混淆矩陣也稱誤差矩陣,是表示精度評價的一種標準格式,用n行n列的矩陣形式來表示。在人工智能中,混淆矩陣是可視化工具,特別用于監督學習。
混淆矩陣的每一列代表了預測類別,每一列的總數表示預測為該類別的數據的數目;每一行代表了數據的真實歸屬類別,每一行的數據總數表示該類別的數據實例的數目。
| ? | 預測值 | ||
| Positive | Negative | ||
| 真實值 | Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive?(FP) | True Negative (TN) | |
真陽性(True Positive, TP):樣本的真實類別是正例,并且模型預測的結果也是正例
? ? ? ?真陰性(True Negative, TN):樣本的真實類別是負例,并且模型將其預測成為負例? ? ?
?????? 假陽性(False Positive, FP):樣本的真實類別是負例,但是模型將其預測成為正例
?????? 假陰性(False Negative, FN):樣本的真實類別是正例,但是模型將其預測成為負例
| ? | 公式 | 意義 |
| 準確率ACC |
| 在所有樣本中,預測正確的樣本占的比例 |
| 精確率PPV |
| 在所有預測為正例的樣本中,預測正確為正例所占的比例 |
| 召回率/敏感度/真陽率TPR |
| 在所有實際為正例的樣本中,預測正確為正例所占的比例 |
| 特異度TNR |
| 在所有實際為負例的樣本中,預測正確為負例所占的比例 |
| 流行程度 |
| 在所有樣本中,實際為正例所占的比例 |
| F1-Score |
| F1-Score就是精確率和召回率的調和平均值,F1-Score值認為精確率和召回率一樣重要,其取值范圍從0到1的,1代表模型的輸出最好,0代表模型的輸出結果最差。 |
當分類問題是二分問題是,混淆矩陣可以用上面的方法計算。當分類的結果多于兩種的時候,混淆矩陣同樣適用。
舉例,如有150個樣本數據,預測為1,2,3類各為50個。分類結束后得到的混淆矩陣如下:
| ? | 預測 | |||
| 類1 | 類2 | 類3 | ||
| 實際 ? | 類1 | 43 | 2 | 0 |
| 類2 | 5 | 45 | 1 | |
| 類3 | 2 | 3 | 49 | |
第一行說明有43個屬于第一類的樣本被正確預測為了第一類,有2個屬于第一類的樣本被錯誤預測為了第二類。第一列說明有43個屬于第一類的樣本被正確預測為了第一類,有5個屬于第二類的樣本、2個屬于第三類的樣本被錯誤預測為了第一類。
![]()
以類1為例,計算其他指標
![]()
![]()

![]()
?
如果感覺不錯,那就給我點個贊吧(^_?)☆
?
?
?
?
利用混淆矩陣計算評價指標正確的是??
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态

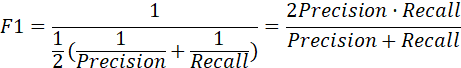






![前端工程化系列[01]-Bower包管理工具的使用](/upload/rand_pic/2-030.jpg)

