準備材料
一:使用到的Python第三方庫是requests 和 BeautifulSoup
python gui,二:選擇要爬取的網頁
我選擇了豆瓣小組里的一個帖子回復(是微博或者微信的簽名,個人感覺比較有意思)
地址是:https://www.douban.com/group/topic/80125952/
python 類、三:分析網頁源代碼
打開地址后,右鍵-查看網頁源代碼
我們爬取的p標簽,class="reply-content"里的內容
python3.7?14345926-4252580093d33a3b.png
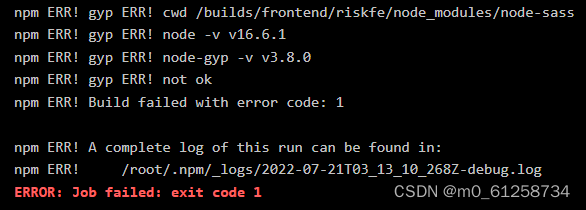
具體的代碼如下
import requests
python3。from bs4 import BeautifulSoup
import time
#設置請求header偽裝成瀏覽器
headers = {'user-agent':'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1'}
for i in range(29):
url = 'https://www.douban.com/group/topic/80125952/?start=' + str(i*100)
req = requests.get(url,headers=headers) #獲取網頁請求
content = req.content #獲取到的網頁請求的具體內容
soup = BeautifulSoup(content,'lxml') #把獲取到的網頁請求內容構造成 BeautifulSoup 對象
replycontents = soup.find_all(name='p',attrs={'class':'reply-content'})# 使用 find_all 查找文檔樹中標簽為p,class="reply-content" 的所有內容
try:
for replycontent in replycontents:
text = replycontent.string
print(text)
except:
TypeError
time.sleep(5)
運行的結果部分截圖如下
14345926-914b656a5db2a921.png
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态