轉載請標明出處:
http://blog.csdn.net/hesong1120/article/details/78990975
本文出自:hesong的專欄
使用爬蟲爬取網站的信息常常會遇到的問題是,你的爬蟲行為被對方識別了,對方把你的IP屏蔽了,返回不了正常的數據給你。那么這時候就需要使用代理服務器IP來偽裝你的請求了。
免費代理服務器網站有:
- 西刺免費代理IP
- 快代理
- 66免費代理
下面我們以西刺免費代理IP為例子看看是如何獲取可用IP的。主要分為以下幾個步驟:
1. 請求url,獲取網頁數據
2. 解析網頁數據,找到包含【IP地址】和【端口】信息的節點,解析出這兩個數據
3. 驗證取得的【IP地址】和【端口】信息是否可用
4. 將驗證可用的【IP地址】和【端口】信息保存起來(暫存到列表,或保存到文件,保存到數據庫)
請求網頁數據是使用requests庫去做網絡請求的,填入url,和header頭部信息,使用get請求方式去請求,得到response相應后,返回response.text即是響應的文本內容,即網頁文本內容。
# 請求url,獲取網頁數據
def _requestUrl(index):src_url = 'http://www.xicidaili.com/nt/'url = src_url + str(index)if index == 0:url = src_urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'}response = requests.get(url, headers=headers)return response.text代理服務器、用瀏覽器打開網址看一下
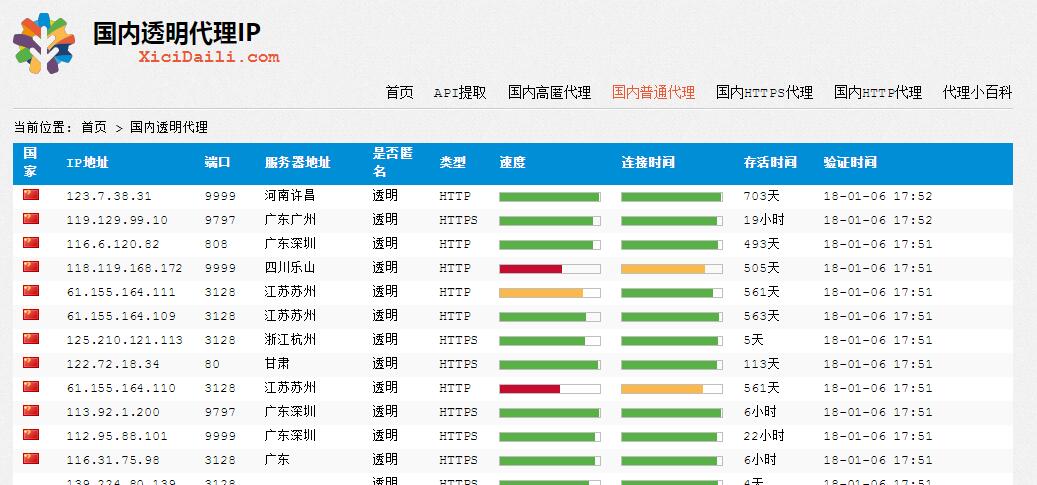
返回正確的網頁數據之后,就可以開始對它進行解析了,這里使用BeautifulSoup庫進行網頁內容解析。如果是Chrome瀏覽器,按f12可以查看網頁源碼,如圖
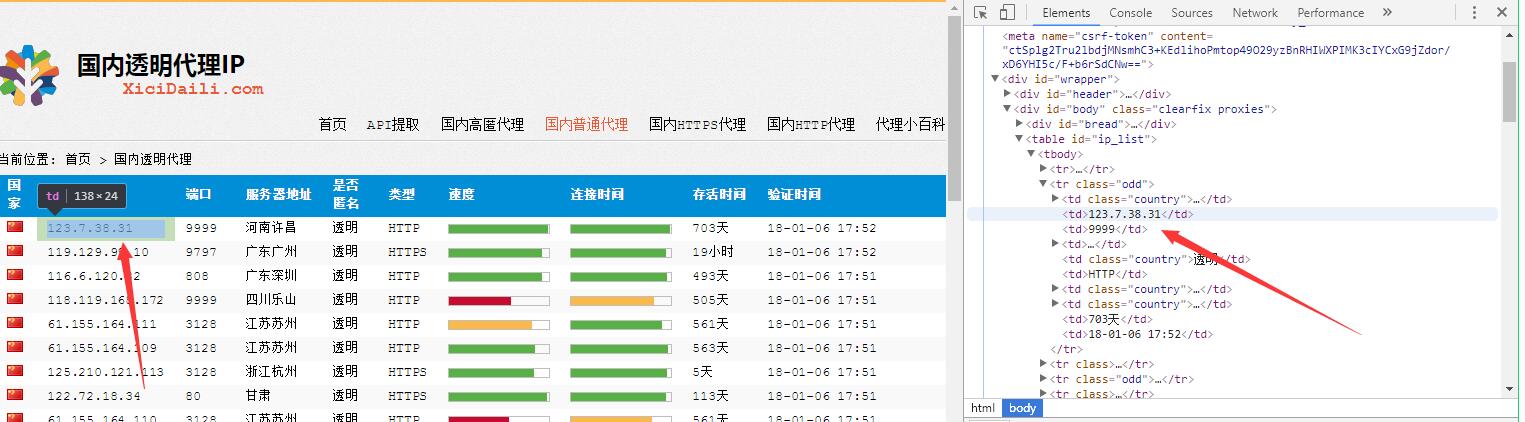
找到某個tr行,第1個和第2個td列就是是ip和端口信息,因此我們可以用BeautifulSoup查找所以的tr行,再查找該tr行的第1個和第2個td列即可以獲取該頁面上所有的ip和端口信息了。
# 解析網頁數據,獲取ip和端口信息
def parseProxyIpList(content):list = []soup = BeautifulSoup(content, 'html.parser')ips = soup.findAll('tr')for x in range(1, len(ips)):tds = ips[x].findAll('td')ip_temp = 'http://' + tds[1].contents[0] + ':' + tds[2].contents[0]print('發現ip:%s' % ip_temp)list.append(ip_temp)return list解析到頁面上的所有ip和端口信息后,還需要驗證它是否是有效的,然后對它們進行過濾,獲取有效的ip列表。驗證方法就是使用它作為代理地址,去請求網絡,看是否能請求成功,如果請求成功,說明是有效的。當然,這里需要加上超時時間,以避免等待時間過長,這里設置超時時間為5秒。
# 過濾有效的ip信息
def filterValidProxyIp(list):print('開始過濾可用ip 。。。')validList = []for ip in list:if validateIp(ip):print('%s 可用' % ip)validList.append(ip)else:print('%s 無效' % ip)return validList# 驗證ip是否有效
def validateIp(proxy):proxy_temp = {"http": proxy}url = "http://ip.chinaz.com/getip.aspx"try:response = requests.get(url, proxies=proxy_temp, timeout=5)return Trueexcept Exception as e:return False接下來要開始調用以上代碼了。這里只爬取第1頁數據
# 獲取可用的代理ip列表
def getProxyIp():allProxys = []startPage = 0endPage = 1for index in range(startPage, endPage):print('查找第 %s 頁的ip信息' % index)# 請求url,獲取網頁數據content = _requestUrl(index)# 解析網頁數據,獲取ip和端口信息list = parseProxyIpList(content)# 過濾有效的ip信息list = filterValidProxyIp(list)# 添加到有效列表中allProxys.append(list)print('第 %s 頁的有效ip有以下:' % index)print(list)print('總共找到有效ip有以下:')print(allProxys)return allProxys
爬蟲代理ip使用方法。運行該爬蟲程序之后,就可以開始爬取代理服務器信息了。如圖
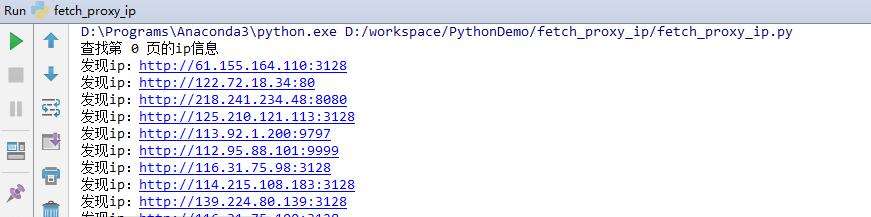
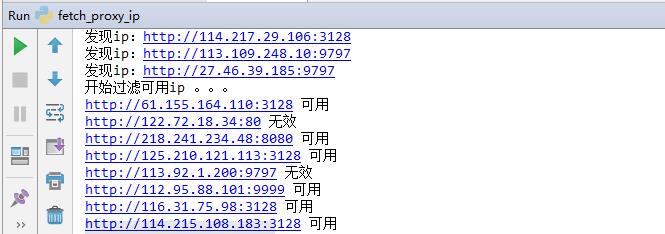
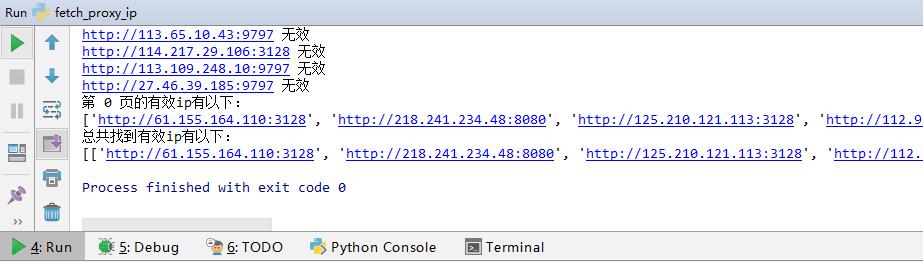
通過以上步驟就可以獲取有效的代理服務器IP信息了,其他代理服務器IP網站的獲取方式和這個大同小異,主要在于解析網頁數據那里,需要找到包含IP和端口數據的標簽,然后解析獲取到。有了代理服務器IP,你就可以爬取更多網站的信息了。
還有個問題是,網站可能會對某個IP檢測,如果超過一定請求次數,就會對其進行屏蔽,那這樣會導致程序中斷,無法獲取所有的信息,這如何解決呢?歡迎關注我的微信公眾號hesong,了解具體應對方式。
附上源碼地址
python web服務器。我的博客
GitHub
我的簡書
群號:194118438,歡迎入群
微信公眾號 hesong ,微信掃一掃下方二維碼即可關注:
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态