近期學習到了loc和iloc的切片用法,發現用法實在是很多,所以用一個簡單的例子進行總結用法,期間也借鑒了大量筆記,如果有錯誤的地方,期待小伙伴們評論區指正。
pandas以類似字典的方式來獲取某一列的值。
數據data.csv分布如下:
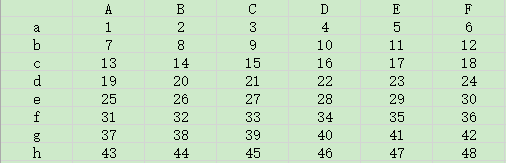
查看數據:
import pandas as pddata = pd.read_csv('./data.csv',index_col=0,encoding='gb2312')
print(data)
print(data.shape)
index = data.index
col = data.columns
print(index)
print(col)python list,結果如下:
A B C D E F
a 1 2 3 4 5 6
b 7 8 9 10 11 12
c 13 14 15 16 17 18
d 19 20 21 22 23 24
e 25 26 27 28 29 30
f 31 32 33 34 35 36
g 37 38 39 40 41 42
h 43 44 45 46 47 48
(8, 6)
Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'], dtype='object')
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')可以看出index為列索引標簽,columns為行索引標簽,此時該矩陣為8*6的一個矩陣。
也就是采用行列標簽來進行索引
為了便于理解,我們將loc和iloc舉的例子一一對應,如果有不懂的小伙伴歡迎評論區互動。
x = data.loc['a':'b','A':'C']
print(x)結果如下:
A B C
a 1 2 3
b 7 8 9x = data.loc['a':'b',:]
print(x)python corr,結果如下:
A B C D E F
a 1 2 3 4 5 6
b 7 8 9 10 11 12x = data.loc[:,'B':'C']
print(x)結果如下:
B C
a 2 3
b 8 9
c 14 15
d 20 21
e 26 27
f 32 33
g 38 39
h 44 45x=data.loc[['b','d'],['A','D']]
print(x)結果如下:
A D
b 7 10
d 19 225.按照條件進行索引,例如獲取A列中數值大于19,同時位于第三列和第五列的數值:
x=data.loc[data['A'] > 19, ['C', 'E']]
print(x)python df.loc?結果如下:
C E
e 27 29
f 33 35
g 39 41
h 45 47x = data.iloc[0:2,0:3]
print(x)結果如下:
A B C
a 1 2 3
b 7 8 9x = data.iloc[0:2,:]
print(x)結果如下:
A B C D E F
a 1 2 3 4 5 6
b 7 8 9 10 11 12x = data.iloc[:,1:3]
print(x)結果如下:
B C
a 2 3
b 8 9
c 14 15
d 20 21
e 26 27
f 32 33
g 38 39
h 44 45x=data.iloc[[1,3],[0,3]]
print(x)python enumerate,結果如下:
A D
b 7 10
d 19 225.按照條件進行索引,例如獲取A列中數值大于19,同時位于第三列和第五列的數值:
x=data.iloc[(data['A'] > 19).values, [2, 4]]
print(x)結果如下:
C E
e 27 29
f 33 35
g 39 41
h 45 47總結: 所以我們可以總結得到loc和iloc的用法,data.loc[想要索引的行標簽,想要索引的列標簽],data.iloc[想要索引的行,想要索引的列]
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态