python多線程并發、前言:為什么有人說 Python 的多線程是雞肋,不是真正意義上的多線程?
關于多線程,多進程的詳細介紹 可閱讀此篇blog
這里自己用白話簡單概括一下(非準確):
- 一個要執行的程序(應用)可以看作一個進程
- 改程序里的一串代碼指令(或一個函數)看作是進程里的一個線程。(main函數就是主線程)
Python web框架?首先需要明確的一點是GIL并不是Python的特性,它是在實現Python解析器(CPython)時所引入的一個概念。
其他語言,CPU是多核時 是支持多個線程同時執行。但在Python中,無論是單核還是多核,同時只能由一個線程在執行。
其根源是GIL的存在。GIL的全稱是Global Interpreter Lock(全局解釋器鎖),來源是Python設計之初的考慮,為了數據安全所做的決定。
python 圖形界面。某個線程想要執行,必須先拿到GIL,我們可以把GIL看作是“通行證”,并且在一個Python進程中,GIL只有一個。拿不到通行證的線程,就不允許進入CPU執行。
而目前Python的解釋器有多種,例如:
CPython: CPython是用C語言實現的Python解釋器。 作為官方實現,它是最廣泛使用的Python解釋器。
python 命令行參數,PyPy: PyPy是用RPython實現的解釋器。RPython是Python的子集, 具有靜態類型。這個解釋器的特點是即時編譯,支持多重后端(C, CLI, JVM)。PyPy旨在提高性能,同時保持最大兼容性(參考CPython的實現)。
Jython: Jython是一個將Python代碼編譯成Java字節碼的實現,運行在JVM (Java Virtual Machine) 上。另外,它可以像是用Python模塊一樣,導入并使用任何Java類。
IronPython: IronPython是一個針對 .NET 框架的Python實現。它可以用Python和 .NET framework的庫,也能將Python代碼暴露給 .NET框架中的其他語言。
GIL只在CPython中才有,而在PyPy和Jython中是沒有GIL的。
每次釋放GIL鎖,線程進行鎖競爭、切換線程,會消耗資源。這就導致打印線程執行時長,會發現耗時更長的原因。
并且由于GIL鎖存在,Python里一個進程永遠只能同時執行一個線程(拿到GIL的線程才能執行),這就是為什么在多核CPU上,Python 的多線程效率并不高的根本原因。
multiprocess模塊(python多進程庫)完全模仿了threading模塊的接口,二者在使用層面,有很大的相似性。
Python提供兩個模塊進行多線程的操作,分別是thread和threading,前者是比較低級的模塊,用于更底層的操作,一般應用級別的開發不常用。
import threading# 這個函數名可隨便定義
def run(n):print("current task:", n)if __name__ == "__main__":t1 = threading.Thread(target=run, args=("thread 1",))t2 = threading.Thread(target=run, args=("thread 2",))t1.start()t2.start()
from threading import Thread
import time
def sayhi(name):time.sleep(2)print('%s say hello' %name)if __name__ == '__main__':t=Thread(target=sayhi,args=('egon',))t.start()print('主線程')
import threadingclass MyThread(threading.Thread):def __init__(self, n):super(MyThread, self).__init__() # 重構run函數必須要寫self.n = ndef run(self):print("current task:", n)if __name__ == "__main__":t1 = MyThread("thread 1")t2 = MyThread("thread 2")t1.start()t2.start()
from threading import Thread
import time
class Sayhi(Thread):def __init__(self,name):super().__init__()self.name=namedef run(self):time.sleep(2)print('%s say hello' % self.name)if __name__ == '__main__':t = Sayhi('egon')t.start()print('主線程')
join函數執行順序是逐個執行每個線程,執行完畢后繼續往下執行。主線程結束后,子線程還在運行,join函數使得主線程等到子線程結束時才退出。
import threadingdef count(n):while n > 0:print(n)n -= 1if __name__ == "__main__":t1 = threading.Thread(target=count, args=(10",))t2 = threading.Thread(target=count, args=(10,))t1.start()t2.start()# 將 t1 和 t2 加入到主線程中t1.join()t2.join()
線程之間數據共享的。當多個線程對某一個共享數據進行操作時,就需要考慮到線程安全問題。threading模塊中定義了Lock 類,提供了互斥鎖的功能來保證多線程情況下數據的正確性。
用法的基本步驟:
#創建鎖
mutex = threading.Lock()
#鎖定
mutex.acquire([timeout])
#釋放
mutex.release()------模板:--------
R=threading.Lock()
R.acquire()
'''
對公共數據的操作
'''
R.release()
解釋:
一把鎖有兩個狀態:locked 和 unlocked 狀態。鎖剛被創建的時候是處于 unlocked 狀態。
lock.acquire() 會讓鎖從 unlocked -> locked。
lock.release() 會讓鎖從 locked -> unlocked。
如果鎖已經處于 locked 狀態,對它使用 acquire() 的線程會被阻塞,直到另一個線程調用了 release() 使該鎖解鎖。
release()方法只能在鎖locked時調用,并釋放鎖。否則會拋出RuntimeError錯誤。
其中,鎖定方法acquire可以有一個超時時間的可選參數timeout。如果設定了timeout,則在超時后通過返回值可以判斷是否得到了鎖,從而可以進行一些其他的處理。具體用法見示例代碼:
import threading
import timenum = 0
mutex = threading.Lock()class MyThread(threading.Thread):def run(self):global num time.sleep(1)if mutex.acquire(1): num = num + 1msg = self.name + ': num value is ' + str(num)print(msg)mutex.release()if __name__ == '__main__':for i in range(5):t = MyThread()t.start()
另一個示例:
import threading
import time
from queue import Queuedef a():global A,locklock.acquire()for i in range(10):A+=1print("a",A)lock.release()def b():global A,locklock.acquire()for i in range(10):A+=10print("b",A)lock.release()if __name__ == '__main__':lock = threading.Lock()A=0t1=threading.Thread(target=a,)t2=threading.Thread(target=b,)t1.start()t2.start()輸出結果:
a 1
a 2
a 3
a 4
a 5
a 6
a 7
a 8
a 9
a 10
b 20
b 30
b 40
b 50
b 60
b 70
b 80
b 90
b 100
b 110
進程也有死鎖與可重入鎖,使用方法都是一樣的,所以放到這里一起說:
所謂死鎖: 是指兩個或兩個以上的進程或線程在執行過程中,因爭奪資源而造成的一種互相等待的現象,若無外力作用,它們都將無法推進下去。此時稱系統處于死鎖狀態或系統產生了死鎖,這些永遠在互相等待的進程稱為死鎖進程,如下就是死鎖。
示例1.
from threading import Lock as Lock
import timemutexA=Lock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
示例2. 科學家吃面
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):noodle_lock.acquire()print('%s 搶到了面條'%name)fork_lock.acquire()print('%s 搶到了叉子'%name)print('%s 吃面'%name)fork_lock.release()noodle_lock.release()def eat2(name):fork_lock.acquire()print('%s 搶到了叉子' % name)time.sleep(1)noodle_lock.acquire()print('%s 搶到了面條' % name)print('%s 吃面' % name)noodle_lock.release()fork_lock.release()for name in ['哪吒','egon','yuan']:t1 = Thread(target=eat1,args=(name,))t2 = Thread(target=eat2,args=(name,))t1.start()t2.start()
解決方法:使用可重入鎖
為了滿足在同一線程中多次請求同一資源的需求,Python提供了可重入鎖(RLock)。
RLock內部維護著一個Lock和一個counter變量,counter記錄了acquire
的次數,從而使得資源可以被多次require。直到一個線程所有的acquire都被release,其他的線程才能獲得資源。
具體用法如下:
#創建 RLock
mutex = threading.RLock()class MyThread(threading.Thread):def run(self):if mutex.acquire(1):print("thread " + self.name + " get mutex")time.sleep(1)mutex.acquire()mutex.release()mutex.release()
對應上面兩個死鎖問題,可以按照如下寫法解決:
示例1.
from threading import RLock
import time
mutexA=RLock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
示例2. 科學家吃面
import time
from threading import Thread,RLock
fork_lock = noodle_lock = RLock()
def eat1(name):noodle_lock.acquire()print('%s 搶到了面條'%name)fork_lock.acquire()print('%s 搶到了叉子'%name)print('%s 吃面'%name)fork_lock.release()noodle_lock.release()def eat2(name):fork_lock.acquire()print('%s 搶到了叉子' % name)time.sleep(1)noodle_lock.acquire()print('%s 搶到了面條' % name)print('%s 吃面' % name)noodle_lock.release()fork_lock.release()for name in ['哪吒','egon','yuan']:t1 = Thread(target=eat1,args=(name,))t2 = Thread(target=eat2,args=(name,))t1.start()t2.start()
無論是進程還是線程,都遵循:守護xx會等待主xx運行完畢后被銷毀。 需要強調的是:
運行完畢并非終止運行
- #1.對主進程來說,運行完畢指的是主進程代碼運行完畢
- #2.對主線程來說,運行完畢指的是主線程所在的進程內所有非守護線程統統運行完畢,主線程才算運行完畢
#1 主進程在其代碼結束后就已經算運行完畢了(守護進程在此時就被回收),然后主進程會一直等非守護的子進程都運行完畢后回收子進程的資源(否則會產生僵尸進程),才會結束,
#2 主線程在其他非守護線程運行完畢后才算運行完畢(守護線程在此時就被回收)。因為主線程的結束意味著進程的結束,進程整體的資源都將被回收,而進程必須保證非守護線程都運行完畢后才能結束。
如果希望主線程執行完畢之后,不管子線程是否執行完畢都隨著主線程一起結束。我們可以使用setDaemon(bool)函數,它跟join函數是相反的。
它的作用是設置子線程是否隨主線程一起結束,必須在start() 之前調用,默認為False。
看下示例
from threading import Thread
import time
def sayhi(name):time.sleep(2)print('%s say hello' %name)if __name__ == '__main__':t=Thread(target=sayhi,args=('egon',))t.setDaemon(True) #必須在t.start()之前設置t.start()print('主線程')print(t.is_alive())'''主線程True'''
from threading import Thread
import time
def foo():print(123)time.sleep(1)print("end123")def bar():print(456)time.sleep(3)print("end456")t1=Thread(target=foo)
t2=Thread(target=bar)t1.daemon=True
t1.start()
t2.start()
print("main-------")
如果需要規定函數在多少秒后執行某個操作,需要用到Timer類。具體用法如下:
from threading import Timerdef show():print("Pyhton")# 指定一秒鐘之后執行 show 函數
t = Timer(1, hello)
t.start()
Thread實例對象的方法# isAlive(): 返回線程是否活動的。# getName(): 返回線程名。# setName(): 設置線程名。threading模塊提供的一些方法:# threading.currentThread(): 返回當前的線程變量。# threading.enumerate(): 返回一個包含正在運行的線程的list。正在運行指線程啟動后、結束前,不包括啟動前和終止后的線程。# threading.activeCount(): 返回正在運行的線程數量,與len(threading.enumerate())有相同的結果。
from threading import Thread
import threading
from multiprocessing import Process
import osdef work():import timetime.sleep(3)print(threading.current_thread().getName())if __name__ == '__main__':#在主進程下開啟線程t=Thread(target=work)t.start()print(threading.current_thread().getName())print(threading.current_thread()) #主線程print(threading.enumerate()) #連同主線程在內有兩個運行的線程print(threading.active_count())print('主線程/主進程')'''打印結果:MainThread<_MainThread(MainThread, started 140735268892672)>[<_MainThread(MainThread, started 140735268892672)>, <Thread(Thread-1, started 123145307557888)>]主線程/主進程Thread-1'''代碼示例
GIL保護的是Python解釋器級別的數據資源,自己代碼中的數據資源就需要自己加鎖防止競爭。如下圖:
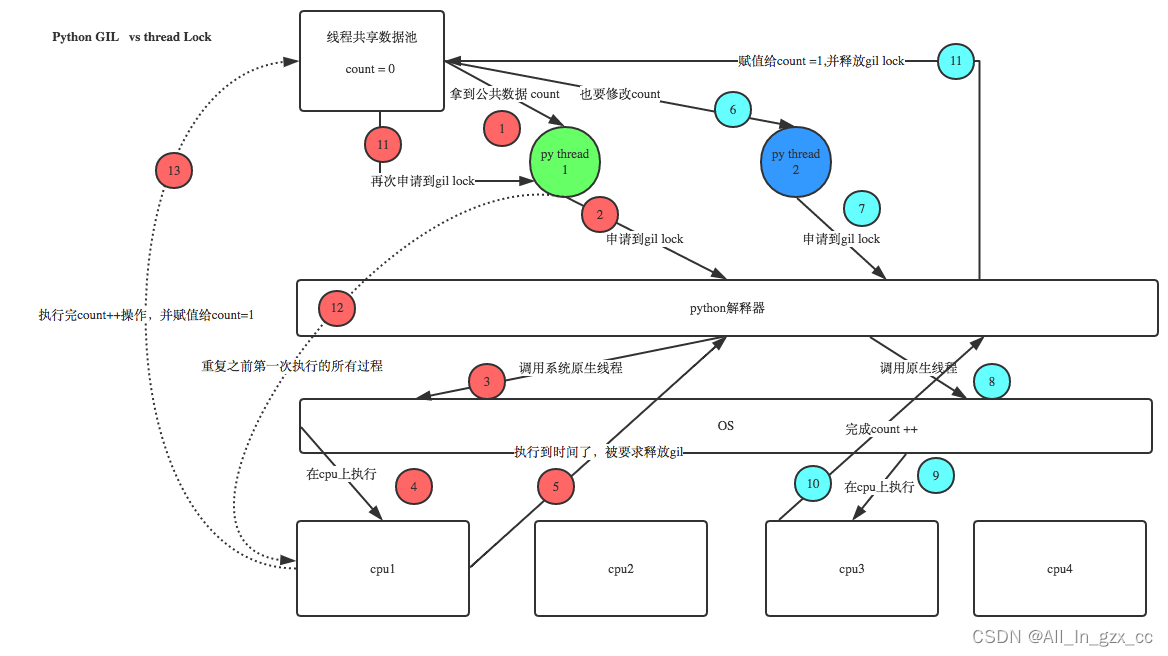
有了GIL的存在,同一時刻同一進程中只有一個線程被執行,進程可以利用多核,但是開銷大,而Python的多線程開銷小,但卻無法利用多核優勢,也就是說Python這語言難堪大用。
其實編程所解決的現實問題大致分為IO密集型和計算密集型。
對于IO密集型的場景,
Python的多線程編程完全OK,
而對于計算密集型的場景,Python中有很多成熟的模塊或框架如Pandas等能夠提高計算效率。
#不加鎖:并發執行,速度快,數據不安全
from threading import current_thread,Thread,Lock
import os,time
def task():global nprint('%s is running' %current_thread().getName())temp=ntime.sleep(0.5)n=temp-1if __name__ == '__main__':n=100lock=Lock()threads=[]start_time=time.time()for i in range(100):t=Thread(target=task)threads.append(t)t.start()for t in threads:t.join()stop_time=time.time()print('主:%s n:%s' %(stop_time-start_time,n))'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:0.5216062068939209 n:99
'''#不加鎖:未加鎖部分并發執行,加鎖部分串行執行,速度慢,數據安全
from threading import current_thread,Thread,Lock
import os,time
def task():#未加鎖的代碼并發運行time.sleep(3)print('%s start to run' %current_thread().getName())global n#加鎖的代碼串行運行lock.acquire()temp=ntime.sleep(0.5)n=temp-1lock.release()if __name__ == '__main__':n=100lock=Lock()threads=[]start_time=time.time()for i in range(100):t=Thread(target=task)threads.append(t)t.start()for t in threads:t.join()stop_time=time.time()print('主:%s n:%s' %(stop_time-start_time,n))'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:53.294203758239746 n:0
'''#有的同學可能有疑問:既然加鎖會讓運行變成串行,那么我在start之后立即使用join,就不用加鎖了啊,也是串行的效果啊#沒錯:在start之后立刻使用jion,肯定會將100個任務的執行變成串行,毫無疑問,最終n的結果也肯定是0,是安全的,但問題是#start后立即join:任務內的所有代碼都是串行執行的,而加鎖,只是加鎖的部分即修改共享數據的部分是串行的
#單從保證數據安全方面,二者都可以實現,但很明顯是加鎖的效率更高.
from threading import current_thread,Thread,Lock
import os,time
def task():time.sleep(3)print('%s start to run' %current_thread().getName())global ntemp=ntime.sleep(0.5)n=temp-1if __name__ == '__main__':n=100lock=Lock()start_time=time.time()for i in range(100):t=Thread(target=task)t.start()t.join()stop_time=time.time()print('主:%s n:%s' %(stop_time-start_time,n))'''
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.6937336921692 n:0 #耗時是多么的恐怖
''')
參考鏈接:
https://blog.csdn.net/zong596568821xp/article/details/99678390
https://www.cnblogs.com/haitaoli/articles/10302508.html
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











