了socket所需要使用的4層協議的全部相關信息。socket和
sock這兩個結構體現了接口和實現分開的策略,Ross Bir00(① Linux內核級網絡代碼最早開發者。)還有意將socket和sock這兩個結
構都保存了對方的聯系方式——對方的指針,使得開發者很容易地從一方存取另一方。一個
完整的socket包含兩方面的信息:socket和inode。
struct socket_alloc (
struct socket socket;
struct inode vfs_inode;
); 當你open 一個socket的時候,系統會返回一個文件描述符fd,如何找到其對應的fd呢?我們可以使用“netstat -tunp”查看在文件中打開的tcp以及udp連接的進程以及本地和遠程的IP地址:
# netstat -taunp Active Internet connections (only servers) Proto Recv-QSend-Q Local Address Foreign Address State PID/Program name tcp 0 0 0. O . 0 . 0 :22 0.0.0.0 : * LISTEN 4024/sshd ...... tcp 0 0 :::22 : ::* LISTEN 4024/sshd
sshd所對應的PID是4024,然后在/proc目錄下通過find命令就可以找到相應的fd。
# find /proc 2>/dev/null I grep "/4024/fd/1" /proc/4024/task/4024/fd/1 /proc/4024/fd/1
?
ll /proc/4024/fd total 0 lrwx------ 1 root root 64 Mar 30 10:24 0 -> /dev/null 前三個文件描述符固定是標準輸入 標準輸出 標準錯誤 lrwx------ 1 root root 64 Mar 30 10:24 1 -> /dev/null lrwx------ 1 root root 64 Mar 30 10:24 2 -> /dev/null lrwx------ 1 root root 64 Mar 30 10:24 3 -> socket:[11669] lrwx------ 1 root root 64 Mar 30 10:24 4 -> socket:[11671] [root@steven ~]# cat /proc/4024/fd/3 cat: /proc/1531/fd/3: No such device or address [root@steven ~]# cat /proc/4024/fd/4 cat: /proc/1531/fd/4: No such device or address
參考 lsof命令:http://www.cnblogs.com/MYSQLZOUQI/p/4856977.html
?
?
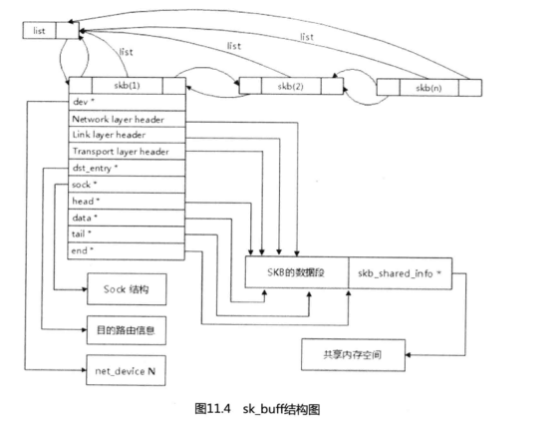
11 .4.3氣沉丹田:sk_buff
sk_ buff是Linux網絡代碼中最重要的數據結構,含義為“套接字緩沖區”,用于在Linux
網絡子系統中的各層之間傳遞數據,相當于Linux TCP/IP的“丹田”所在。它的創建者是
Linux的二號功臣Alan Cox。我搜索了一下內核代碼,發現有近八百處打了Alan Cox的標簽。
他原創了許多Linux下的網絡子系統的程序,并將編碼提供給不同的內核進行發布。可以說
沒有他,就沒有現在的Linux系統,沒有Linux系統上跑的TCP/IP協議。
一個好的系統離不開好的數據緒構,sk_buff提供很多成員變量供網絡代碼中各個子系統方便快捷地使用。sk_buff生命開始于網卡驅動接收函數,結束于socket應用層接口
① Linux內核級網絡代碼最早開發者。
(sock->port->sendmsg),也就是在接收和發送報文時Linux為sk_buff申請一整塊內存空間來放這個結構。結構里的眾多指針定義了不同協議的包頭,使得協議回溯、向前查找都可以直接進行。在實現中還包含了各種各樣的復制技巧,比如:克隆、共享數據、共享skb_buff等,節省了CPU操作時間。可能有的人抱怨sk buff結構定義過于龐大,有的變量在一些子系統中并不需要,但是計算機發展到今天,為了擁有更好的適應性和靈活性,犧牲部分空間是值得的。
由于操作系統每時每刻都有可能接收和發送大量報文,就需要頻繁申請釋放sk_buff。
sk_buff本身比較小,頻繁申請釋放內存就容易產生碎片。為了避免這個問題,sk_buff在申
請內存時也做了特殊的考慮,采用重復利用的原則。申請的skb buff內存在釋放時并沒有真
正釋放,而是放在一個緩存區中,以后有新的skb_buff中請時,就從緩存區中提取。
雖然sk_buff里的參數和指針定義眾多,但是由J:它的定義層次分明所以結構設計得清晰分明,其中主要有skb_buff鏈表參數、協議指針參數和數據緩存指針參數三大方面。掌握好這三個方面墓本上對它就有了整體的認識。圖11.4的sk_ buff結構圖對你理解sk_buff參數會有所幫助。
?
skb_buff像很多其他數據結構一樣被鏈表化,其作用是方便查找或者是連接數據結構本
身。內核可以把sk buff組織成一個雙向鏈表,結構要比常見的雙向鏈表的結構要復雜一點。
就像任何一個雙向鏈表一樣,sk _buff中有兩個指針next和prev,其中,next指向下一
個節點,而prev指向上一個節點。但是,這個鏈表還有另一個需求:每個sk_buff結構都必
須能夠很快找到鏈表頭節點。為了滿足這個需求,在第一個節點前面會插入另一個結構
sk_ buff_ head。這是一個輔助節點,它的定義如下:
struct sk_buf f_head {
/*These two members must be first. */
struct sk_buff * next;
struct sk—buff * prev;
___ u32 qlen;
spinlock_t lock;
};
sk_buff和sk_buff_head的前兩個元素是一樣的:next和prev指針,盡管 sk_buff_head要比sk_buff小得多。它們可以放到同一個鏈表中,要求這兩個指針必須放到結構定義的最前面。另外,相同的函數可以同樣應用于sk_buff和 sk_buff_head,qlen域表示了當前的sk _buff鏈上包含多少個skb。lock域是自旋鎖用于防止對鏈表的并發訪問。
為了使這個數據結構更靈活,每個sk_buff結構都包含一個指向 sk_buff_head的指針。
這個指針的名字是list。圖11.5會幫助你理解它們之間的關系。
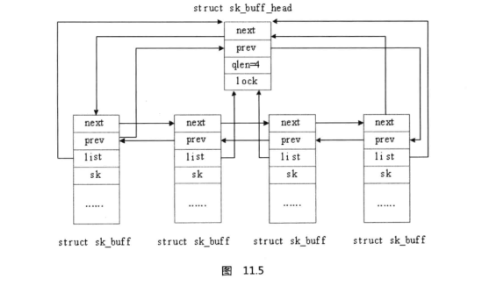
圖11.6你也一定不會陌生,掌握鏈路層、網絡層和傳輸層的數據格式是做好網絡設計開發的基礎。Sk_buff里的協議指針和它們的數據長度有關。
鏈路層幀格式
| 前導碼 8?bytes | 目的mac地址6?bytes | 源mac地址 6?bytes | 幀類型 2?bytes | 幀數據 46-1500bytes | Crc校驗 4?bytes |
網絡層數據包格式
| 4?bits | 4?bits | 8?bits | 3?bits | 13?bits |
| Version | IHL | Type?of?Service | Total??Length | |
| Identification | Flags | Fragmentation??Offset | ||
| Time?To?Live | Protocol | Header??Checksum | ||
| Source?Address | ||||
| Destination??Address | ||||
| Options | Padding | |||
| Data | ||||
傳輸層數據報文格式
| 4?bits | 6?bits | 6?bits | 16?bits |
| Source???Port | Destination?Port | ||
| Sequence?Number | |||
| Acknowledge?Munber | |||
| Data Offset | Reserved | Code | Window |
| Checksum | Urgent?Pointer | ||
| Options | Padding | ||
| Data | |||
圖11.6
sk_ buff定義了四個網絡層次,依次為1、傳輸層、2、網絡層、3、鏈路層和4、物理層,每個層次的
參數都是獨立的變量。sk buff對協議層次并沒有嚴格按照經典的網絡協議劃分,為了程序
處理的方便,TCP、UDP和ICMP分成一個層次,因為它們都是IP層協議號分出來的。
dev指向物理層,變量的類型是net_device,代表一個網絡設備。dev的作用取決于這個數據包是準備發出的包還是剛接收的包。當收到一個包時,設備驅動會把sk_buff的dev指針指向收到這個包的設備的數據結構。當一個包被發送時,這個變量代表將要發送這個包的設備。在發送網絡包時設置這個值的代碼要比接收網絡包時設置這個值的代碼復雜。為什么呢?因為有些網絡功能可以把多個網絡設備組成一個虛擬的網絡設備,這些設備沒有和物理設備直接關聯,并由一個虛擬網絡設備驅動管理。當虛擬設備被使用時,dev指針指向虛擬設備的net_device結構。而虛擬設備驅動會在一組設備中選擇一個設備并把dev指針修改為這個設備的net_device結構。因此,在某些情況下,指向傳輸設備的指針會在包處理過程中被改變。
transport_header、network_ header和mac_header分別是傳輸頭、網絡頭以及mac頭相對于sk_buff頭的偏移。這三個成員為內核編程人員提供了更便利的獲取傳輸層、網絡層和MAC層頭的偏移,偏移值的獲取和設置是通過偏移接口函數來實現的。
?
sk_buff的數據緩存區有七個變量:len、data_ len、true_size、head、data、tail、end,下圖可以幫你理解它們之間的聯系:
Head??????????????data?????????????????tail?????????????????End
| ? | ? | ? | Skb_shared_info |
←h?e?a?d?r?o?o?m???→?????????????????????←?????t?a?i?l?r?o?o?m?→???
圖11.7?sk_buff結構的數據指針
?
● len:全部的數據長度,它的計算公式為len= (tail - data)+ data_len。
● data_len:共享數據的長度,也就是skb_shared_ info結構里面保存的數據長度,可
以通過看data len的長度是否為0來判斷這個skb buff是否線性化。
● true_size:這是緩沖區的總長度,包括sk buff結構和數據部分。如果申請一個len
字節的緩沖區,alloc_skb函數會把它初始化成len+sizeof(sk_buff)。
head、end、data、tail,它們表示緩沖區和數據部分的邊界。在每一層申請緩沖區時,
它會分配比協議頭或協議數據大的空間。head和end指向緩沖區的頭部和尾部,而data和
tail指向實際數據的頭部和尾部。
headroom是指skb->data與skb->head之間的內存空間。每一層在head和data之間填充協議頭。
tailroom是指skb->end與skb->tail之間的內存空間。可以包含一個附加的頭部,添加新
的協議數據。
每個skb_buff結構的尾部空間都包含一個skb_shared_info結構,在申請內存空間時特別加上sizeof(skb_shared_info)。skb->end代表數據段的結尾,同時也是指向共享數據的指針,
這樣設計是有道理的。因為如果sk_buff沒有數據就無所謂共享數據了。所以end指針不代
表是真正的結尾,它指向一個skb_ shared_ info結構。把end從char轉換成skb shared_ info*
就能訪問這個結構,進行paged data和分片的管理。Linux捉供一個宏來做這種轉換:
#defne skb_shinfo(SKB) ((struct skb_shared_info *)(skb_end_pointer(SKB)))
在這里提醒大家一定要使用skb結構提供的宏或函數操作指針,自己移動指針很容易
出錯。
在緩沖區數據的末尾,有一個數據結構skb_shared_info,它保存了數據塊的附加信息。
這個數據結構緊跟在end指針所指的地址之后(end指針指示數據的末尾)。下面是這個結構的定義:
struct skb_shared_info { atomic_t dataref; unsigned int nr_frags; unsigned short tso_size; unsigned short tso_seqs; struct sk_buff *frag_list; skb_frag_t frags[ MAX_SKB_FRAGS]; };
dataref表示數據塊的“用戶”數,nf_frags、frag_list和frags用于存儲IP分片。skb_is nonlinear函數用于測試一個緩沖區是否是分片的,而skb_linearize可以把分片組合成一個單一的緩沖區。組合分片涉及數據拷貝,它將嚴重影響系統性能。為了提高性能,有些網卡硬件可以計算L3和L4和校驗和,甚至可以維護L4協議的狀態機。
需要注意的是:sk_buff中沒有指向skb_shared_info結構的指針。如果要訪問這個結構,
就需要使用skb_info宏,這個宏簡單地返回end指針:
#defrne_skb_shinfo(SKB) ((struct skb_shared_info*)((SKB)->end))
例如使用這個宏來增加結構中的某個成員變量的值:
skb_shinfo( skb) ->dataref++;
Skb_shared info結構也可以包含一個sk_buff的鏈表(鏈表名稱是frag_list)。這個鏈表
在pskb_copy和skb_copy中的處理方式與frags數組的處理方式相同。
在include/linux/skbuff.h和net/core/skbuffc中每個函數基本上都有兩個版本,名字分別
是do_something和_do_something。通常第一種函數是一個包裝函數,它會在第二種函數的
基礎上增加合法性檢查或者鎖。一般來說,類似_do_something的函數不能被直接調用。
操作函數分為內存操作函數、數據段操作函數和鏈表管理函數三大類,其中內存操作函
數有alloc_ skb、dev_alloc_skb、kfree_skb、dev_ kfree_ skb、skb_clone、pskb_copy、skb_copy
和skb_copy_expand等;數據段操作函數有skb_put、skb_push、skb_pull相skb_reserve等:
鏈表管理函數有skb_queue_head_init、skb_queue_head、skb_queue_tail、skb_dequeue、
skb_dequeue_ tail、skb_queue_purge和skb_queue_walk等。結合上面對參數的講解,對照函數實現源碼,操作函數的具體含義還是不難理解的,這里就不贅述了。
?
11.5 臨戰雜談
再霸氣的神功缺乏臨戰經驗的話,也有可能被人揍得滿頭包。為了避免這種問題的發生,
我不得不列舉一些我經歷過的事兒。如果你不認同的話,就當我是閑扯吧。
11 .5.1 對UDP的錯誤的認識
我發現很多人不太愛用UDP,對UDP存有偏見,愛憎分明的我不得不為它吐吐槽。
比起TCP來,UDP的優勢在于速度快,而且不需要維護數據流,還能防止意想不到的欺騙。
我遇到這么一個項目,在nginx上設計一個add-on模塊做局域網轉發。由于最終實現的服務部署在本機或局域網中,我建議通過UDP方式實現服務的調用。當時就有人跳起來跟我爭論,反對使用UDP。理由是UDP是無連接的,容易丟包,有時序問題,不可靠。這是徹頭徹尾的教條主義,沒有調查研究就沒有發言權!
首先,在本地或局域網中不存在時序問題。時序問題的產生是因為數據包可能走過不同路由。
局域網內不存在這種情況,也就不用理會它。另外我可以負責任地說,雖然UDP是無連接,
但它在局域網中傳輸丟包的概率是微乎其微的。局域網使用的交換機對數據有很強
的恢復功能。如果在局域網中你的程序出現丟包的現象,你還是先檢查一下自己程序寫得是
否合理。一般的丟包都是應用寫得不合理造成的,比如接收不及時導致接收緩沖區滿了,后
面的包覆蓋了前面的包,從而導致‘丟包”。接收UDP數據包的函數盡量不要和處理UDP數據包的函教在一個線程,否則就可能導致收包不及時的問題發生。收包線程的全部工作就是不停地讀,把接收完的數據放在隊列中。
還有人提出峰值數據量過大會引起計算機忙而丟包。我做過24路1080p 30mbps碼流的
視頻直播服務,畫面清晰不丟幀,沒有馬賽克。運算設計得簡單,如果是CBR的視頻流,
使用720mbps帶寬,在干兆網環境下是沒有任何問題的。到目前為止我做的轉發服務還沒有超過這個峰值數據量。有人使用tcpdump驗證我的說法,向我反映即便是局域網也有“x
packets dropped by kernel”。但是造成這種丟包的原因是由于libpcap抓到包后,tcpdump上
層沒有及時地取出,導致libpcap緩沖區溢出,從而覆蓋了未處理包。雖然tcpdump工具顯
示被kernel丟棄,但是并不是說真正是被Linux內核拋棄的,而是被其所使用的動態庫libpcap
拋棄。這時候如果是你寫的服務,還是可以正常獲取數據的。當然我們是有辦法來改善tcpdump上層的處理效率減少丟包。例如抓包時最小化抓取過濾范圍,即通過指定網卡、端口、包流向、包大小來減少處理包的數量;添加-n參數,禁止反向域名解析;調節/proc/sys/net/core/rmem一default和/proc/sys/netjcore/rmem_max參數改變sk_ rcvbuf的大小等。
tcpdump
-nn :來源ip和目標ip都用數字顯示
-i :指定網卡 默認是第一個網卡
host:可以寫源ip 也可以寫目標ip
port :指定端口
dst 192.168.31.147
src dst 192.168.31.147
可能還有人會問:“很多教科書上都說UDP容易丟包呀。”這要看在什么應用場景下。
不能生搬硬套。在經過路由器的情況有時是會出現丟包的。依我的實際經驗,在過二三級路
由以后,由于數據流量繁忙和TTL等原因可能會出現丟包的現象。
所以凡涉及本機或局域網內通信的案例,都可以考慮使用UDP。因為這個東西無連接,
處理起來相當簡單,性能極高。這種情況下使用TCP很浪費CPU資源。因為根本都不丟包,
每次TCP的流控還要評估網絡環境。
?
?
11 .5.2事半功倍,調節內核參數①
Linux標準的發行版不可能知道你目前運行的網絡環境,所以還得靠你自己利用可以調
節的內核參數動態優化TCP[IP棧。例如長連接會占用大量資源,在大并發的情況下,連接
過多將導致無數的連接失敗。通常Apache采用短連接,nginx采用短連接,MySQI采用短
連接。但是短連接可能會導致TIME_ WAIT增多。TIME_WAIT的增多一般不會有太大的問題,但是大量的TIME—WAIT套接字也會把squid等網絡應用給拖死。這時,調節幾個內核參數就能搞定:
tw:time_wait # ehc0 1> /proc/sys/net/ipv4/tcp_tw_reuse # ehc0 1>/proc/sys/net/ipv4/tcp_tw_recycle # ech0 6000>/proc/sys/net/ipv4/tcp_max_tw_buckets
reuse是表示是否允許新的TCP連接重新應用處于TIME_WAIT狀態的socket; recycle
是加速TIME_WAIT sockets回收;max _tw _buckets表示TIME_WAIT套接字的最大數量,如
果超過這個數字,TIME_WAIT饔接字將立刻被清除并打印警告信息。這些設置提高了處理
效率,還能把TIME_WAIT所占用內存控制在一定范圍。
表11-3列出了一些內核可以調節的參數,幫助你了解內核參數的含義。在后面的章節
中,我會利用nginx的實際案例說明調節內核參數的重要作用。
?
TCP連接狀態圖
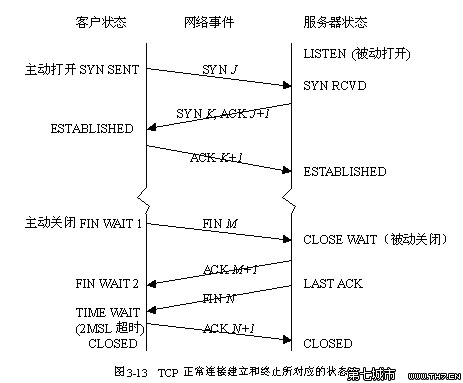
三次握手
客戶端 主動syn sent 一次握手
服務器端 syn rcvd 一次握手
客戶端 established 一次握手 syn+ack服務器端
服務器端 established
四次揮手
客戶端 主動fin wait1 一次揮手
服務器端 close wait 一次揮手
客戶端 fin wait2 一次揮手
客戶端 time wait 一次揮手 last ack服務器端
服務器端 closed
?
表11-3??一些內核可以調節的參數
| 可調節的參數 | 默認值 | 選項說明 |
| /proc/sys/net/core/rmem_?default | "110592" | 定義默認的接收窗口大小 |
| /proc/sys/net/core/rmem_max | "110592" | 定義接收窗口的最大大小? |
| /proc/sys/net/core/wmem_default | "110592" | 定義默認的發送窗口大小 |
| /proc/sys/net/core/wmem_max | "110592" | 定義發送窗口的最大大小?? |
| /proc/sys/net/ipv4/tcp_window_scaling | "1" | 要支持超過64KB的窗口,必須啟用該值? |
| /proc/sys/net/ipv4/tcp_sack | "1" | 有選擇地應答亂序接收到的報文來提高性能,讓發送者只發送丟失的報文;對于廣域網通信來說,這個選項應該啟用,但是這會增加對CPU的占用 |
| /proc/sys/net/ipv4/tcp_fack | "1" | 啟用轉發應答? |
| /proc/sys/net/ipv4/tcp_timestamps | "1" | 以一種比重發超時更精確的方法來啟用對RTT的計算;為了實現更好的性能應該啟用這個選項 |
????????????????????????????
①有興趣的話可參考czmmiao的博客http://czmmiao.iteye.comfblo∥1054966。
(續)
| 可調節的參數 | 默認值 | 選項說明 |
| /proc/sys/neVipv4/tcp_mem | “24576 32768 49152” | 確定TCP棧應該如何反映內存使用:每個值的單位都是內存頁(通常是4KB)。第一個值是內存使用的下限。第二個值是內存壓力模式開始對緩沖區使用應用壓力的上限。第三個值是內存上限,超過?這個層次可以將報文丟棄,從而減少對內存的使用。對于較大的BDP可以增大這些值(但是要記住,其單位是內存頁,而不是字節)????? |
| /proc/sys/netjipv4/tcp_wmem? | “4096 16384 131072” | 自動調優定義每個socket使用的內存。第一個值是為socket的發送緩沖區分配的最少字節數。第二個值是默認值(該值會被wmem_default覆蓋),緩沖區在系統負載不重的情況下可以增長到這個值。第三個值是發送緩沖區空間的最大字節數(該值會被wmem_max覆蓋) |
| /proc/sys/netjipv4/tcp_rmem | “4096 87380 174760” | 與tcp_wmem類似,它表示的是為自動調優所使用的接收緩沖區的值? |
| /proc/sys/net/ipv4/tcp_low_latency | “0” | 允許TCP/IP棧適應在高吞吐量情況下低延時的情況;這個選項應該禁用 |
| /proc/sys/net/ipv4/tcp_westwood | “0” | 啟用發送者端的擁塞控制算法,它可以維護對吞吐量的評估,并試圖對帶寬的整體利用情況進行優化;對于WAN通信來說應該啟用這個選項 |
| /proc/sys/net/ipv4/tcp_bic | “1” | 為快速長距離網絡啟用Binary?Increase (Congestion擁塞);這樣可以更好地利用以GB速度進行操作的鏈接;對于WAN通信應該啟用這個選項 |
從上表中我們了解了一些TCP/IP運行參數及其含義,在前面我們使用echo命令向/proc/sys/目錄下的可寫文件中設置數值。實際上還有代替這個功能的命令sysctl。sysctl是用
來在系統運作中查看及調整在/proc/sys/目錄下的系統參數的,系統參數不僅包含TCP/IP堆棧設置,還包括與虛擬內存系統有關的高級選項。
首先我們使用sysctl讀取一個指定變量的值,例如讀取并發連接數kern.ipc.somaxconn,
命令如下:
# sysctl kern.ipc.Somaxconn
kern.ipc.Somaxconn: 3000
為了對在/proc/sys/目錄下的可配置項有個快速的總體了解,輸入sysctl—a命令就會產生一個大型綜合列表供你參考。當然你也可以查看目錄下的每個文件獲取同樣的信息,但那不是麻煩嗎。
接下來我們設置一個指定參數的數值,可以直接用variable=value方式來實現,例如:
為了防止DOS攻擊可用如下命令開啟syscookies功能:
# sysctl net.inet.tcp.syncookies=1 #路徑相當于/proc/sys/net/inet/tcp/syncookies 想必你發現了sysctl參數操作的時候不用寫全整個路徑,例如/proc/sys/net/ipv4/tcp_tw_
reuse文件,我們設置參數時使用net.ipv4.tcp_tw_reuse這種形式,目錄斜杠被點符號代替,
proc.sys也假設已存在。
用sysctl設置的參數值只是臨時起作用,如果你重啟Linux系統,那么你剛用sysctl設
置的內核參數都會恢復原狀。為了在系統啟動時保留你的這些參數配置,你應該把對應的參
數值寫入/etc/sysctl.conf中。每次系統啟動時,init程序會運行/etc/rc.d/rc.sysinit胛本。這個
腳本包含了獲取/etc/sysctl.conf配置參數以及執行sysctl命令向內核傳遞參數的代碼,所以任何加入/etc/sysctl.conf的數值在每次系統啟動后會生效。
讀取內核參數 sysctl -a #讀取全部內核參數 sysctl kern.ipc.Somaxconn #讀取某個內核參數設置內核參數 sysctl kern.ipc.Somaxconn=3000 echo 3000>/proc/sys/kern/ipc/Somaxconn永久設置內核參數 /etc/sysctl.conf
?
?
?
f