一、目的 :
爬取晉江文學網總分榜
二、python爬取數據
三、爬取

用python爬取小說?在開始多出現了38號而且順序內容不準確
代碼:
import requests
from bs4 import BeautifulSoup
import bs4
python爬蟲有什么用?url="http://www.jjwxc.net/topten.php?orderstr=7&t=0"
def getHtml(url):
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
爬蟲爬取數據、return r.text[26000:100000]
def fillList(html):
l1,l2 = [],[]
soup = BeautifulSoup(html,"html.parser")
for i in soup.find_all('a',"tooltip"):
python爬小說。l1.append(str(i.string))
for tag in soup.find_all('td',{"align":"center"}):
s=str(tag.string)
s.replace(" "," ")
l2.append(s)
python爬蟲教程,return l1,l2
def printList(l1,l2):
n1,n2 = len(l1),len(l2)
n=max(n1,n2)
for i in range(n):
python有什么用。print("第{}名:《{}》".format(i+1,l1[i]))
print("積分:{}".format(l2[i]))
print("")
def main():
html=getHtml(url)
用python爬取網站數據、l1,l2=fillList(html)
printList(l1,l2)
main()
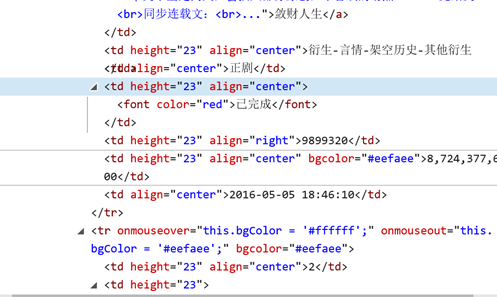

這幾類數據我分不開,絕望
百度了一下就發現

python爬蟲網站?內容網址:https://www.cnblogs.com/wangyongfengxiaokeai/p/11869595.html
而且好像height=‘23’和alig前后位置不同對結果也有影響
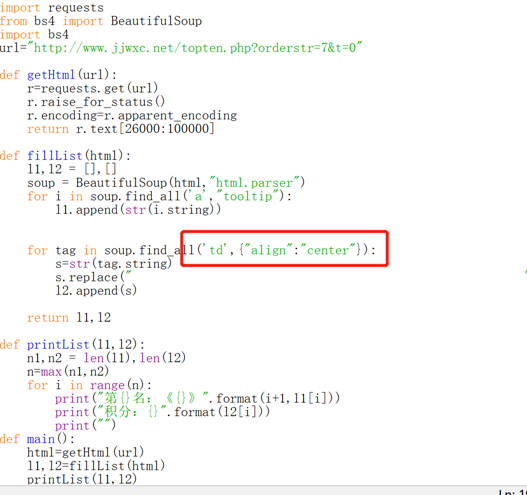
又換了試就發現是紅框的問題,但是紅框內換了幾次代碼還是都不能完全分開,最后只有l2中為作品字數時可以完全帶進去,但是字數在這里沒有什么實際價值。
就只能做出排名


🆗
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态