學習過程:
內核引導及過程:
CPU通電后,首先執行引導程序,引導程序把內核加載到**內存,**然后執行內核,內核初始化完成后,啟動用戶空間的進程。CPU通電后,自動把程序計數器設置為CPU廠商設計的某個固定值。嵌入式設備通常用NOR閃存作為只讀存儲器存放引導程序。
嵌入式設備通常使用U-Boot作為引導程序。
ENTRY(_main)–>U->boot程序初始化完成之后,準備處理命令是通過數組init_sequence_r,最后一個函數run_main_loop()實現。
引導處理器啟動從處理器方法3種:
a. 自旋表
b. 電源狀態協調接口
c. ACPI停車協議
用戶空間和內核空間: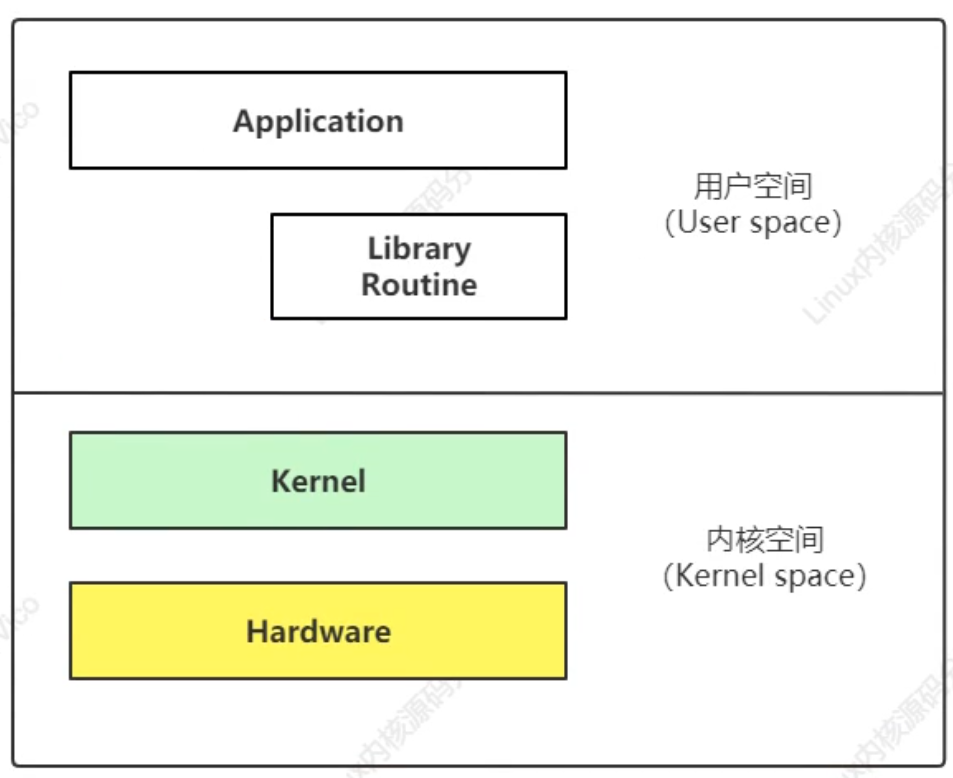
系統調用: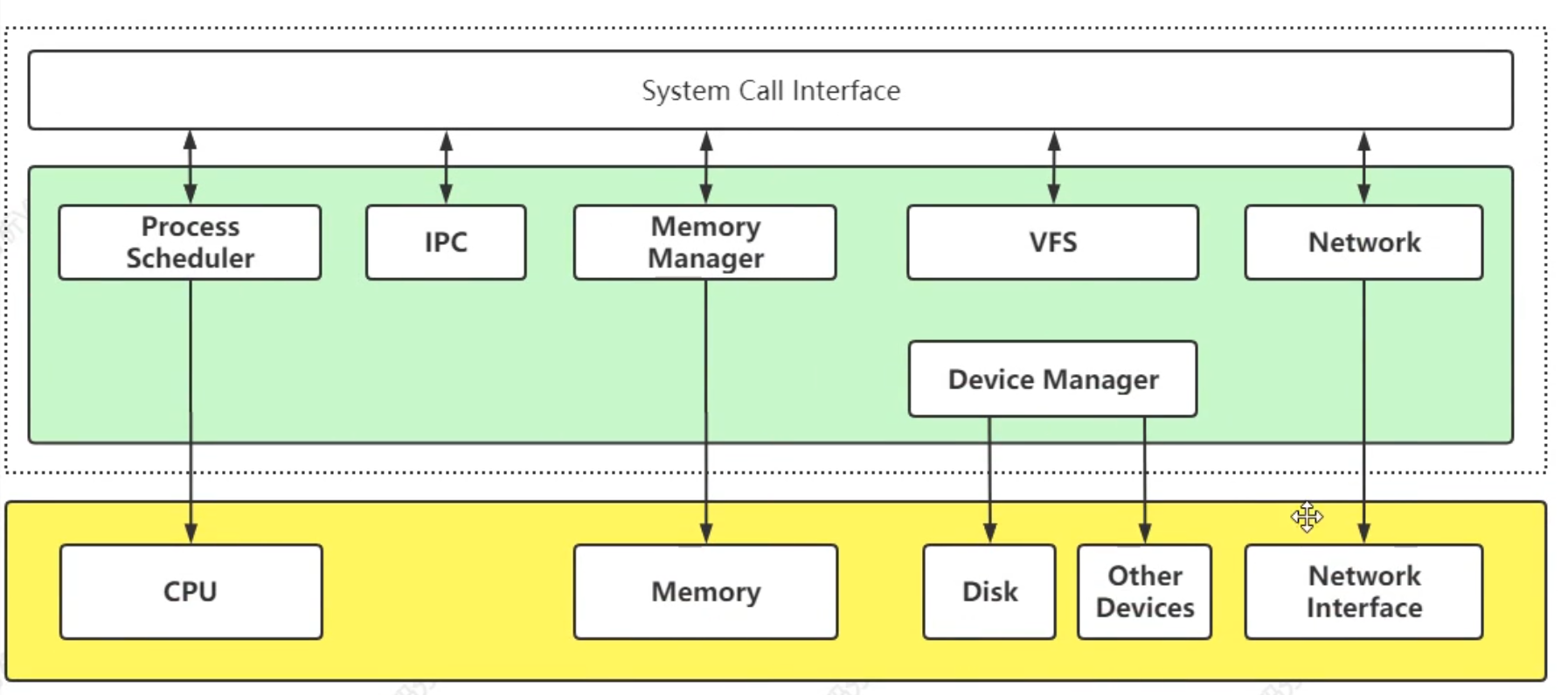
進程:
內存: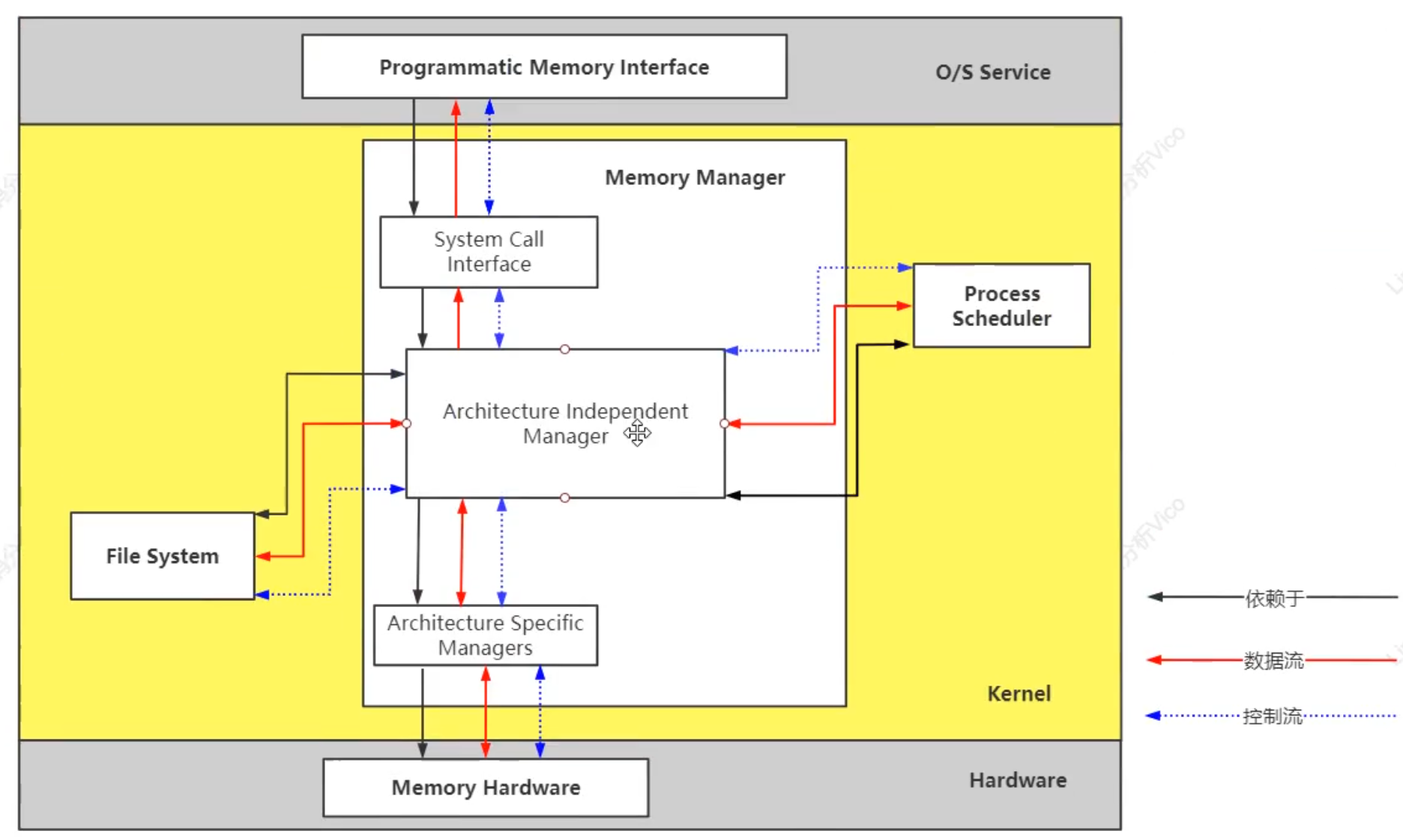
文件系統: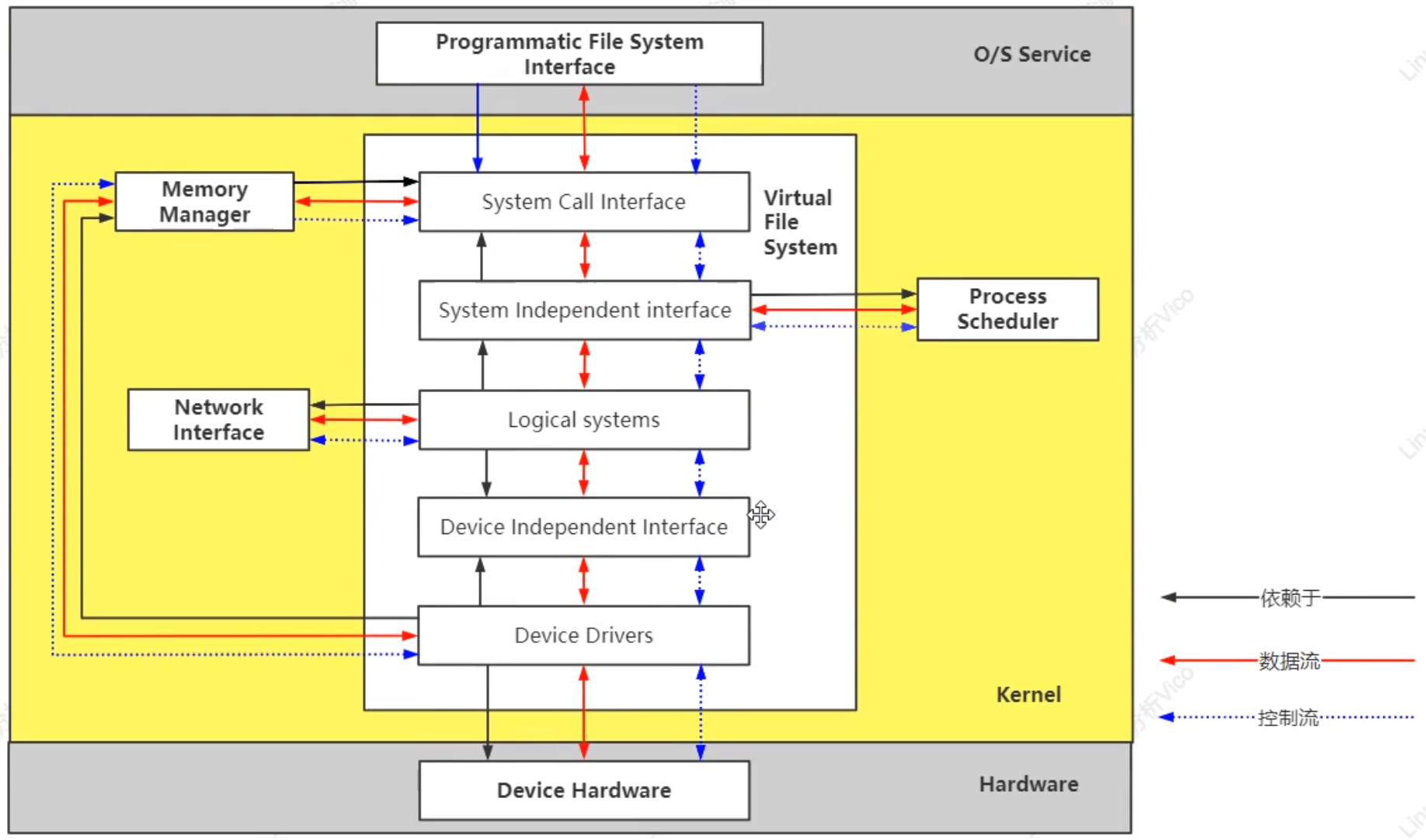
網絡: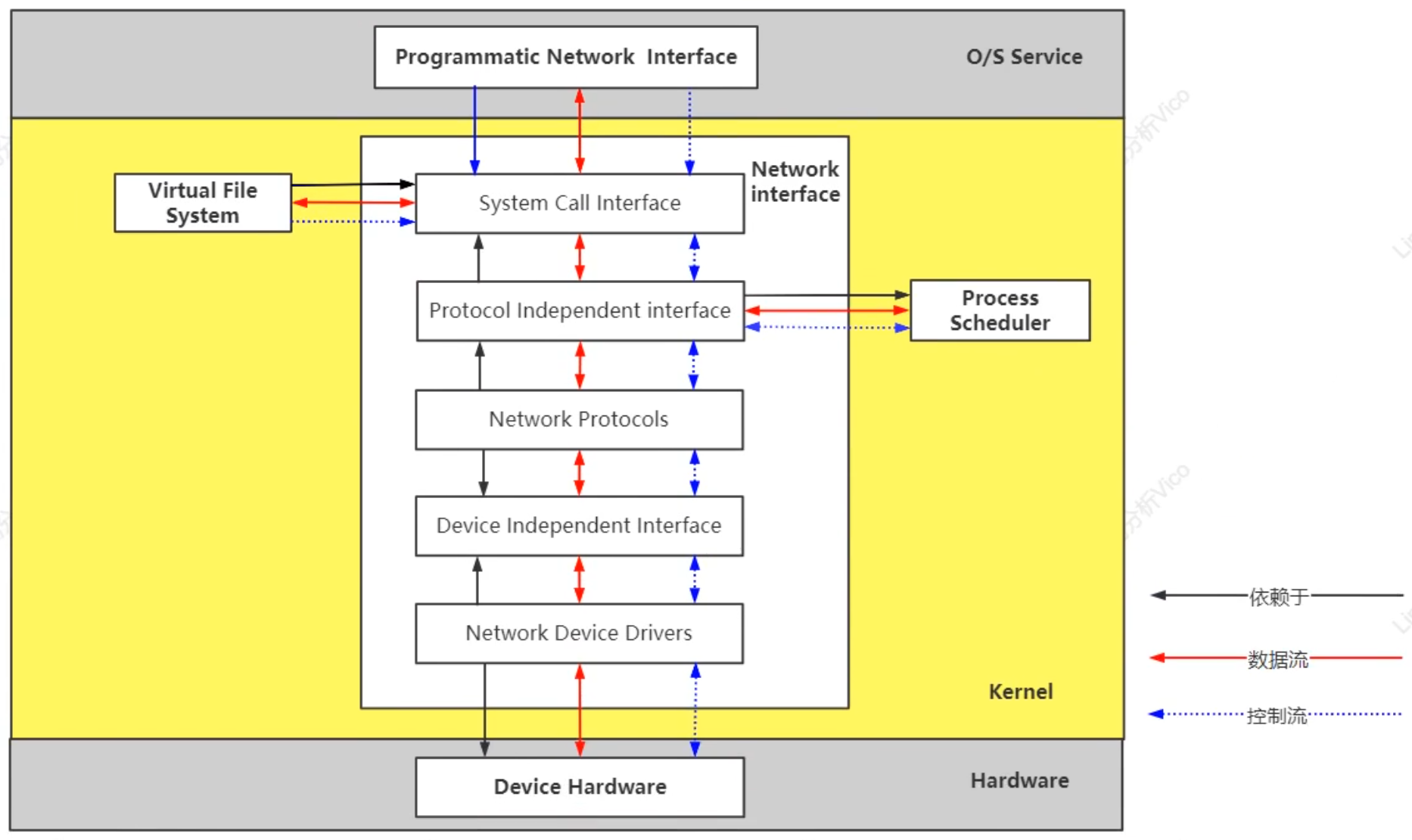
kernel內核,linux版本分為兩類:
1.1)內核版本命名:
Linux內核版本號由3組數字組成:第一個組數字.第二組數字.第三組數字
可以使用uname -r 查看內核版本號,例如:2.6.32-754.2.1.el6.x86_64
除了前面的版本號外,最后的有多種,例如:2.6.32-358.6.1.el6.i686、2.6.18-128.ELsmp、2.6.32-642.el6.x86_64
1.2)內核版本歷史:
linux內核大致分為以下幾個階段:
截止到2021年,很多線上系統仍然使用2.6.x的內核。Linux2.6版本內核發布,與2.4內核版本相比,它在很多方面進行了改進,如支持多處理器配置和64位計算,它還支持實現高效率線和處理的本機POSIX 線程庫(NPTL)。實際上,性能、安全性和驅動程序的改進是整個2.6.x 內核的關鍵。
https://en.wikipedia.org/wiki/Linux_kernel_version_history#Releases_before_2.6.0
UNIX/LINUX,人們以Linux核心為中心,再集成搭配各種各樣的系統管理軟件或應用工具軟件組成一套完整的操作系統,如此的組合便稱為Linux發行版。
Linux的發行版本可以大體分為兩類:
1)Redhat(小紅帽),應該稱為Redhat系列,包括RHEL(Redhat Enterprise Linux,也就是所謂的Redhat Advance Server,收費版本)、Fedora Core(由原來的Redhat桌面版本發展而來,免費版本)、CentOS(RHEL的社區克隆版本,免費)。Redhat應該說是在國內使用人群最多 的Linux版本,甚至有人將Redhat等同于Linux,而有些老鳥更是只用這一個版本的Linux。所以這個版本的特點就是使用人群數量大,資料非常多,言下之意就是如果你有什么不明白的地方,很容易找到人來問,而且網上的一般Linux教程都是以Redhat為例來講解的。Redhat系列的包管理方式采用的是基于RPM包的YUM包管理方式,包分發方式是編譯好的二進制文件。穩定性方面RHEL和CentOS的穩定性非常好,適合于服務器使用, 但是Fedora Core的穩定性較差,最好只用于桌面應用。
2)Debian,或者稱Debian系列,包括Debian和Ubuntu等。Debian是社區類Linux的典范,是迄今為止最遵循GNU規范 的Linux系統。Debian最早由Ian Murdock于1993年創建,分為三個版本分支(branch): stable, testing 和 unstable。其中,unstable為最新的測試版本,其中包括最新的軟件包,但是也有相對較多的bug,適合桌面用戶。testing的版本都經 過unstable中的測試,相對較為穩定,也支持了不少新技術(比如SMP等)。而stable一般只用于服務器,上面的軟件包大部分都比較過時,但是 穩定和安全性都非常的高。Debian最具特色的是apt-get / dpkg包管理方式,其實Redhat的YUM也是在模仿Debian的APT方式,但在二進制文件發行方式中,APT應該是最好的了。Debian的資 料也很豐富,有很多支持的社區,有問題求教也有地方可去:)
3)Ubuntu嚴格來說不能算一個獨立的發行版本,Ubuntu是基于Debian的unstable版本加強而來,可以這么說,Ubuntu就是 一個擁有Debian所有的優點,以及自己所加強的優點的近乎完美的 Linux桌面系統。根據選擇的桌面系統不同,有三個版本可供選擇,基于Gnome的Ubuntu,基于KDE的Kubuntu以及基于Xfc的 Xubuntu。特點是界面非常友好,容易上手,對硬件的支持非常全面,是最適合做桌面系統的Linux發行版本。
POSIX:可移植操作系統接口(英語:Portable Operating System Interface,縮寫為POSIX),是IEEE為要在各種UNIX操作系統上運行的軟件,而定義API的一系列互相關聯的標準的總稱,其正式稱呼為IEEE 1003,而國際標準名稱為ISO/IEC 9945。它基本上是Portable Operating System Interface(可移植操作系統接口)的縮寫,而X則表明其對Unix API的傳承。
此標準源于一個大約開始于1985年的項目,POSIX這個名稱是由理查德?斯托曼應IEEE的要求而提議的一個易于記憶的名稱。
這個標準并不是一個強制性或者大家都在使用的標準:
linux和posix的關系:
linux一些函數的功能與posix標準的一些函數(接口)功能相同,只是簽名不同,你可以認為只是改了個名字。如果你使用posix標準的函數,那么你為其它可以使用posix標準的系統寫代碼,就不用重新修改原來的函數簽名,而只需要重新編譯(因為實現的代碼是不同的)一遍就行了。
UNIX操作系統最初是由貝爾實驗室開發的,當時的貝爾實驗室是電信業巨頭AT&T(美國電報電話公司)旗下的一員。在20世紀70年代,unix成為一種非常流行的多用戶、多任務操作系統。Unix 系統被發明之后,大家用的很爽,但是后來開始收費和商業閉源了。。。
理查德 · 斯托曼 在 1983年發起GNU計劃,其目標是建立完全自由的操作系統GNU,取代Unix。在1985年創建自由軟件基金會(FSF),在1989年發布GPL許可協議保護和傳播由FSF發布的自由軟件。自由軟件是權利問題,不是價格問題。要理解這個概念,你應該考慮“free”是“言論自由(free speech)”中的“自由”;而不是“免費啤酒(free beer)”中的“免費”。
GNU(“GNU’s Not Unix”的遞歸首字母縮寫詞)是一個類Unix操作系統,它是由多個應用程序、系統庫、開發工具乃至游戲構成的程序集合。GNU的開發始于1984年1月,稱為GNU工程,GNU的許多程序在GNU工程下發布,我們稱之為GNU軟件包。主要由:
許多其他的軟件包也是在遵守自由軟件的原則和GPL條款的情況下開發和發行的,包括電子表格、源代碼控制工具、編譯器和解釋器、因特網工具、圖形圖像處理工具(如Gimp),以及兩個完整的基于對象的環境(GNOME和KDE)。有了這么多可用的自由軟件,再加上Linux內核,我們可以說:創建一個GNU的、自由的類UNIX系統的目標已經實現了。(GNU早起也有自己的內核,后面選用了Linux)
眾所周知,一個完整的通用操作系統至少需要內核、編譯套件、shell以及主要應用軟件。GUN最初的內核組件Hurd開發于1990年(早于linux),但設計過于復雜進展緩慢。正巧,1991年10月林納斯·托瓦茲(Linus Torvalds)發布了他的玩具內核源代碼,這是他在學習Minix操作系統源碼的過程中耗時六個月,用C寫出來的POSIX不完整兼容的內核,并將GNU的基礎軟件Gcc和Bash成功的移植到了上面,這之后大量用戶參與開發,并在1994年使用GPL協議發布了Linux 1.0內核。
從此,GNU計劃和Linux天衣無縫的、互相彌補的就結合在了一起,成為了完全自由并且完整的操作系統——GNU/Linux。RedHat等以GNU/Linux作為產業的大廠隨即出現,大力發展了GNU/Linux,使其變得越來越實用,逐漸取代了Unix操作系統的位置。
centos7各版本內核?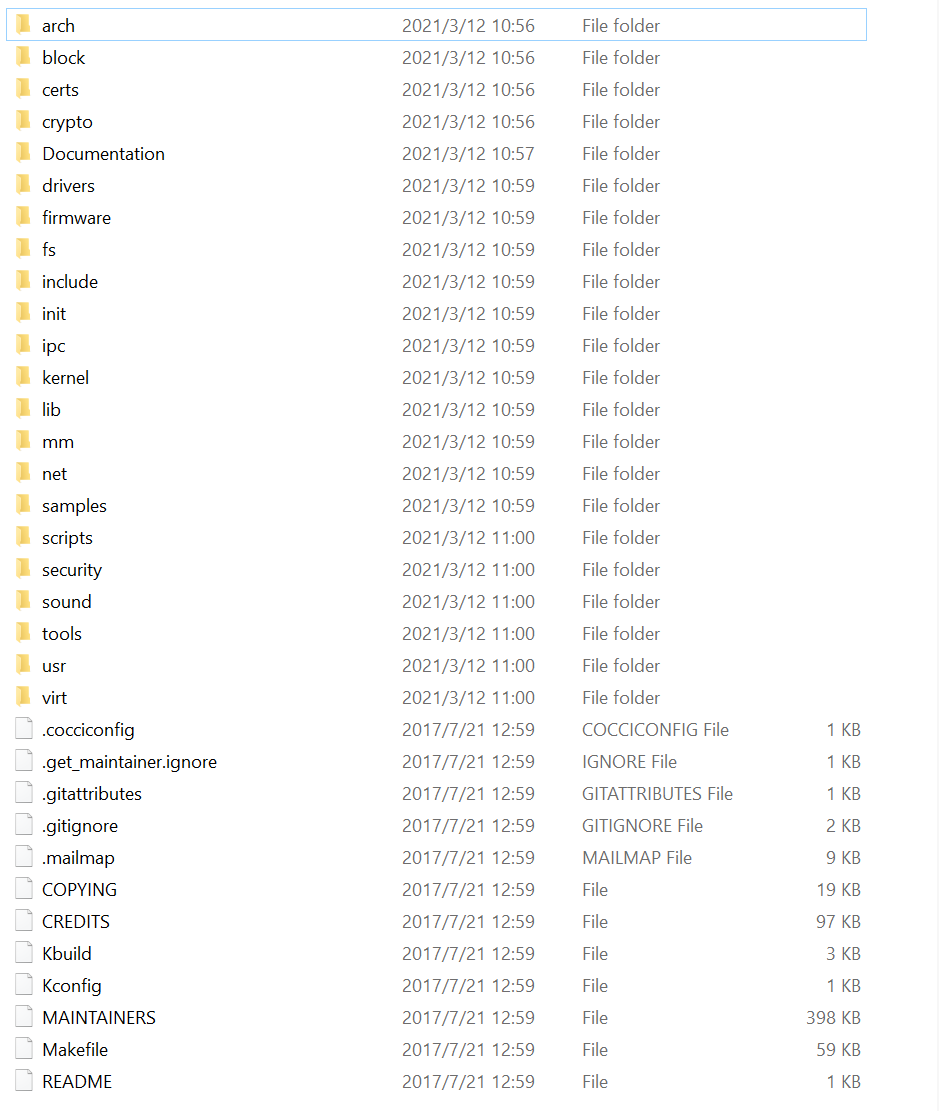
| 目錄 | 開發關注度 | 描述 | 存放功能 |
|---|---|---|---|
| arch | 5? | 即architecture,意為架構的意思, 常見的一些架構有mips、x86、arm。 適配一款芯片的linux內核,首先需要知道芯片屬于什么架構 | dts、內存管理,系統調用,動態調頻,主頻率設置、庫文件等 |
| block | 4? | block,意為塊,與塊設備相關的功能,如SD卡、iNand、Nand、硬盤等塊設備相關的操作 | 塊設備相關代碼 |
| certs | 即certificates,意為簽名認證,與簽名認證相關功能 | 認證簽名相關代碼 | |
| crypto | 4? | 可以記為encryption,與壓縮加密相關的功能,如md5、sha1、 hash等 | 各類加密算法相關的功能代碼 |
| Documentation | 5? | linux內核各類機制相關的文檔,全英文,可以查閱各類機制的實現說明 | 官方文檔 |
| drivers | 5? | 即驅動,linux的驅動代碼, 如GPIO、網絡、usb、藍牙等驅動源碼,一般做開發都需要修改或添加該目錄下的文件 | 驅動源碼相關 |
| frimware | 3? | 存放一些固件代碼(.bin) | |
| fs | 4? | 即files system, linux的文件系統, 如ext2-4、jffs2、nfs、squashfs、ramfs、romfs等文件系統的實現代碼 | 文件系統相關源碼 |
| include | 5? | linux庫文件的頭文件,如fs.h、mdio.h、mm.h等, include/linux存放與平臺無關的功能的頭文件 | linux內核功能相關的頭文件 |
| init | 5? | 即initialization ,初始化相關源碼,main.c也在其中 | linux初始化相關 |
| ipc | 4? | 即Inter-Process Communication,進程間通信, 如共享內存、信號量、消息隊列等 | 進程間通信相關代碼 |
| kernel | 5? | 即內核,linux內核相關的功能實現源碼,如panic、pid、module、irq、cpu相關 | 內核功能源碼 |
| lib | 4? | 即library, 實現一些庫功能,如decompress、crc32、atomic等 | 庫功能實現源碼 |
| mm | 5? | 即memory management,內存管理相關功能實現 ,mmap、page、mempool等 | 內存管理相關源碼 |
| net | 5? | network, 網絡功能相關的源碼,如tcp/ip、dns、ipv4/v6、802.11、ethernet等 | 網絡協議功能 |
| samples | 3? | 一些linux功能代碼使用的標準實例 示例參考代碼 | |
| scripts | 3? | 與內核無關的腳本代碼,如內核編譯相關、menuconfig相關 | 內核無關的腳本 |
| security | 2? | SELinux的模塊。安全相關 | 安全相關代碼,具體未知 |
| sound | 3? | 聲卡與聲音驅動相關代碼,包含i2c、spi、usb等接口 | 音頻功能實現代碼 |
| tools | 3? | 與c編譯、鏈接生成一個完整內核鏡像相關的工具 | 編譯相關 |
| usr | 3? | 用戶打包和壓縮內核實現代碼 | |
| virt | 3? | 虛擬化相關的代碼,允許搭建虛擬機環境,運行多個系統 | 虛擬化相關代碼實現 |
| 文件 | 描述 |
|---|---|
| COPYING | 許可授權信息 |
| CREDITS | 貢獻者相關信息列表 |
| Kbuild | 內核設定的腳本 |
| Kconfig | 內核開發人員配置內核用到的配置 |
| makefile | 編譯內核的makefile文件 |
| MAINTAINERS | 維護內核者的相關信息 |
Linux內核把進程稱為任務(task),進程的虛擬地址空間分為用戶虛擬地址空間和內核虛擬地址空間,所有進程共享內核虛擬地址空間,每個進程有獨立的用戶空間虛擬地址空間。
進程有兩種特殊形式:沒有用戶虛擬地址空間的進程稱為內核線程,共享用戶虛擬地址空間的進程稱為用戶線程。通用在不會引起混淆的情況下把用戶線程簡稱為線程。共享同一個用戶虛擬地址空間的所有用戶線程組成一個線程組。
C標準庫的進程專業術語和Linux內核的進程專業術語對應關系如下:
| C標準庫的進程專業術語 | Linux內核的進程專業術語 |
|---|---|
| 包含多個線程的進程 | 線程組 |
| 只有一個線程的進程 | 進程或任務 |
| 線程 | 共享用戶虛擬地址空間的進程 |
如果只具備前三條而缺少第四條,則稱為“線程”。如果完全沒有用戶空間,就稱為“內核線程”;而如果共享用戶空間映射就稱為“用戶線程”。內核為每個進程分配一個task_struct結構時。實際分配兩個連續物理頁面(8192字節),數據結構task_struct的大小約占1kb字節左右,進程的系統空間堆棧的大小約為7kb字節(不能擴展,是靜態確定的)。
struct task_struct {...volatile long state; //進程的狀態void *stack; //指向內核棧...pid_t pid; //全局進程號pid_t tgid; //全局線程組的標識符...struct pid_link pids[PIDTYPE_MAX]; //進程號,進程組標識符和會話標識符...struct task_struct __rcu *real_parent; //指向真實父進程struct task_struct __rcu *parent; //指向父進程,如果進程被另一個進程使用系統調用ptrace,那么父進程跟蹤進程,否則和real_parent相同...struct task_struct *group_leader; //指向線程組的組長...char comm[TASK_COMM_LEN]; //進程名稱...// 調度策略和優先級int prio;int static_prio;int normal_prio;unsigned int rt_priority;...cpumask_t cpus_allowed; //允許進程在哪些處理器上運行...// 指向內存描述符// 進程:mm和active_mm指向同一個內存描述符// 內核線程:mm是空指針,當內核線程運行時,active_mm指向從進程借用的內存描述符struct mm_struct *mm; struct mm_struct *active_mm; .../* Filesystem information: */struct fs_struct *fs; //文件系統信息,主要是進程的根目錄和當前工作目錄/* Open file information: */struct files_struct *files; //打開文件表/* Namespaces: */struct nsproxy *nsproxy; //命名空間...//信號處理/* Signal handlers: */struct signal_struct *signal;struct sighand_struct *sighand;sigset_t blocked;sigset_t real_blocked;/* Restored if set_restore_sigmask() was used: */sigset_t saved_sigmask;struct sigpending pending;...
}
在Linux內核中,新進程是從一個已經存在的進程復制出來的,內核使用靜態數據結構造出0號內核線程,0號內核線程分叉生成1號內核線程和2號內核線程(kthreadd線程)。1號內核線程完成初始化以后裝載用戶程序,變成1號進程,其他進程都是1號進程或者它的子孫進程分叉生成的;其他內核線程是kthreadd線程分叉生成的。
3個系統調用可以用來創建新的進程:
Linux內核定義系統調用的獨特方式,目前以系統調用fork為例: 系統調用的函數名稱以"sys_"開頭,創建新進程的3個系統調用在文件"kernel/fork.c"中,它們把工作委托給函數__do_fork。
long _do_fork(unsigned long clone_flags, //克隆標志unsigned long stack_start, //只有我們在創建線程時有意義,用來指定線程的用戶棧起始地址unsigned long stack_size, //只有我們在創建線程時有意義,用來指定線程的用戶棧的長度int __user *parent_tidptr, //只有我們在創建線程時有意義,如果clone_flags參數指定標志位CLONE_PARENT_SETIDint __user *child_tidptr, //只有我們在創建線程時有意義,存放新線程保存自己的進程標識符的位置,如果參數clone_flags指定標識符CLONE_CHILD_CLEARTID/CLONE_CHILD_SETIDunsigned long tls //只有我們在創建線程時有意義,如果clone_flags參數指定標志位CLONE_SETTLS,那么參數tls指定新線程的線程本地存儲的地址)
{...//相關性驗證...p = copy_process(clone_flags, stack_start, stack_size,child_tidptr, NULL, trace, tls, NUMA_NO_NODE);...
}
Linux內核函數_do_fork()執行流程如下圖所示: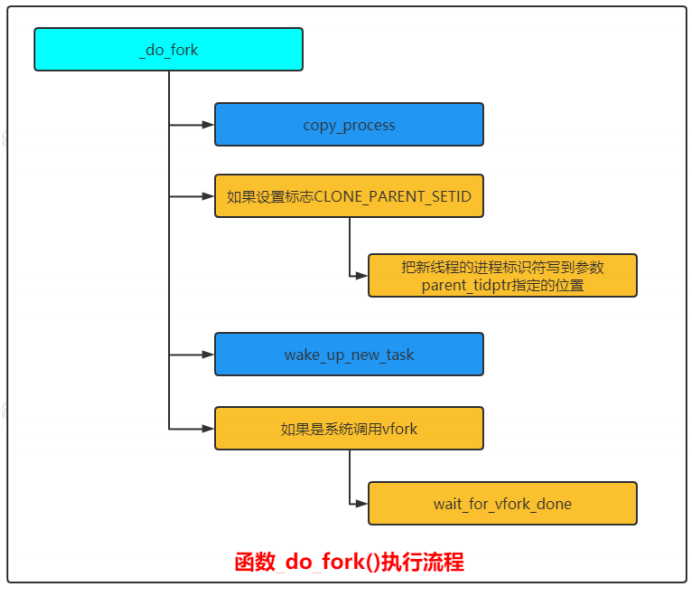
函數copy_process()內核源碼如下:
static __latent_entropy struct task_struct *copy_process(unsigned long clone_flags,unsigned long stack_start,unsigned long stack_size,int __user *child_tidptr,struct pid *pid,int trace,unsigned long tls,int node)
{.../// 狀態檢查 ///// 同時設置 CLONE_NEWNS/CLONE_FS, 即新進程屬于新的掛載命名空間,同時和當前進程共享文件系統信息if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))return ERR_PTR(-EINVAL);// 同時設置 CLONE_NEWUSER/CLONE_FS, 即新進程屬于新的用戶命名空間,同時和當前進程共享文件系統信息if ((clone_flags & (CLONE_NEWUSER|CLONE_FS)) == (CLONE_NEWUSER|CLONE_FS))return ERR_PTR(-EINVAL);// 即新進程和當前進程屬于同一個線程組, 但是不共享信號處理程序if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))return ERR_PTR(-EINVAL);// 即新進程和當前進程共享信號處理程序, 但是不共享虛擬內存if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))return ERR_PTR(-EINVAL);.../// dup_task_struct /////同一個線程組的所有線程必須屬于相同的用戶命名空間和進程號命名空間p = dup_task_struct(current, node);.../// 檢查用戶創建的進程數量是否超過限制 ///if (atomic_read(&p->real_cred->user->processes) >=task_rlimit(p, RLIMIT_NPROC)) {if (p->real_cred->user != INIT_USER &&!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))goto bad_fork_free;}.../// cpoy_creds /////設置權限retval = copy_creds(p, clone_flags);.../// 檢查線程數量是否超過限制 ///if (nr_threads >= max_threads)goto bad_fork_cleanup_count; .../// 初始化task_struct ///delayacct_tsk_init(p); /* Must remain after dup_task_struct() */.../// sched_fork /////kernel/sched/core.cvoid __sched_fork(unsigned long clone_flags, struct task_struct *p) //為新進程設置調度器相關的參數 .../// 設置或共享資源 ///...retval = copy_semundo(clone_flags, p); //只有屬于同一個線程組的線程之間才會共享UNIX系統5個信號量if (retval)goto bad_fork_cleanup_security;retval = copy_files(clone_flags, p); //打開文件表,只有屬于同一個線程組的線程之間才會共享打開文件表if (retval)goto bad_fork_cleanup_semundo;retval = copy_fs(clone_flags, p); //文件系統信息,進程的文件系統信息包括:根目錄,當前工作目錄,文件模式創建掩碼,只有屬于同一個線程組的線程之間才會共享文件系統信息if (retval)goto bad_fork_cleanup_files;retval = copy_sighand(clone_flags, p); // 信號處理, 只有屬于同一個線程組的線程之間才會共享信號處理程序if (retval)goto bad_fork_cleanup_fs;retval = copy_signal(clone_flags, p); //信號結構體, 只有屬于同一個線程組的線程之間才會共享信號結構體if (retval)goto bad_fork_cleanup_sighand;retval = copy_mm(clone_flags, p); //虛擬內存, 只有屬于同一個線程組的線程之間才會共享虛擬內存if (retval)goto bad_fork_cleanup_signal;retval = copy_namespaces(clone_flags, p); //創建或共享命名空間if (retval)goto bad_fork_cleanup_mm;retval = copy_io(clone_flags, p); //創建或共享IO上下文if (retval)goto bad_fork_cleanup_namespaces;retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls); //復制寄存器值并且修改一部分寄存器值,不同處理器架構的寄存器不同,所以各種處理器架構需要自己定義結構體pt_regs和thread_struct,實現函數copy_thread_tlsif (retval)goto bad_fork_cleanup_io;/// 設置進程號和進程關系等等 ///if (pid != &init_struct_pid) {pid = alloc_pid(p->nsproxy->pid_ns_for_children);if (IS_ERR(pid)) {retval = PTR_ERR(pid);goto bad_fork_cleanup_thread;}}...
}
ubuntu內核。函數copy_process():創建新進程的主要工作由此函數完成,具體處理流程如下圖所示: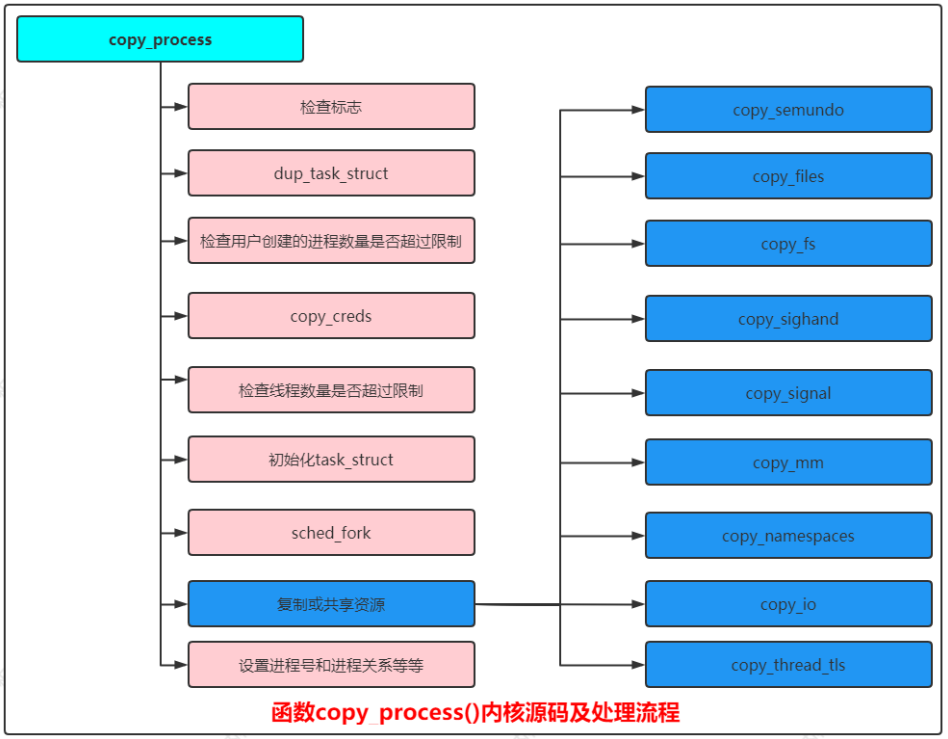
進程主要有7種狀態:就緒狀態、運行狀態、輕度睡眠、中度睡眠、深度睡 眠、僵尸狀態、死亡狀態,它們之間狀態變遷如下:

struct task_struct {...volatile long state; //進程的狀態...
}/* Used in tsk->state: */
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* Used in tsk->exit_state: */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_NEW 2048
#define TASK_STATE_MAX 4096
#define TASK_STATE_TO_CHAR_STR "RSDTtXZxKWPNn"/* Convenience macros for the sake of set_current_state: */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)#define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD)/* Convenience macros for the sake of wake_up(): */
#define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)
#define TASK_ALL (TASK_NORMAL | __TASK_STOPPED | __TASK_TRACED)/* get_task_state(): */
#define TASK_REPORT (TASK_RUNNING | TASK_INTERRUPTIBLE | \TASK_UNINTERRUPTIBLE | __TASK_STOPPED | \__TASK_TRACED | EXIT_ZOMBIE | EXIT_DEAD)#define task_is_traced(task) ((task->state & __TASK_TRACED) != 0)#define task_is_stopped(task) ((task->state & __TASK_STOPPED) != 0)#define task_is_stopped_or_traced(task) ((task->state & (__TASK_STOPPED | __TASK_TRACED)) != 0)#define task_contributes_to_load(task) ((task->state & TASK_UNINTERRUPTIBLE) != 0 && \(task->flags & PF_FROZEN) == 0 && \(task->state & TASK_NOLOAD) == 0)
先進先出調度(SCHED_FIFO):沒有時間片,如果沒有更高優先級的實時進程,并且它不睡眠,那么它會一直占用處理器。
輪流調度(SCHED_RR):有時間片,進程用完時間片以后加入優先級對應運行隊列的尾部,把處理器給優先級相同的其他實時進程。
標準輪流分時策略調度(SCHED_NORMAL):使用完全公平調度算法,把處理器時間公平分配給每個進程。
空閑策略調度(SCHED_IDLE):用來執行優先級非常低的后臺作業,優先級比使用標準輪流分時策略(SCHED_NORMAL)和相對優先級為19的普通進程(SCHED_BATCH)還要低,進程的相對優先級空閑調度策略沒有影響。
限期進程的優先級比實時進程高,實時進程的優先級比普通進程高。
在task_struct結構體中,4個成員和優先級有關如下: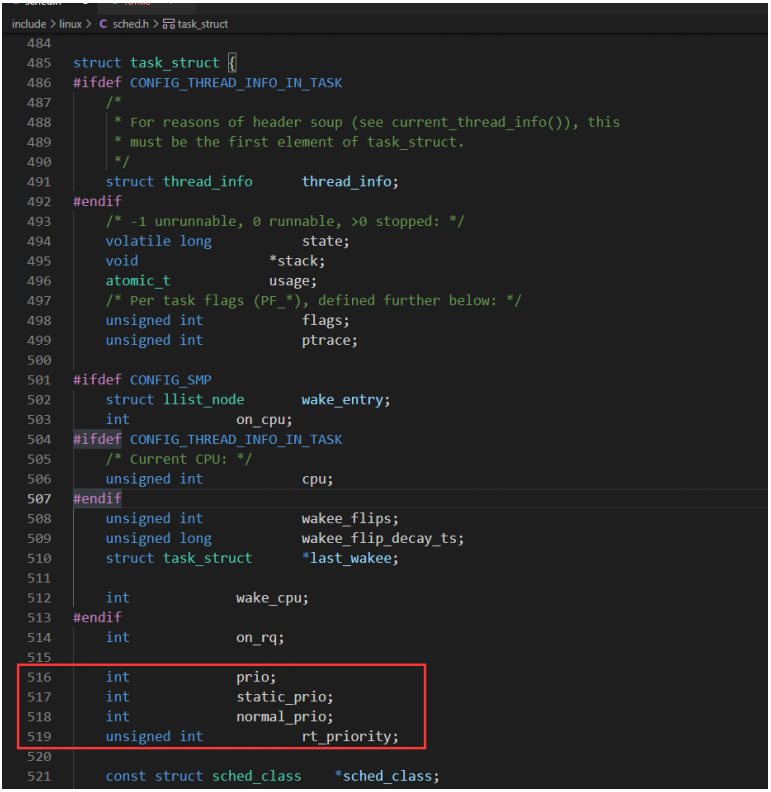
| 優先級 | 限期進程 | 實時進程 | 普通進程 |
|---|---|---|---|
| prio調度優先級(數值越小,表示優先級越高) | 大多數情況下prio等于normal_prio 特殊情況:如果進程a占有實時互斥鎖,進程b正在等待鎖,進程b的優先級比較進程a的優先級高,那么把進程a的優先級臨時提高到進程b的優先級,即進程a的prio值等于進程b的prio值 | ||
| static_prio靜態優先級 | 沒意義,為0 | 沒意義,為0 | 120+nice值,數值越小,表示優先級越高 |
| normal_prio正常優先級(數值越小,表示優先級越高) | -1 | 99-rt_priority | static_prio |
| rt_priority實時優先級 | 沒意義,為0 | 實時進程的優先級,范圍是1-99,數值越大,表示優先級越高 | 沒意義,為0 |
如果優先級低的進程占有實時互斥鎖,優先級高的進程等待實時互斥鎖,將把占有實時互斥鎖的進程的優先級臨時提高到等待實時互斥鎖的進程的優先級,稱為優先級繼承。
內核線程?寫時復制核心思想:只有在不得不復制數據內容時才去復制數據內容。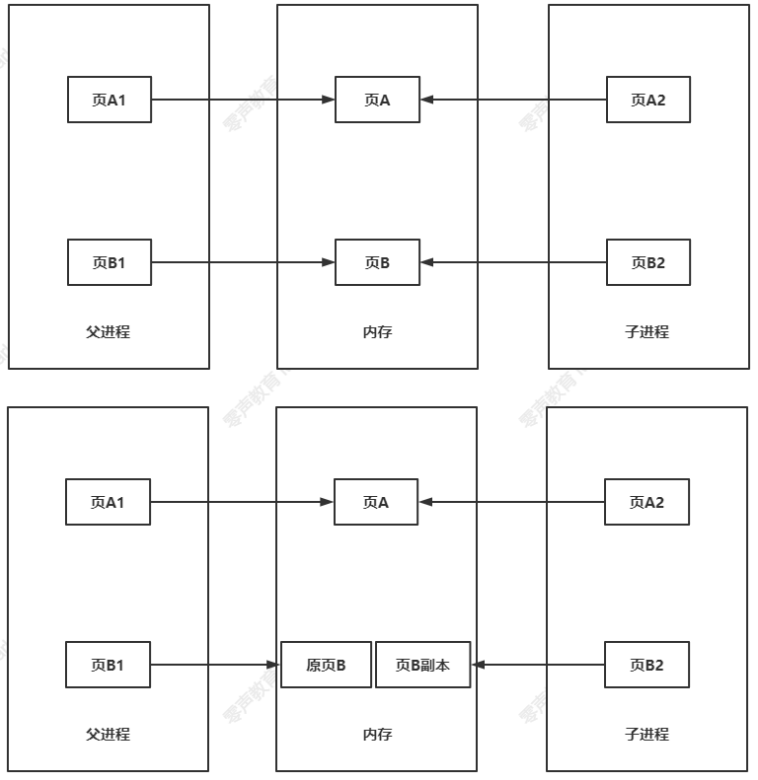
調度器的實現基于兩個函數:周期性調度器函數和主調度器函數。這些函數根據現有進程的優先級分配CPU時間。這也是為什么整個方法稱之為優先調度的原因。
在內核中的許多地方,如果要將CPU分配給與當前活動進程不同的另一個進程,都會直接調用主調度器函數 (schedule)。
asmlinkage __visible void __sched schedule(void)
{struct task_struct *tsk = current;sched_submit_work(tsk);do {preempt_disable();__schedule(false);sched_preempt_enable_no_resched();} while (need_resched());
}
EXPORT_SYMBOL(schedule);
主調度器負責將CPU的使用權從一個進程切換到另一個進程。周期性調度器只是定時更新調度相關的統計信息。 cfs隊列實際上是用紅黑樹組織的,rt隊列是用鏈表組織的。
周期性調度器在scheduler_tick中實現,如果系統正在活動中,內核會按照頻率HZ自動調用該函數。該函數主要有兩個任務如下:
(1) 更新相關統計量:管理內核中與整個系統和各個進程的調度相關的統計量。其間執行的主要操作是對各
種計數器加1。
(2) 激活負責當前進程的調度類的周期性調度方法。
void scheduler_tick(void)
{// 獲取當前CPU上的全局就緒隊列rq和當前運行的進程curr// 在SMP的情況下, 獲得當前CPU的ID, 如果不是SMP, 那么返回0int cpu = smp_processor_id();// 獲得CPU的全局就緒隊列rq, 每個CPU都有一個就緒隊列rqstruct rq *rq = cpu_rq(cpu);// 獲取就緒隊列上正在運行的進程currstruct task_struct *curr = rq->curr;struct rq_flags rf;sched_clock_tick();rq_lock(rq, &rf);// 更新rq當前時間戳, 即使rq->clock變為當前時間戳// 處理就緒隊列時鐘的更新, 本質上就是增加struct rq當前實例的時鐘時間戳update_rq_clock(rq);// 由于調度器的模塊化結構, 主要工作可以完全由特定調度器類方法實現。task_tick實現模式取決底層的調度器類// 執行當前運行進程所在調度類的task_tick函數進行周期性調度curr->sched_class->task_tick(rq, curr, 0);// 將當前負荷加入數組的第一個位置cpu_load_update_active(rq);// 更新全局CPU就緒隊列的calc_global_update, 更新CPU的活動計數, 主要是更新全局CPU就緒隊列calc_global_updatecalc_global_load_tick(rq);// 解鎖rq_unlock(rq, &rf);// 與perf計數事件有關perf_event_task_tick();#ifdef CONFIG_SMP// 判斷CPU是否為空閑狀態rq->idle_balance = idle_cpu(cpu);// 如果進程周期性負載平衡, 則觸發SCHED_SOFTIRQtrigger_load_balance(rq);
#endifrq_last_tick_reset(rq);
}
更新統計量函數:update_rq_clock()/calc_global_load_tick()
<update_rq_clock函數>
// 處理就緒隊列時鐘的更新, 本質上就是增加struct rq當前實例的時鐘時間戳
void update_rq_clock(struct rq *rq)
{s64 delta;lockdep_assert_held(&rq->lock);if (rq->clock_update_flags & RQCF_ACT_SKIP)return;#ifdef CONFIG_SCHED_DEBUGif (sched_feat(WARN_DOUBLE_CLOCK))SCHED_WARN_ON(rq->clock_update_flags & RQCF_UPDATED);rq->clock_update_flags |= RQCF_UPDATED;
#endifdelta = sched_clock_cpu(cpu_of(rq)) - rq->clock;if (delta < 0)return;rq->clock += delta;update_rq_clock_task(rq, delta);
}
linux內核能做什么?<calc_global_load_tick函數>
// 更新全局CPU就緒隊列的calc_global_update, 更新CPU的活動計數, 主要是更新全局CPU就緒隊列calc_global_update
void calc_global_load_tick(struct rq *this_rq)
{long delta;if (time_before(jiffies, this_rq->calc_load_update))return;delta = calc_load_fold_active(this_rq, 0);if (delta)atomic_long_add(delta, &calc_load_tasks);this_rq->calc_load_update += LOAD_FREQ;
}
為方便添加新的調度策略,Linux內核抽象一個調度類sched_class,目前為止實現5種調度類:
停機調度類(stop_sched_class):支持期限調度類,遷移線程的優先級必須比期限進程的優先級高,能夠搶占所有其他進程,才能夠快速處理調度器發出的遷移移求,把進程從當前處理器遷移到其他處理器。
期限調度類(dl_sched_class):使用優先算法(使用紅黑樹)把進程按照絕對截至期限從小到大排序,每次調度時選擇絕對截至期限最小的進程。
實時調度類(rt_sched_class):為每個調度優先級維護一個隊列,源碼如下
struct rt_prio_array {DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */ //包含一個作為分割符的位struct list_head queue[MAX_RT_PRIO];
};
位圖bitmap用來快速查找第一個非空隊列,隊列queue的下標是實時進程的調度優先級,下標越小,優先級越高。即每次調度,先找到優先級最高的非空隊列(bitmap),然后從隊列當中選擇第一個進程。
SCHED_FIFO:進程執行時無時間片,如果沒有更高優先級,那么會一直執行直到結束。
SCHED_RR:進程執行時有時間片。
公平調度類(fair_sched_class):使用完全公平調度算法,引入虛擬運行時間。
虛擬運行時間=實際運行時間*nice 0對應的權重/進程的權重
const int sched_prio_to_weight[40] = {/* -20 */ 88761, 71755, 56483, 46273, 36291,/* -15 */ 29154, 23254, 18705, 14949, 11916,/* -10 */ 9548, 7620, 6100, 4904, 3906,/* -5 */ 3121, 2501, 1991, 1586, 1277,/* 0 */ 1024, 820, 655, 526, 423,/* 5 */ 335, 272, 215, 172, 137,/* 10 */ 110, 87, 70, 56, 45,/* 15 */ 36, 29, 23, 18, 15,
};
//nice 0 對應權重是1024
//nice n-1 的權重大概是nice n 權重的1.2倍左右
空閑調度類(idle_sched_class):每個處理器有一個空閑線程,即0號線程。空閑調度類的優先級最低,僅當沒有其他進程可以調度的時候,才會執行調度空閑線程。
調度類優先級:stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class。
調度類選擇下一個進程:
停機調度類:pick_next_task_stop
限期調度類:pick_next_task_dl
實時調度類:pick_next_task_rt
公平調度類:pick_next_task_fair
linux內核是什么,每個處理器有一個運行隊列,結構體是rq,定義的全局變量如下:
rq是描述就緒隊列,其設計是為每一個CPU就緒隊列,本地進程在本地隊列上排序
struct rq中嵌入公平運行隊列cfs,實時運行隊列rt,限期運行隊列dl,停機調度類和空閑調度類在每個處理器上只有一個內核線程,不需要運行隊列,直接定義成員stop/idle分別指向遷移線程的空閑線程。
主動調度進程的函數是schedule() ,它會把主要工作委托給__schedule()去處理。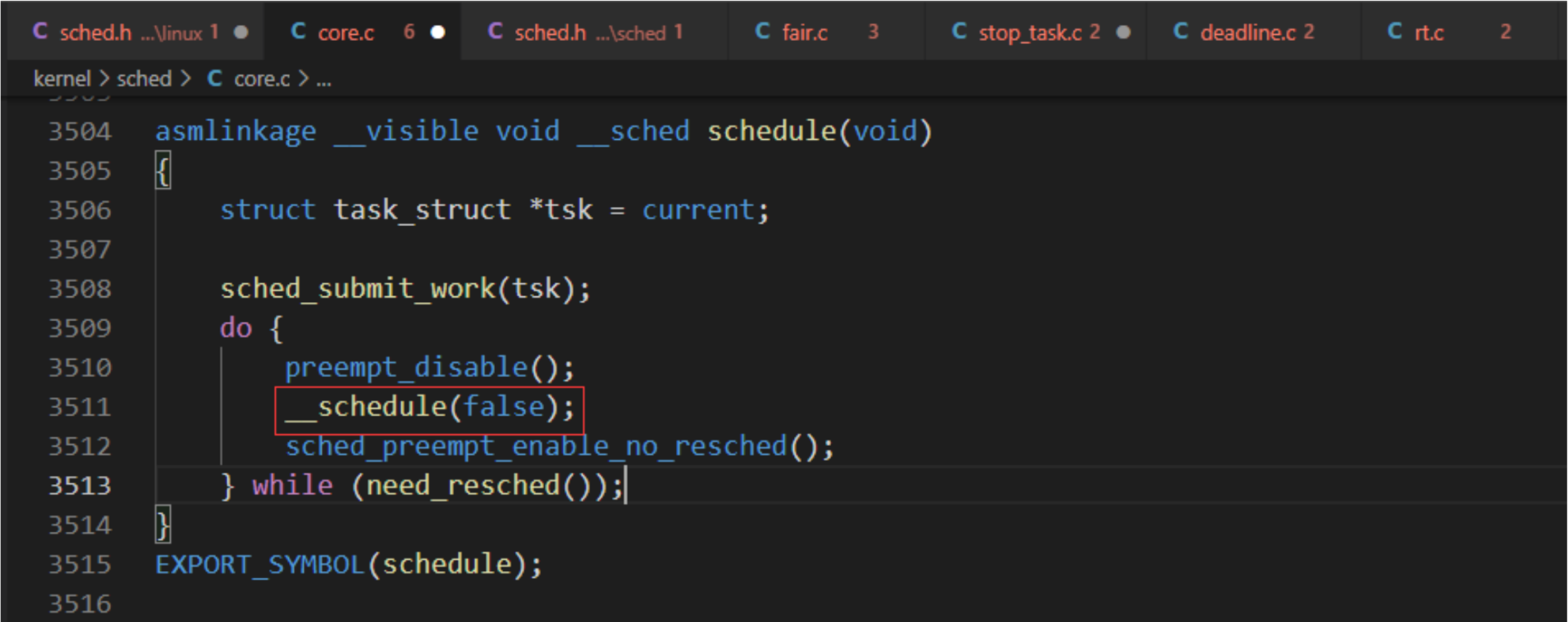
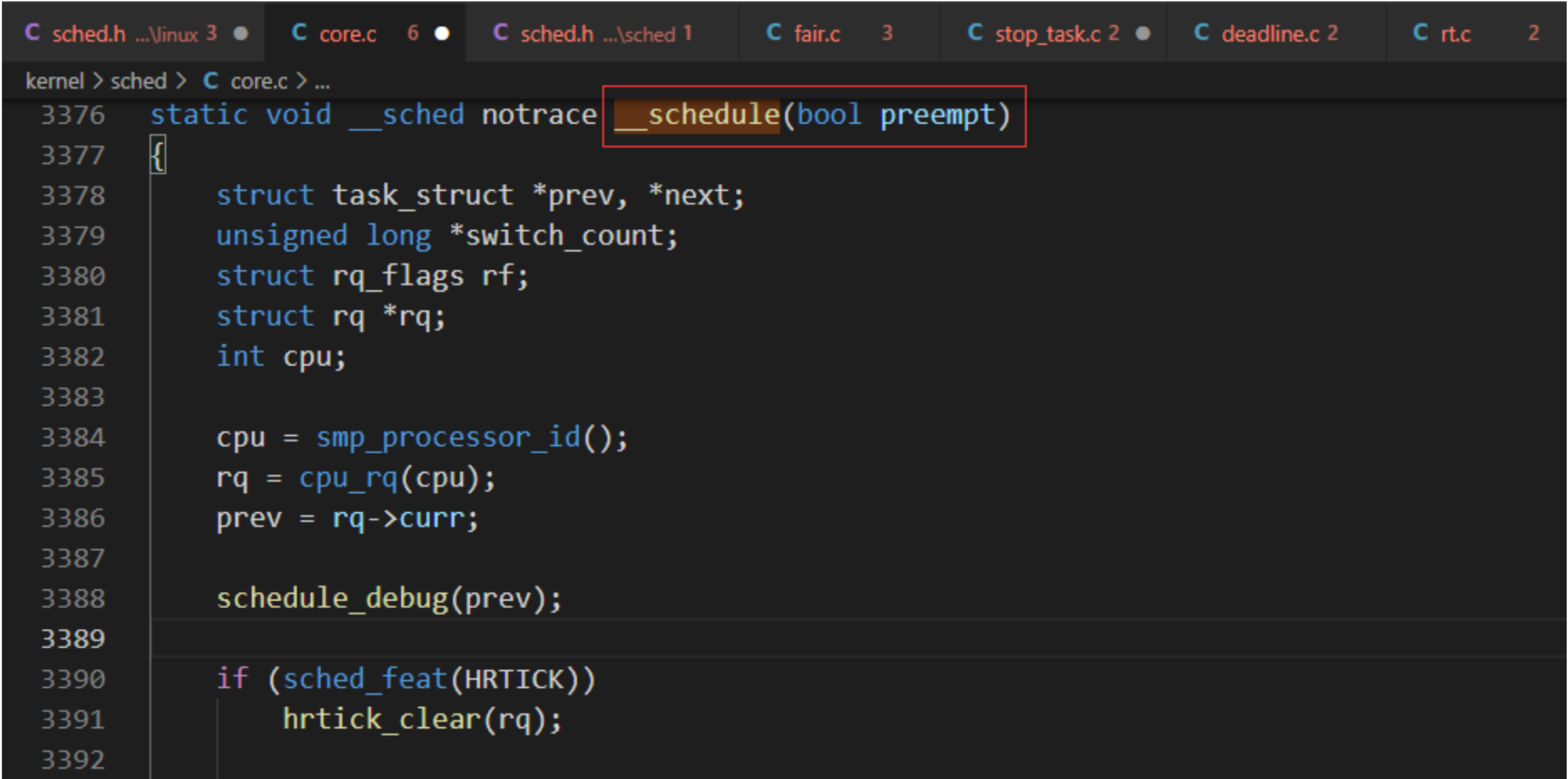
函數參數preempt表示是否搶占調度
函數__shcedule的主要處理過程如下:
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,struct task_struct *next, struct rq_flags *rf)
{struct mm_struct *mm, *oldmm;// 執行進程切換的準備工作prepare_task_switch(rq, prev, next);mm = next->mm;oldmm = prev->active_mm;/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/// 開始上下文切換, 是每種處理器架構必須定義的函數arch_start_context_switch(prev);// 如果下一個進程是內核線程(成員mm是空指針), 內核線程沒有用戶虛擬地址空間,if (!mm) {next->active_mm = oldmm;mmgrab(oldmm);// 此函數通知處理器架構不需要切換用戶虛擬地址空間, 這種加速進程切換的技術就是tlbenter_lazy_tlb(oldmm, next);} else// 如果下一個進程是用戶進程, 那么就調用此函數, 切換進程的用戶虛擬地址空間switch_mm_irqs_off(oldmm, mm, next);// 如果上一個進程是內核線程, 把成員active_mm置為空指針, 斷開它與借用的用戶虛擬地址空間的聯系, 把它借用的用戶虛擬地址空間保存在運行隊列的成員prev_mm中。if (!prev->mm) {prev->active_mm = NULL;rq->prev_mm = oldmm;}rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/rq_unpin_lock(rq, rf);spin_release(&rq->lock.dep_map, 1, _THIS_IP_);/* Here we just switch the register state and the stack. */switch_to(prev, next, prev);barrier();return finish_task_switch(prev);
}

switch_mm函數內核源碼處理如下:
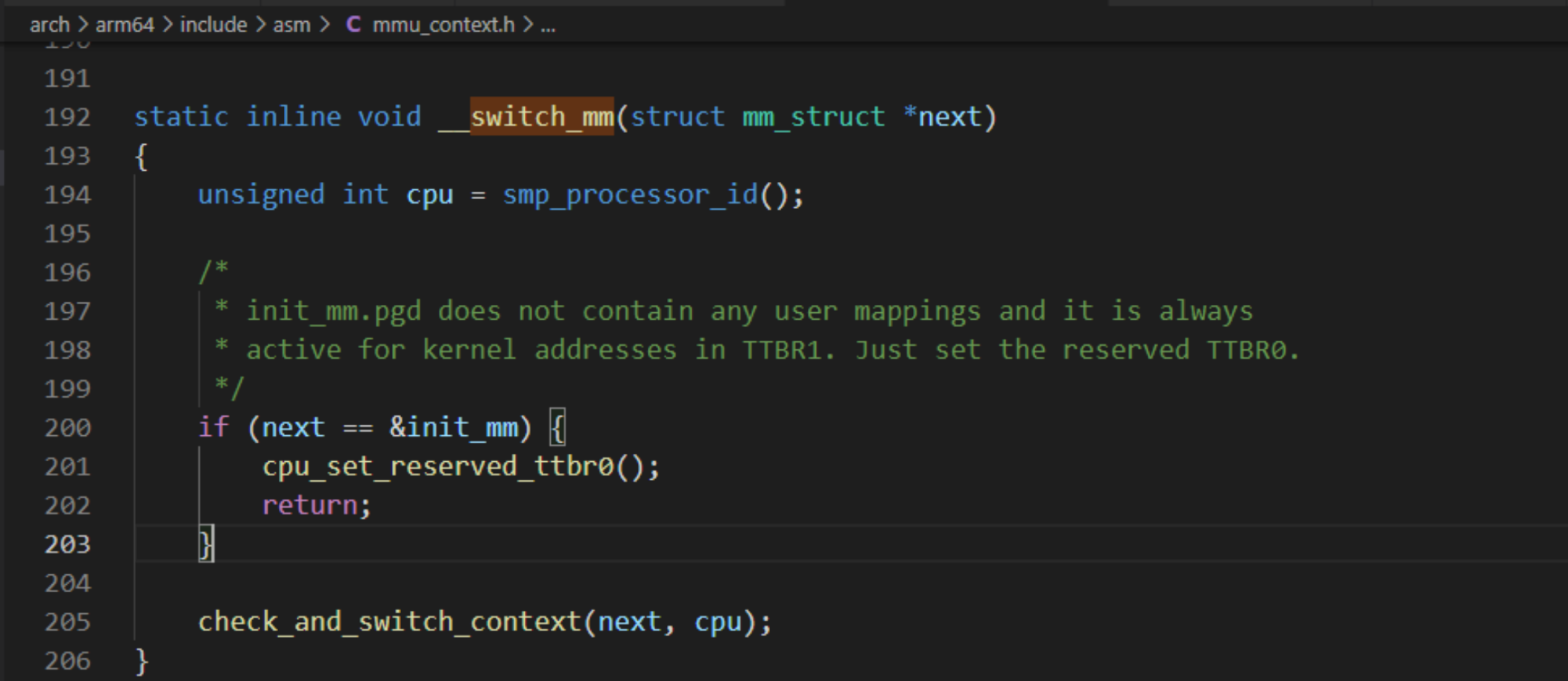
內核態和用戶態的切換
內核態:CPU可以訪問內存所有的數據,包括外圍設備(網卡、硬盤等),CPU也可以將自己從一個程序切換至另一個程序。
用戶態:只能受限的訪問,并且不允許訪問外圍設備,占用CPU的能力被剝奪,CPU資源可以被其他程序獲取。

__notrace_funcgraph struct task_struct *__switch_to(struct task_struct *prev,struct task_struct *next)
{struct task_struct *last;fpsimd_thread_switch(next); //切換到浮點寄存器tls_thread_switch(next); //切換線程本地存儲相關的寄存器hw_breakpoint_thread_switch(next); //切換調試寄存器contextidr_thread_switch(next); //切換上下文標識符寄存器entry_task_switch(next); //使用當前處理器每處理器變量記錄下一個進程的進程描述符地址uao_thread_switch(next);/** Complete any pending TLB or cache maintenance on this CPU in case* the thread migrates to a different CPU.*/// 在這個處理器上執行完前面的所有頁表緩存或緩存維護操作, 防止線程遷移到其他處理器dsb(ish);/* the actual thread switch */// 實際的線程切換last = cpu_switch_to(prev, next);return last;
}
調度進程的時機如下:
Linux內核PDF、如果我們編譯內核的時候,開啟了對內核搶占的支持,那么內核還要增加一些搶占點。
進程在用戶模式下運行的時候,無法直接調用schedule()函數,只能通過系統調用進入內核模式,如果系統調用需要等待某個資源,如互斥鎖或信號量,就會把進程的狀態設置為睡眠狀態,然后調用schedule()函數來調度進程。
進程也可以通過系統調用sched_yield()讓出處理器,這種情況下進程不會睡眠。
在內核中有三種主動調度方式:
有些“地痞流氓”進程不主動讓出處理器,內核只能依靠周期性的時鐘中斷奪回處理器的控制權,時鐘中斷是調度器的脈博。時鐘中斷處理程序檢查當前進程的執行時間有沒有超過限額,如果超過限額,設置需要重新調度的標志。當時鐘中斷處理程序準備返點處理器還給被打斷的進程時,如果被打斷的進程在用戶模式下運行,就檢查有沒有設置需要重新調度的標志,如果設置了,調用schedule函數以調度進程。
如果需要重新調度,就為當前進程的thread_info結構體的成員flags設置需要重新調度的標志。
SMP:是Symmetric Multi Processing的簡稱,意為對稱多處理系統。
SMP內有許多緊耦合多處理器,這種系統的最大特點就是共享所有資源。另外與之相對立的標準是MPP (Massively Parallel Processing),意為大規模并行處理系統,這樣的系統是由許多松耦合處理單元組成的,要注意的是這里指的是處理單元而不是處理器。
在SMP系統中,進程調度器必須支持如下:
設置進程的處理器親和性,通俗就是把進程綁定到某些處理器,只允許進程在某些處理器上執行,默認情況是進程可以在所有處理器上執行。應用編程接口和使用cpuset配置具體詳解分析。
應用編程進程內核只有兩個系統調用:
內核線程可以使用兩個函數來設置處理器親和性和親和性掩碼:
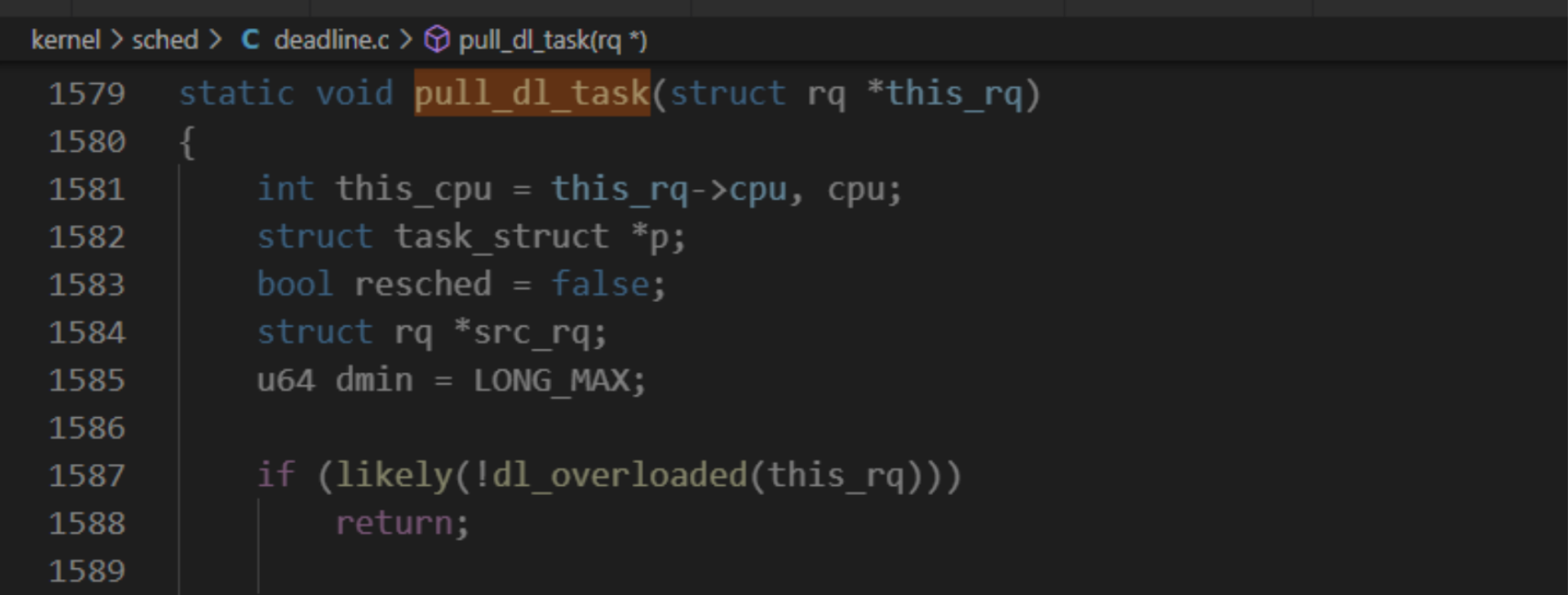
如何編譯linux內核,限期調度類的處理器負載均衡簡單,調度選擇下一個限期進程的時候,如果當前正在執行的進程是限期進程, 將會試圖從限期進程超載的處理器把限期進程搞過來。
限期進程超載定義:
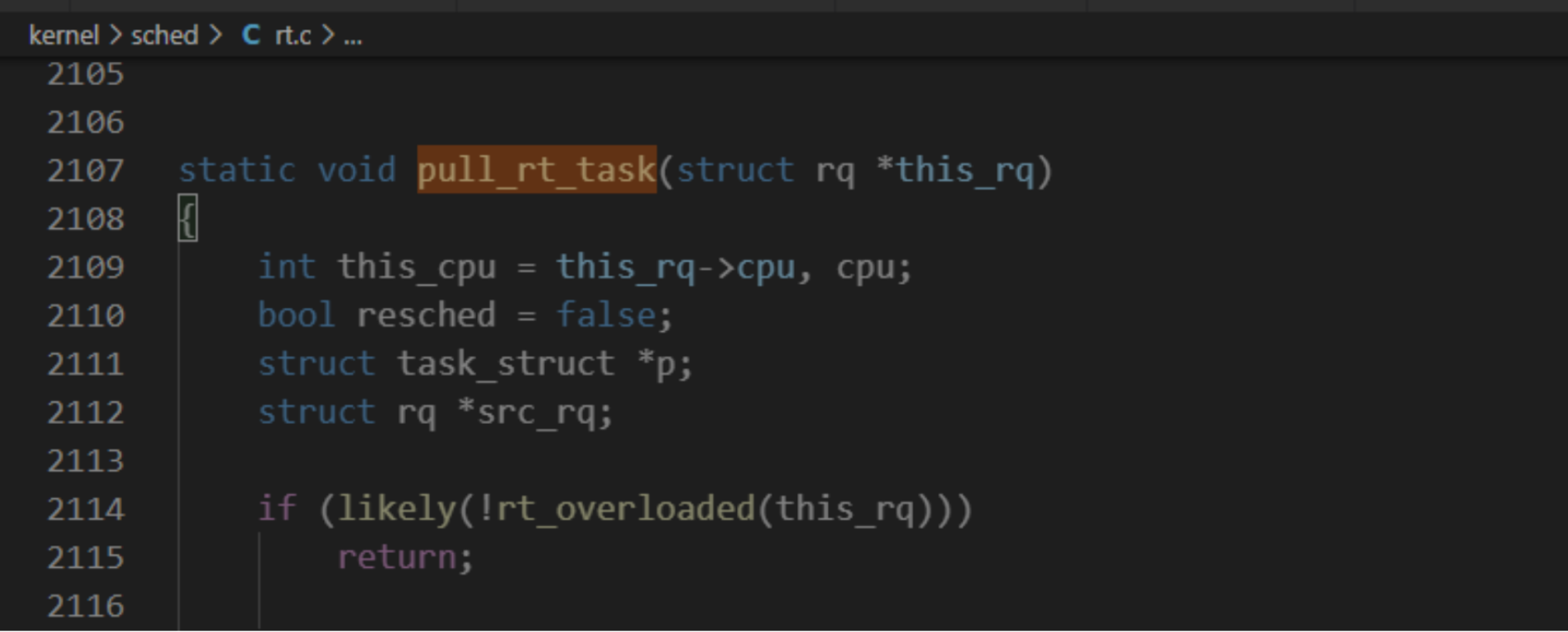
實時調度類的處理器負載均衡和限期調度類相似。調度器選擇下一個實時進程時,如果當前處理器的實時運行隊列中的進程的最高調度優先級比當前正在執行的進程的調度優先級低,將會試圖從實時進程超載的處理器把可推送實時進程拉過來。
實時進程超載的定義:
目前多處理器系統有兩種體系結構:NUMA和SMP。
處理器內部的拓撲如下:
a.核(core):一個處理器包含多個核,每個核獨立的一級緩存,所有核共享二級緩存。
b.硬件線程:也稱為邏輯處理器或者虛擬處理器,一個處理器或者核包含多個硬件線程,硬件線程共享一級緩存和二級緩存。MIPS處理器的叫法是同步多線程(Simultaneous Multi-Threading,SMT),英特爾對它的叫法是超線程。
幾個進程在訪問資源的時候彼此干擾的情況通常稱為競態條件(race condition)。
由于導致競態條件的情況非常罕見,因此需要提出一個問題:是否值得做一些(有時候是大量的)工作來保護代碼避免競態條件。在某些環境中(比如航空飛機的控制系統、重要機械的監控、危險裝備),競態條件是致命問題。
linux更新內核?每個進程中訪問臨界資源的那段代碼稱為臨界區(Critical Section)(臨界資源是一次僅允許一個進程使用的共享資源)。
屬于臨界資源的硬件如打印機等,屬于臨界資源的軟件有消息緩沖隊列、數組、緩沖區等。進程間采取互斥方式,實現對這些資源進行共享。
內核可以不受限制地訪問整個地址空間。在多處理器系統上,這會引起一些問題。如果幾個處理器同時處于核心態,則理論上它們可以同時訪問同一個數據結構。在第一個提供了SMP功能的內核版本中,該問題的解決方案非常簡單,即每次只允許一個處理器處于核心態。因此,對數據未經協調的并行訪問被自動排除了。令人遺憾的是,該方法因為效率不高,很快被廢棄了。現在內核使用由鎖組成的細粒度網絡,來明確地保護各個數據結構。如果處理器A在操作數據結構S,則處理器B可以執行任何其他的內核操作,但不能操作S。
內核為此提供了各種鎖選項,分別優化不同的內核數據使用模式。
原子操作:這些是最簡單的鎖操作。它們保證簡單的操作,諸如計數器加1之類,可以不中斷地原子執行。即使操作由幾個匯編語句組成,也可以保證。
自旋鎖:這些是最常用的鎖選項。它們用于短期保護某段代碼,以防止其他處理器的訪問。在內核等待自旋鎖釋放時,會重復檢查是否能獲取鎖,而不會進入睡眠狀態(忙等待)。當然,如果等待時間較長,則效率顯然不高。
信號量:這些是用經典方法實現的。在等待信號量釋放時,內核進入睡眠狀態,直至被喚醒。喚醒后,內核才重新嘗試獲取信號量。互斥量是信號量的特例,互斥量保護的臨界區,每次只能有一個用戶進入。
讀者/寫者鎖:這些鎖會區分對數據結構的兩種不同類型的訪問。任意數目的處理器都可以對數據結構進行并發讀訪問,但只有一個處理器能進行寫訪問。事實上,在進行寫訪問時,讀訪問是無法進行的。
自旋鎖用于處理器之間的互斥,適合保護很短的臨界區,并且不允許在臨界區睡眠。申請自旋鎖的時候,如果自旋鎖被其他處理器占有,該處理器自旋等待(也稱為忙等待)。若進程、軟中斷和硬件中斷都可以使用自旋鎖。目前內核的自旋鎖是排隊自旋鎖(queued spinlock,也稱為"FIFO ticket spinlock"),核心算法類似銀行柜臺排隊叫號。
自旋鎖算法核心思路案例(銀行柜臺排隊叫號):
a. 鎖擁有排隊號和服務號,服務號是當前占有鎖的進程的排隊號;
b. 每個進程申請鎖的時候,首先申請一個排隊號,然后輪詢服務號是否等于自己的排隊號,如果等于,表示自己占有鎖,可以進入臨界區,否則繼續輪詢;
c. 當進程釋放時,把服務號加1,下一個進程看到服務號等于自己的排隊號,退出輪詢,進入臨界區。
Linux內核自旋鎖源碼定義如下:
//如果打上實時內核補丁, 那么spinlock使用實時互斥鎖保護臨界區, 在臨界區內可以被搶占和睡眠, 但raw_spinlock還是自旋
//到目前為止, 還沒有合并實時內核補丁, 代碼可以兼容實時內核, 最好堅持3個原則://1.盡可能使用spinlock//2.絕對不允許被搶占和睡眠的地方使用raw_spinlock, 否則使用spinlock//3.如果臨界區足夠小, 使用絕對不允許被搶占和睡眠的地方使用raw_spinlock
typedef struct spinlock {union {struct raw_spinlock rlock;#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))struct {u8 __padding[LOCK_PADSIZE];struct lockdep_map dep_map;};
#endif};
} spinlock_t;typedef struct raw_spinlock {arch_spinlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAKunsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCKunsigned int magic, owner_cpu;void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
} raw_spinlock_t;
typedef struct {
#ifdef __AARCH64EB__ // 大端字節序(高位存放在低地址)u16 next; //排隊號u16 owner; //服務號
#else //小端字節序(低位存放在低地址)u16 owner; u16 next;
#endif
} __aligned(4) arch_spinlock_t;
spin_lock/spin_lock_bh/spin_trylock/spin_lock_irq
spin_unlock/spin_unlock_bh/spin_unlock_irq/spin_unlock_irqrestore
// 申請自旋鎖, 如果鎖被其他處理器占有, 當前處理器自旋等待
static __always_inline void spin_lock(spinlock_t *lock)
{raw_spin_lock(&lock->rlock);
}// 申請自旋鎖, 并且禁止當前處理器的軟中斷
static __always_inline void spin_lock_bh(spinlock_t *lock)
{raw_spin_lock_bh(&lock->rlock);
}// 申請自旋鎖, 如果申請成功返回1, 如果鎖被其他處理器占有, 當前處理器不等待, 立即返回0
static __always_inline int spin_trylock(spinlock_t *lock)
{return raw_spin_trylock(&lock->rlock);
}// 申請自旋鎖, 并且禁止當前處理器的硬中斷
static __always_inline void spin_lock_irq(spinlock_t *lock)
{raw_spin_lock_irq(&lock->rlock);
}
static inline void arch_spin_lock(arch_spinlock_t *lock)
{unsigned int tmp;arch_spinlock_t lockval, newval;asm volatile(/* Atomically increment the next ticket. */ARM64_LSE_ATOMIC_INSN(/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"__nops(3))/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"/** No: spin on the owner. Send a local event to avoid missing an* unlock before the exclusive load.*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"/* We got the lock. Critical section starts here. */
"3:": "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock): "Q" (lock->owner), "I" (1 << TICKET_SHIFT): "memory");
}
函數spin_unlock負責釋放自旋鎖,其內核源碼如下:
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{unsigned long tmp;asm volatile(ARM64_LSE_ATOMIC_INSN(/* LL/SC */" ldrh %w1, %0\n"" add %w1, %w1, #1\n"" stlrh %w1, %0",/* LSE atomics */" mov %w1, #1\n"" staddlh %w1, %0\n"__nops(1)): "=Q" (lock->owner), "=&r" (tmp):: "memory");
}
讀寫自旋鎖(又稱為讀寫鎖)是對自旋鎖的改進,區分讀者和寫者,允許多個讀者同時進入臨界區,讀者和寫者互斥,寫者和寫者互斥。如果讀者占用讀鎖,寫者申請寫鎖的時候自旋等待。如果寫者占有寫鎖,讀者申請讀鎖的時候自旋等待。
讀寫自旋鎖內核源碼定義定義如下:
typedef struct {arch_rwlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAKunsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCKunsigned int magic, owner_cpu;void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
} rwlock_t;
LINUX系統、不同處理器架構都要自己定義數據類型arch_rwlock_t,ARM64架構定義如下:
// 各種處理器架構需要自定義數據類型
typedef struct {/* no debug version on UP */
} arch_rwlock_t;內核申請讀鎖/釋放鎖,申請寫鎖/釋放鎖常用函數查閱Linux內核筆記文檔。
讀寫自旋鎖缺點:如果讀者太多,寫者很難獲取寫鎖,可能餓死。假設有一個讀者占有讀鎖,然后寫者申請寫鎖,寫者需要自旋等待,接著另一個讀者申請讀鎖,它可以獲取讀鎖,如果兩個讀者輪流占有讀鎖,可能造成寫者餓死。解決此問題,內核實現排隊讀寫鎖,主要改進是,如果寫者正在等待寫鎖,那么讀者申請讀鎖時自旋等待,寫者在鎖被釋放以后先得到寫鎖。排隊讀寫鎖配置是宏設置的。
互斥鎖只允許一個進程進入臨界區,適合保護比較長的臨界區,因為競爭互斥鎖時進程可能睡眠和再次喚醒,代價很高。盡管可以把二值信號當作互斥鎖使用,但是內核單獨實現互斥鎖,內核源碼的互斥鎖定義如下:
struct mutex {atomic_long_t owner;spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNERstruct optimistic_spin_queue osq; /* Spinner MCS lock */
#endifstruct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXESvoid *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
};
申請互斥鎖常用函數:
mutex_lock(struct mutex*lock); //申請互斥鎖,如果鎖被占有,進程深度睡眠
mutex_lock_interruptible(struct *lock); //申請互斥鎖,如果鎖被占用,進程輕度睡眠
mutex_lock_killable(struct *lock); //申請互斥鎖,如果鎖被占用,進程中度睡眠
mutex_lock_trylock(struct *lock); //申請互斥鎖,如果申請成功返回1,如果鎖被其他進程占有,那么進程不等待返回0
所有釋放互斥鎖使用的函數如下:
mutex_unlock(struct mutex*lock);
實時互斥鎖
實時互斥鎖是對互斥鎖進行改進的,實現了優先繼承,解決了優先級反轉問題。什么是優先級反轉問題?
優先級反轉問題:假設進程1的優先級低,進程2的優先級高。進程1持有互斥鎖,進程2申請互斥鎖,因為進程1已經占用互斥鎖,所以進程2必須睡眠等待,導致優先級高的進程2等待優先級低的進程1。
實時互斥鎖的作用就是當優先級低的進程持有互斥鎖,并且優先級高的進程等待互斥鎖,就把持有互斥鎖優先級低的進程的優先級臨時提高到優先級高的等待互斥鎖的進程的優先級。
原子變量
原子變量用來實現對整數的互斥訪問,通常用來實現計數器。
假設:寫一行代碼把變量a加1,編譯器把代碼編譯成3條匯編指令:
a. 把變量a從內存加載到寄存器;
b. 把寄存器的值加1;
c. 把寄存器的值寫回到內存。
linux內核參數。進程間通信共有7種:
消息隊列
消息隊列是消息的鏈接表,包括 Posix 消息隊列和 System V 消息隊列。消息隊列克服了信號承載信息量少、管道只能承載無格式字節流以及緩沖區大小受限等缺點,克服了早期 Linux 通信機制的一些缺點。消息隊列將消息看作一個記錄,具有特定的格式以及特定的優先級,對消息隊列有寫權限的進程可以向中按照一定的規則添加新消息;對消息隊列有讀權限的進程則可以從消息隊列中讀取消息,消息隊列是隨內核持續的。
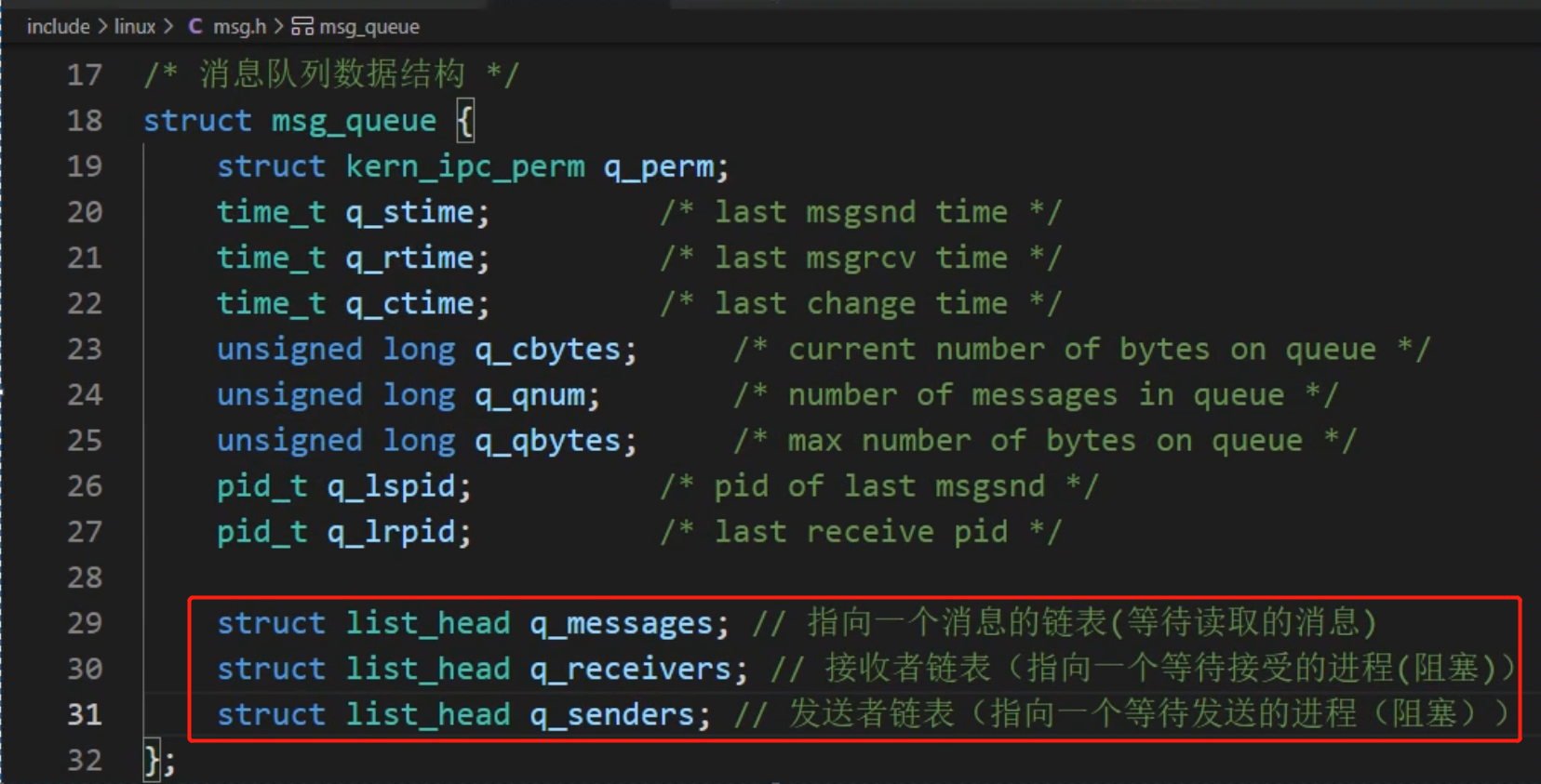
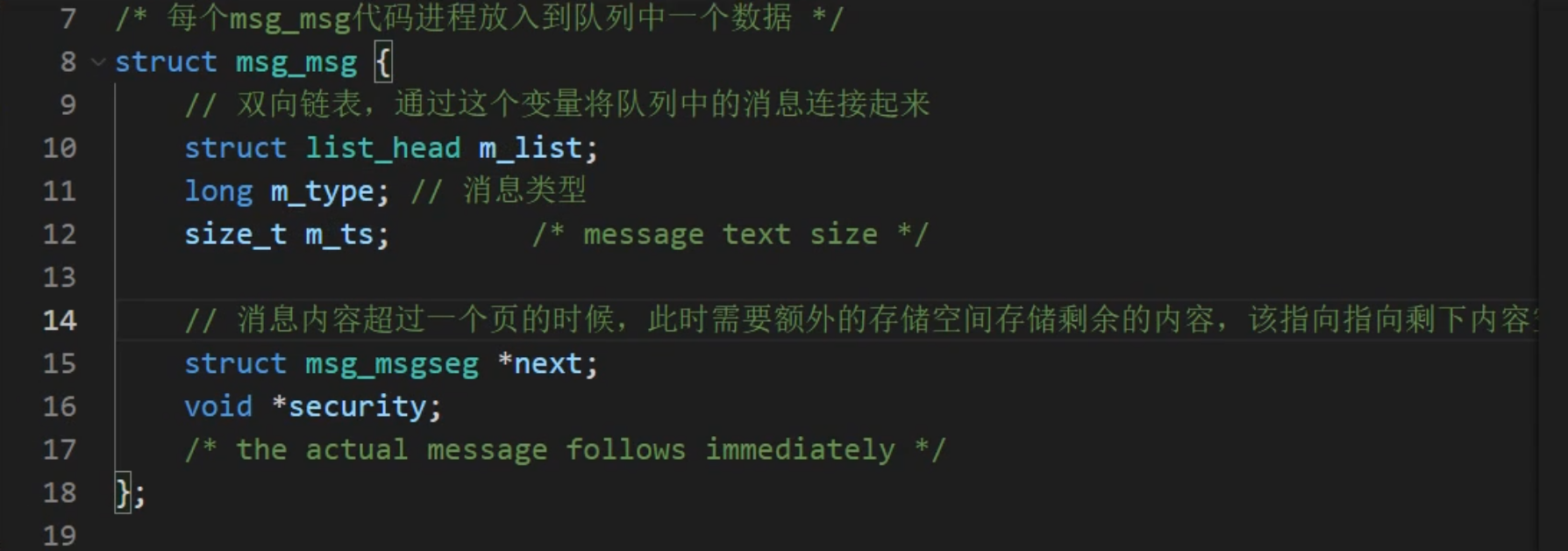
在程序上層可以直接調用msgsnd(msqid,&msgs,sizeof(struct msgstru),IPC_NOWAIT) 這樣的形式來發送消息,但是在底層是用以下的形式來調用 :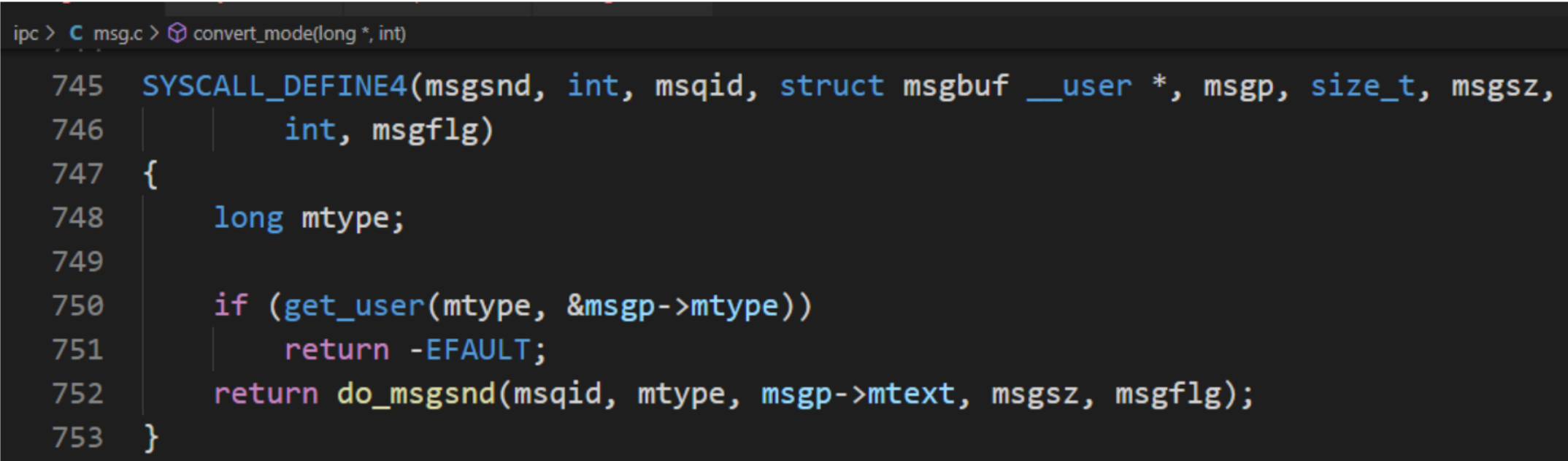
對于 SYSCALL_DEFINE4,首個變量用于函數名,剩下的偶數對參數,依次代表參數類型與參數變量。
SYSCALL_DEFINEx,隨后的 x 就是對于不同的參數的個數。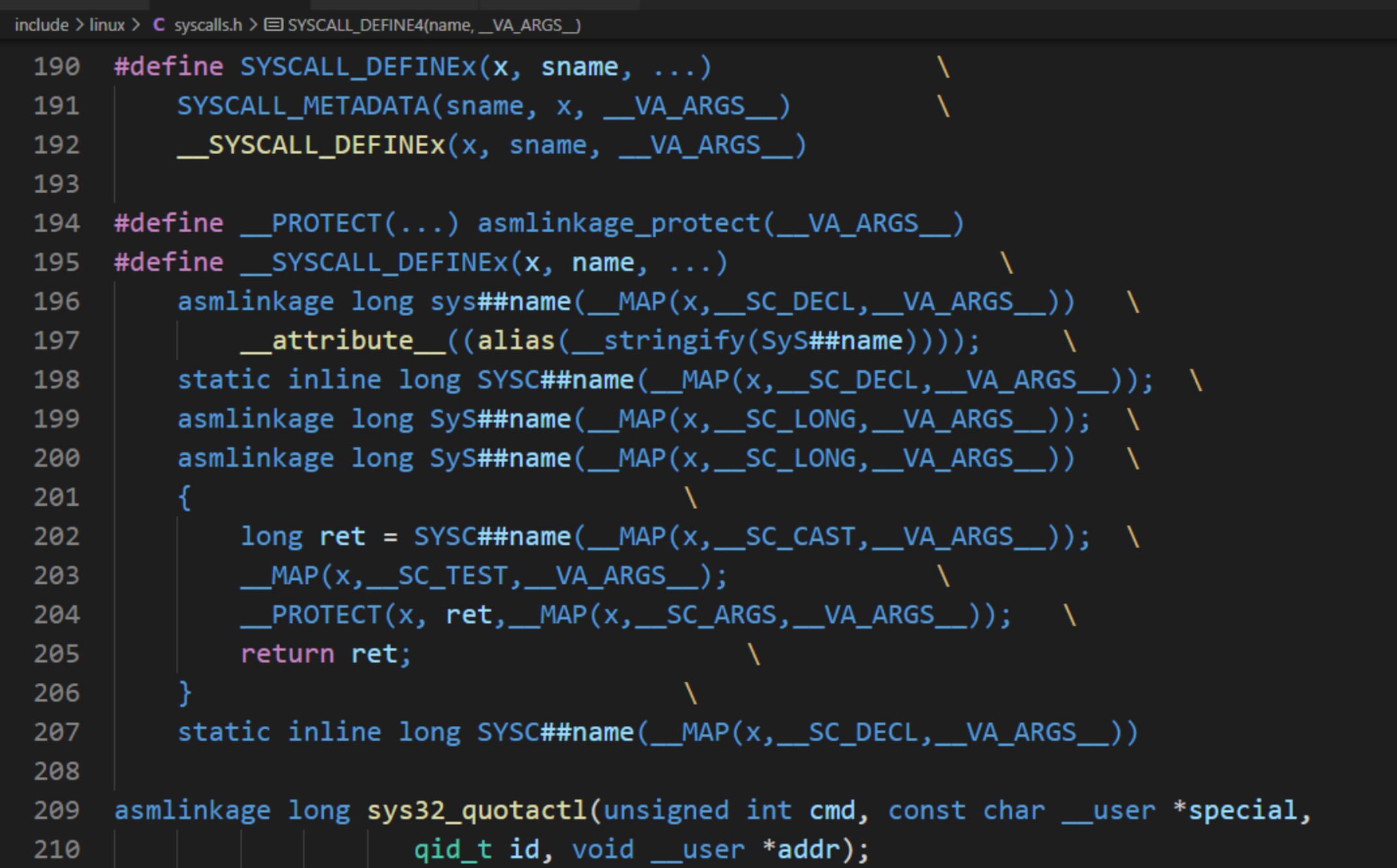
SYSCALL_DEFINEx 的定義和它具體調用的方法中 ## 是連接符,直接將參數的原來的字符替換為 ## 后的占位符。VA_ARGS 代表前面… 里面的可變參數最后調用了__do_sys##name 的方法,在后面加上大括號就是一個函數的具體定義了。
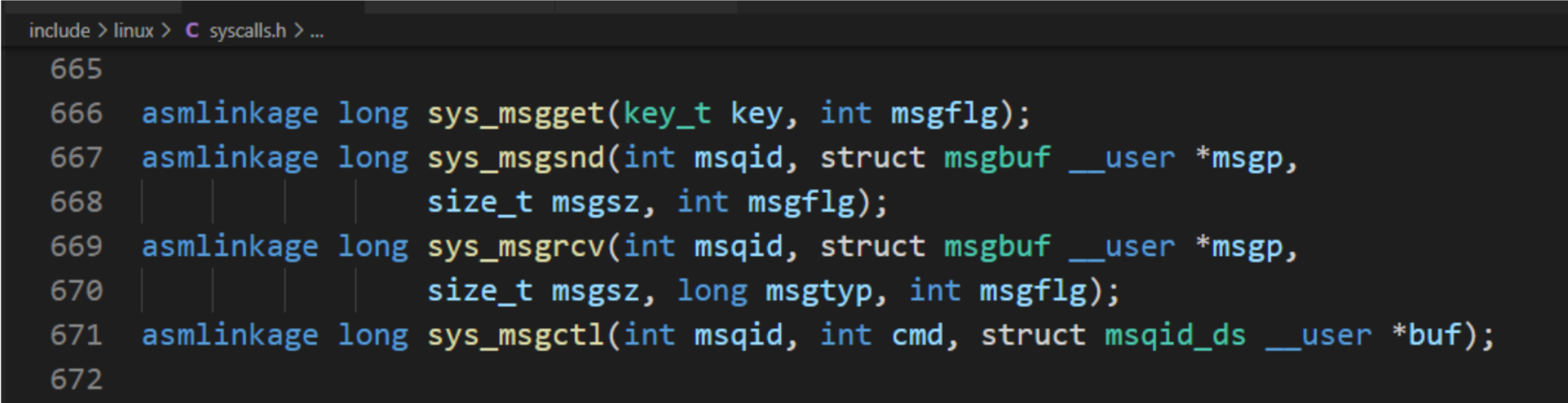
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
a.msgget 函數
得到消息隊列標識符或創建一個消息隊列對象并返回消息隊列標識符。
b.msgsnd 函數
將消息寫入到消息隊列。
c.msgrcv 函數
從消息隊列讀取消息。 msgflag:IPC_NOWAIT/IPC_EXCEPT/IPC_NOERROR
d.msgctl函數
獲取和設置消息隊列的屬性。
#include <stdio.h>
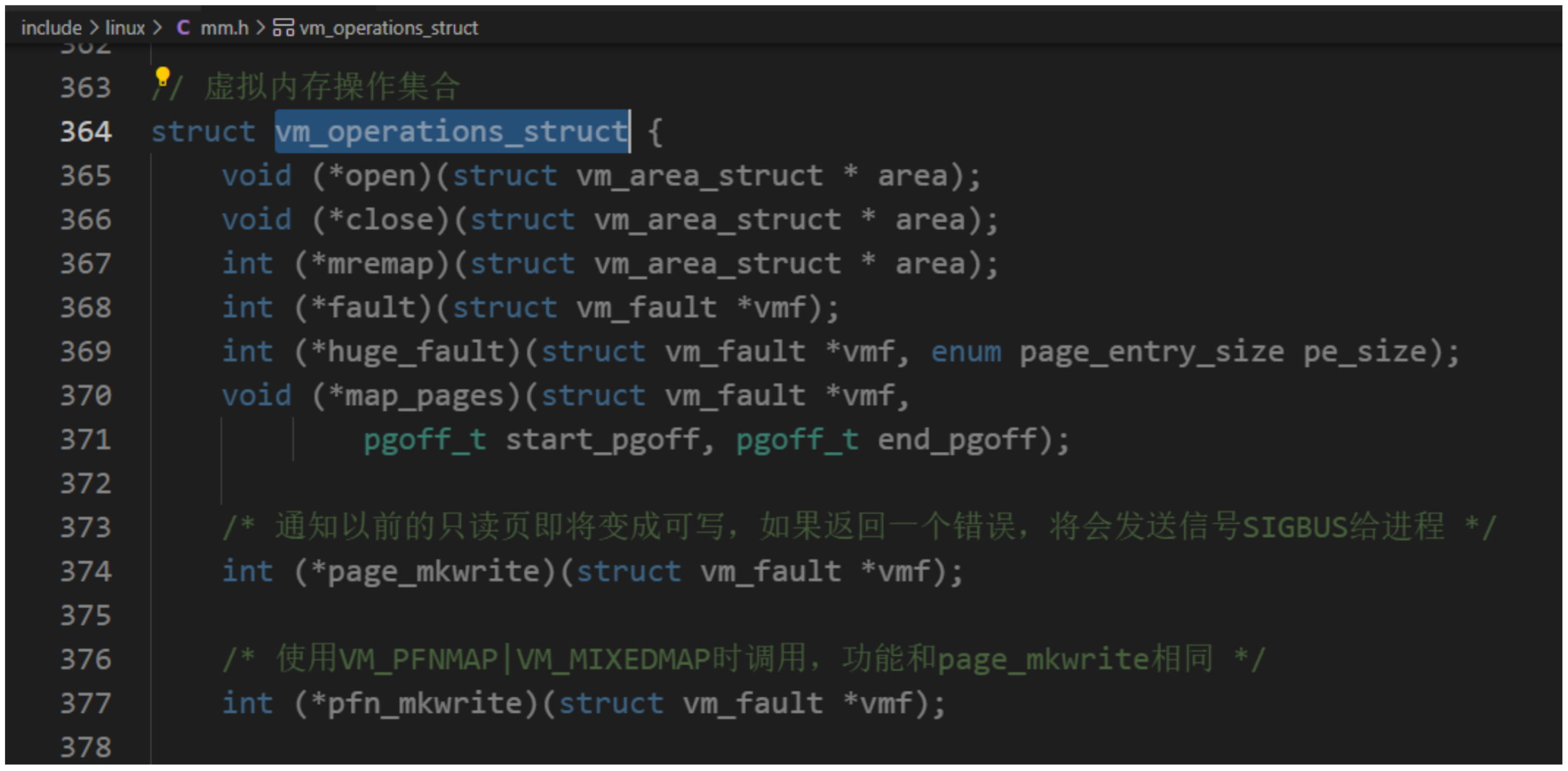
#include <stdlib.h> /* system function*/
#include <string.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <error.h>#define TEXT_SIZE 512struct msgbuf
{long mtype ;char mtext[TEXT_SIZE] ;
};int main(int argc, char **argv)
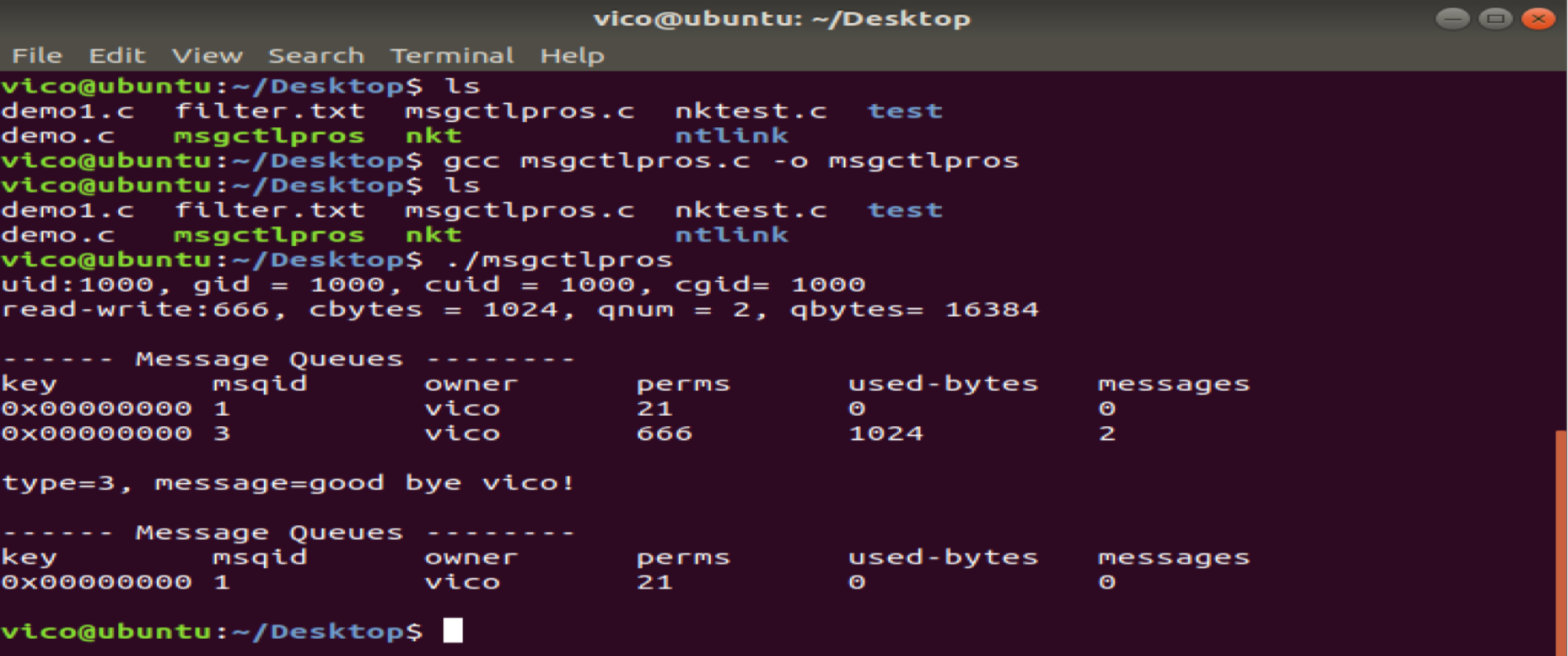
{int msqid ;struct msqid_ds info ;struct msgbuf buf ;struct msgbuf buf1 ;int flag ;int sendlength, recvlength ; msqid = msgget( IPC_PRIVATE, 0666 ) ;if ( msqid < 0 ){perror("get ipc_id error") ;return -1 ;}buf.mtype = 1 ;strcpy(buf.mtext, "How do you do!") ;sendlength = sizeof(struct msgbuf) - sizeof(long) ;flag = msgsnd( msqid, &buf, sendlength , 0 ) ;if ( flag < 0 ){perror("send message error") ;return -1 ;}buf.mtype = 3 ;strcpy(buf.mtext, "good bye vico!") ;sendlength = sizeof(struct msgbuf) - sizeof(long) ;flag = msgsnd( msqid, &buf, sendlength , 0 ) ;if ( flag < 0 ){perror("send message error") ;return -1 ;} flag = msgctl( msqid, IPC_STAT, &info ) ;if ( flag < 0 ){perror("get message status error") ;return -1 ;}printf("uid:%d, gid = %d, cuid = %d, cgid= %d\n" ,info.msg_perm.uid, info.msg_perm.gid, info.msg_perm.cuid, info.msg_perm.cgid ) ;printf("read-write:%03o, cbytes = %lu, qnum = %lu, qbytes= %lu\n" ,info.msg_perm.mode&0777, info.msg_cbytes, info.msg_qnum, info.msg_qbytes ) ;system("ipcs -q") ;recvlength = sizeof(struct msgbuf) - sizeof(long) ;memset(&buf1, 0x00, sizeof(struct msgbuf)) ;flag = msgrcv( msqid, &buf1, recvlength ,3,0 ) ;if ( flag < 0 ){perror("recv message error") ;return -1 ;}printf("type=%ld, message=%s\n", buf1.mtype, buf1.mtext) ;flag = msgctl( msqid, IPC_RMID,NULL) ;if ( flag < 0 ){perror("rm message queue error") ;return -1 ;}system("ipcs -q") ;return 0 ;
}
linux最新內核、發送方:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <time.h>#define TEXT_SIZE 512struct msgbuf
{long mtype ;int status ;char time[20] ;char mtext[TEXT_SIZE] ;
} ;char *getxttime()
{ time_t tv ;struct tm *tmp ;static char buf[20] ;tv = time( 0 ) ;tmp = localtime(&tv) ;sprintf(buf,"%02d:%02d:%02d",tmp->tm_hour , tmp->tm_min,tmp->tm_sec);return buf ;
}int main(int argc, char **argv)
{int msqid ;struct msqid_ds info ;struct msgbuf buf ;struct msgbuf buf1 ;int flag ;int sendlength, recvlength ;int key ; key = ftok("msg.tmp", 0x01 ) ;if ( key < 0 ){perror("ftok key error") ;return -1 ;}msqid = msgget( key, 0600|IPC_CREAT ) ;if ( msqid < 0 ){perror("create message queue error") ;return -1 ;}buf.mtype = 1 ;buf.status = 9 ;strcpy(buf.time, getxttime()) ;strcpy(buf.mtext, "Hello world vico!") ;sendlength = sizeof(struct msgbuf) - sizeof(long) ;flag = msgsnd( msqid, &buf, sendlength , 0 ) ;if ( flag < 0 ){perror("send message error") ;return -1 ;}buf.mtype = 3 ;buf.status = 9 ;strcpy(buf.time, getxttime()) ;strcpy(buf.mtext, "good bye vico!") ;sendlength = sizeof(struct msgbuf) - sizeof(long) ;flag = msgsnd( msqid, &buf, sendlength , 0 ) ;if ( flag < 0 ){perror("send message error") ;return -1 ;}system("ipcs -q") ;return 0 ;
}
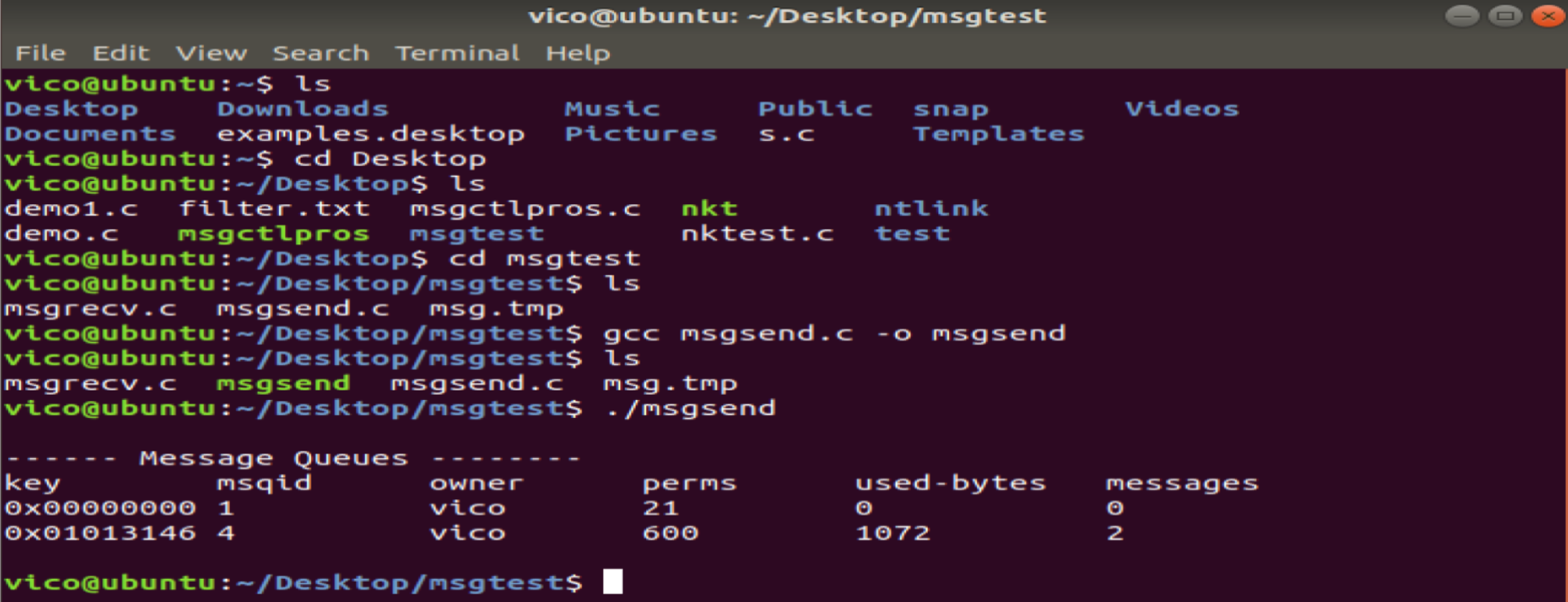
接收方:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/ipc.h>
#include <sys/msg.h>#define TEXT_SIZE 512struct msgbuf
{long mtype ;int status ;char time[20] ;char mtext[TEXT_SIZE] ;
} ;int main(int argc, char **argv)
{int msqid ;struct msqid_ds info ;struct msgbuf buf1 ;int flag ;int recvlength ;int key ;int mtype ; key = ftok("msg.tmp", 0x01 ) ;if ( key < 0 ){perror("ftok key error") ;return -1 ;}msqid = msgget( key, 0 ) ;if ( msqid < 0 ){perror("get ipc_id error") ;return -1 ;} recvlength = sizeof(struct msgbuf) - sizeof(long) ;memset(&buf1, 0x00, sizeof(struct msgbuf)) ;mtype = 1 ;flag = msgrcv( msqid, &buf1, recvlength ,mtype,0 ) ;if ( flag < 0 ){perror("recv message error\n") ;return -1 ;}printf("type=%ld,time=%s, message=%s\n", buf1.mtype, buf1.time, buf1.mtext) ;system("ipcs -q") ;return 0 ;}
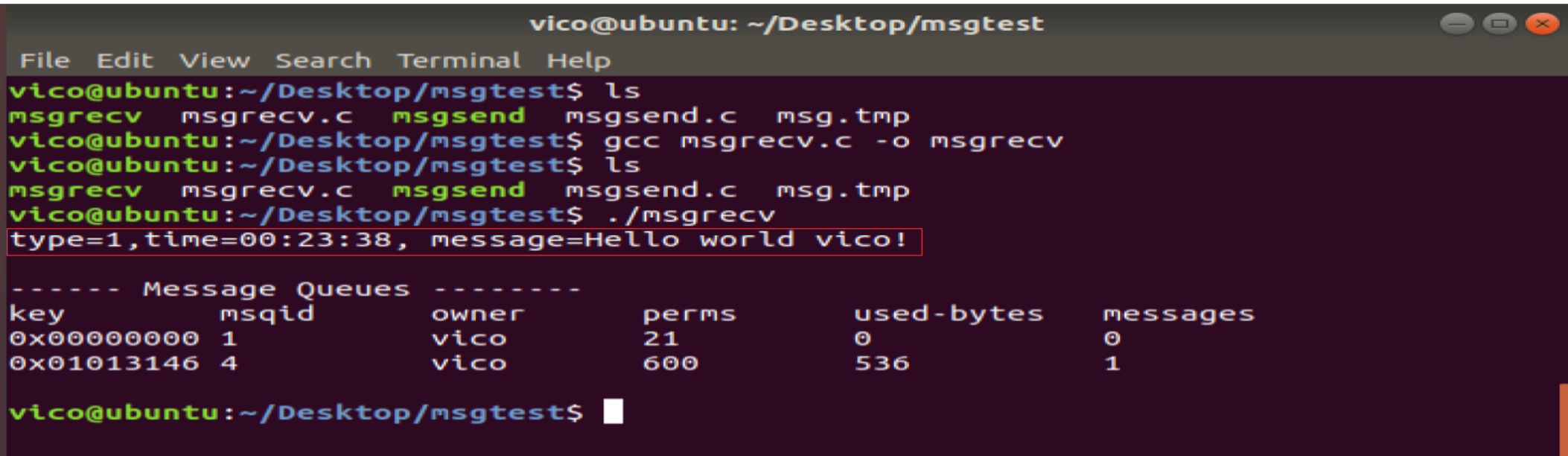
備注:刪除該消息隊列,否則就一直存在于系統當中。另外信號量和共享內存也是隨著內核持續存在的。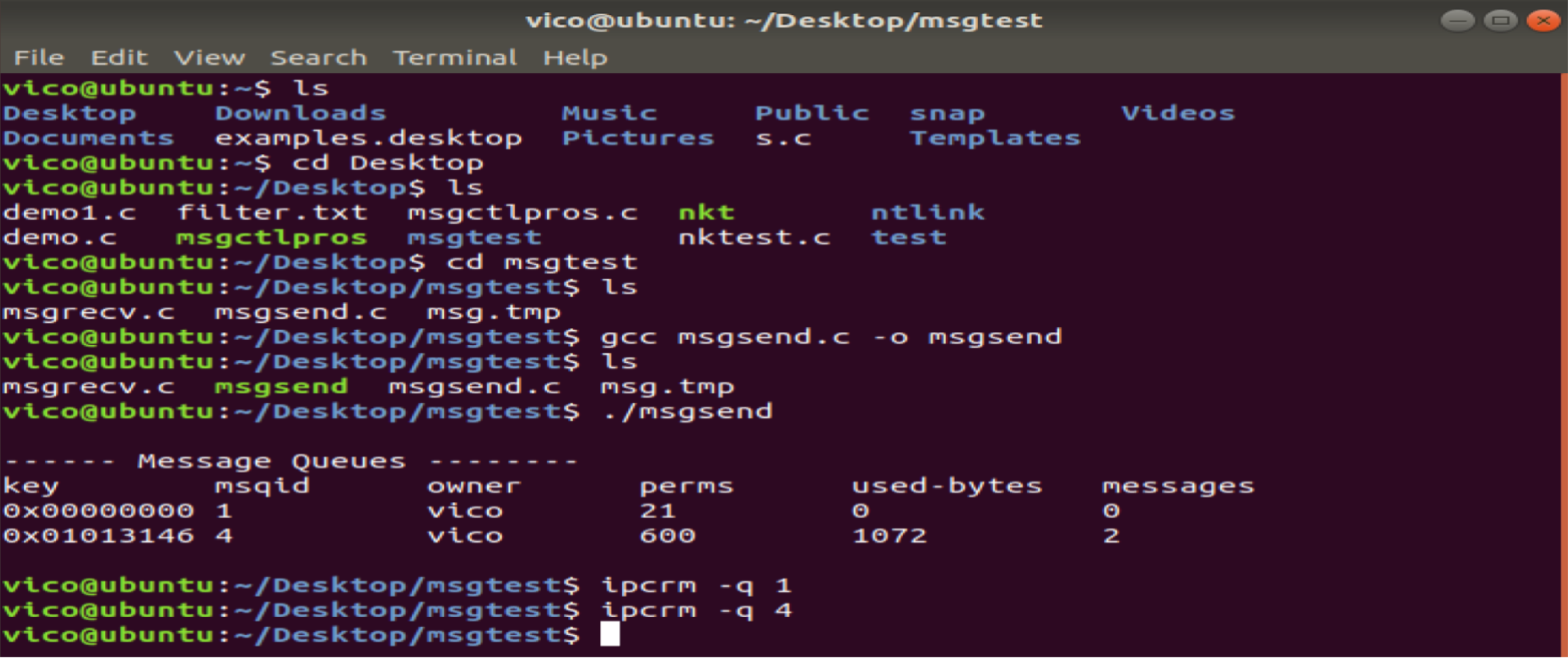
共享內存就是允許兩個或多個進程共享一定的存儲區。就如同 malloc() 函數向不同進程返回了指向同一個物理內存區域的指針。當一個進程改變這塊地址中內容的時候,其它進程都會察覺到這個更改。因為數據不需要在客戶機和服務器端之間復制,數據直接寫到內存,不用若干次數據拷貝,所以這是最快的一種IPC。備注:共享內存沒有任何的同步與互斥機制,所以要使用信號量來實現對共享內存的存取的同步。
共享內存是IPC通信中傳輸速度最快的通信方式沒有之一。共享內存原理結構圖如下: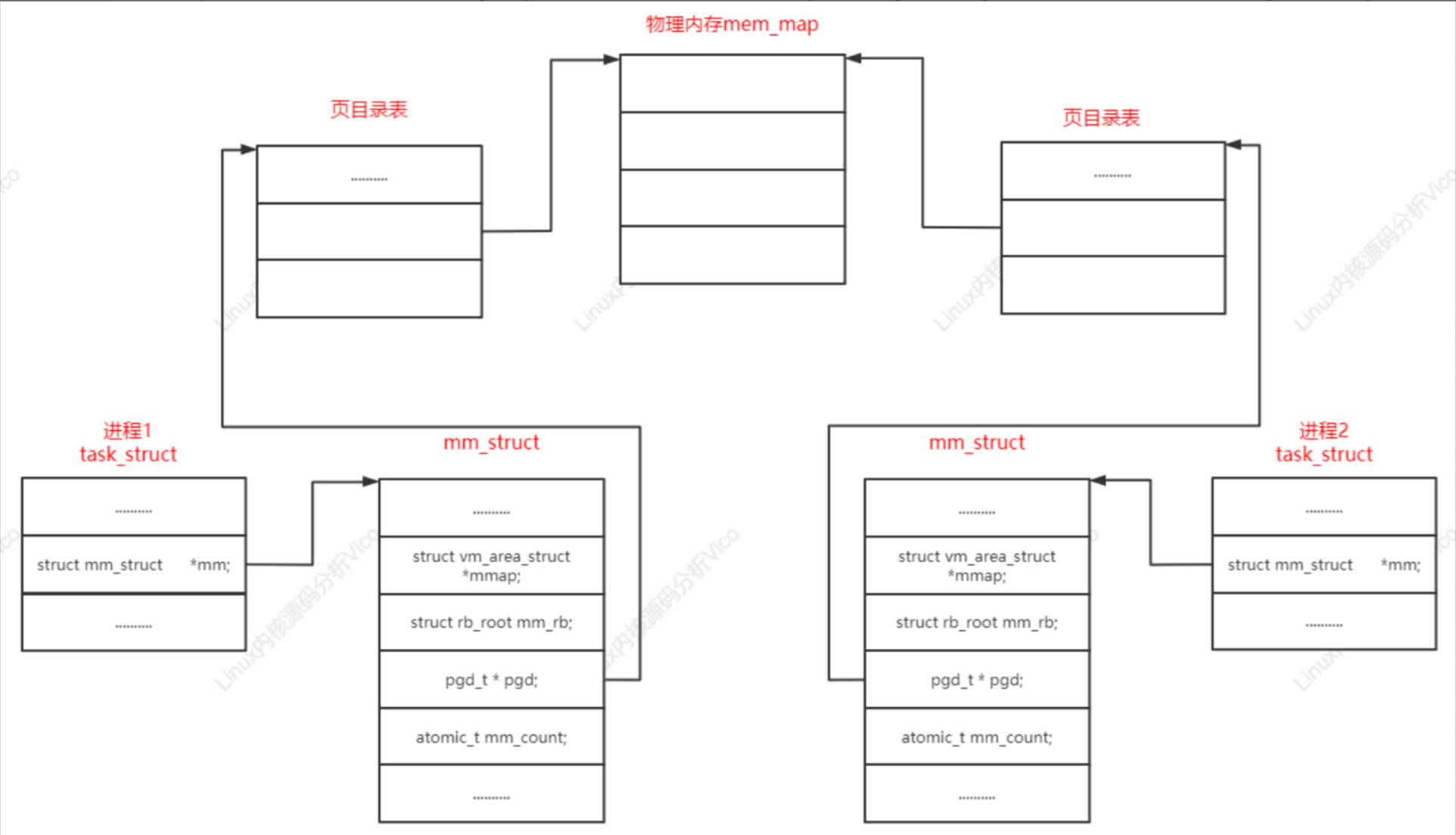
實現多個進程對共享內存的同步訪問?
通常使用信號量來實現對共享內存的同步訪問控制。
共享內存有關常用函數:
使用共享內存的優點:
共享內存進行進程間的通信非常方便,函數接口非常簡單,數據的共享還使進程間的數據不用傳遞,而是直接內存訪問,也加快程序的效率。
使用共享內存的缺點:
共享內存沒有提供同步機制,在使用共享內存進行進程間通信時,要借助其他手段來解決同步工作。
共享存儲型多處理機有兩種模型:

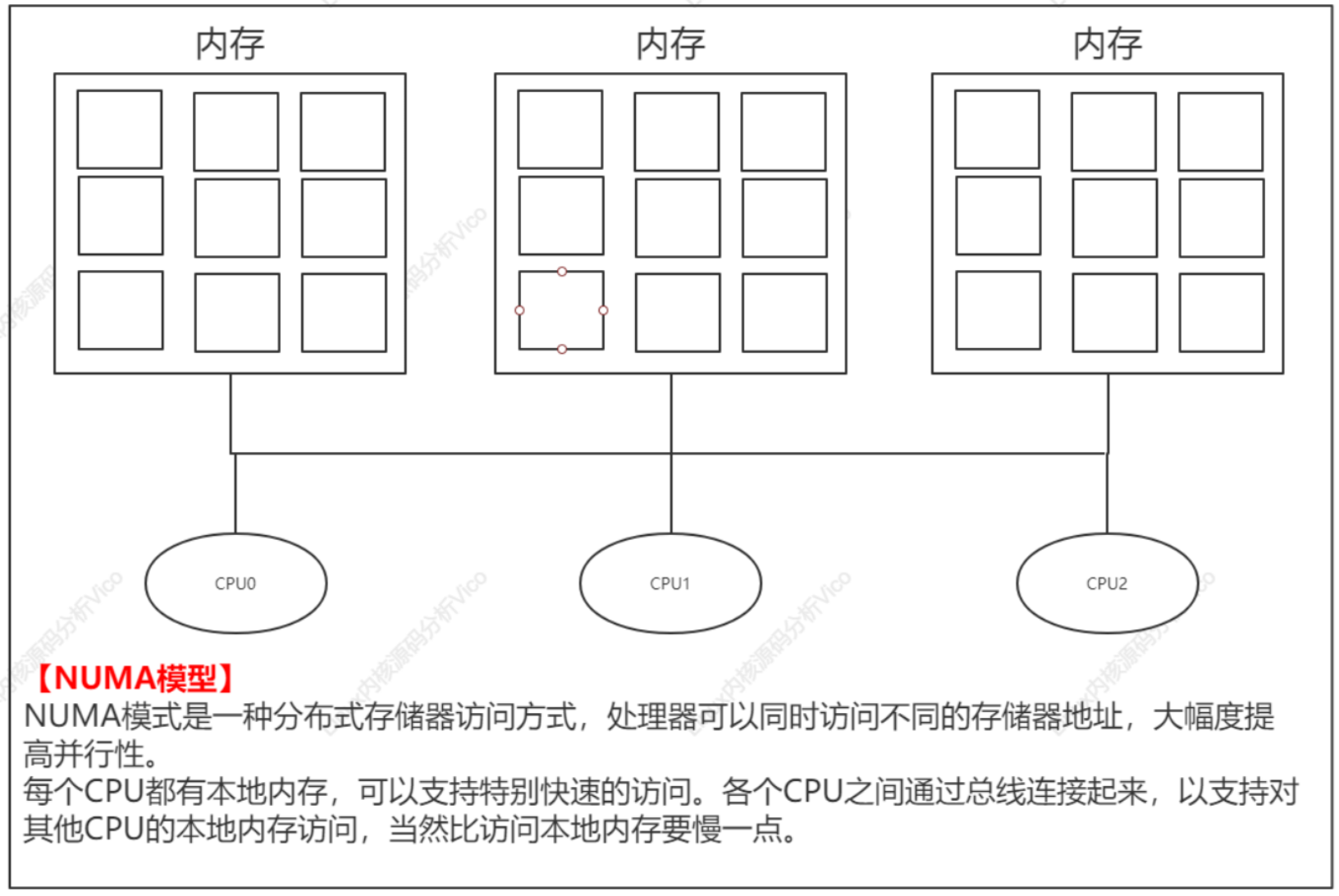
比較典型NUMA服務器:SUN15K、IBMp690等
Linux內核內存管理子系統架構如下圖所示,分為用戶空間、內核空間和硬件層3個層面。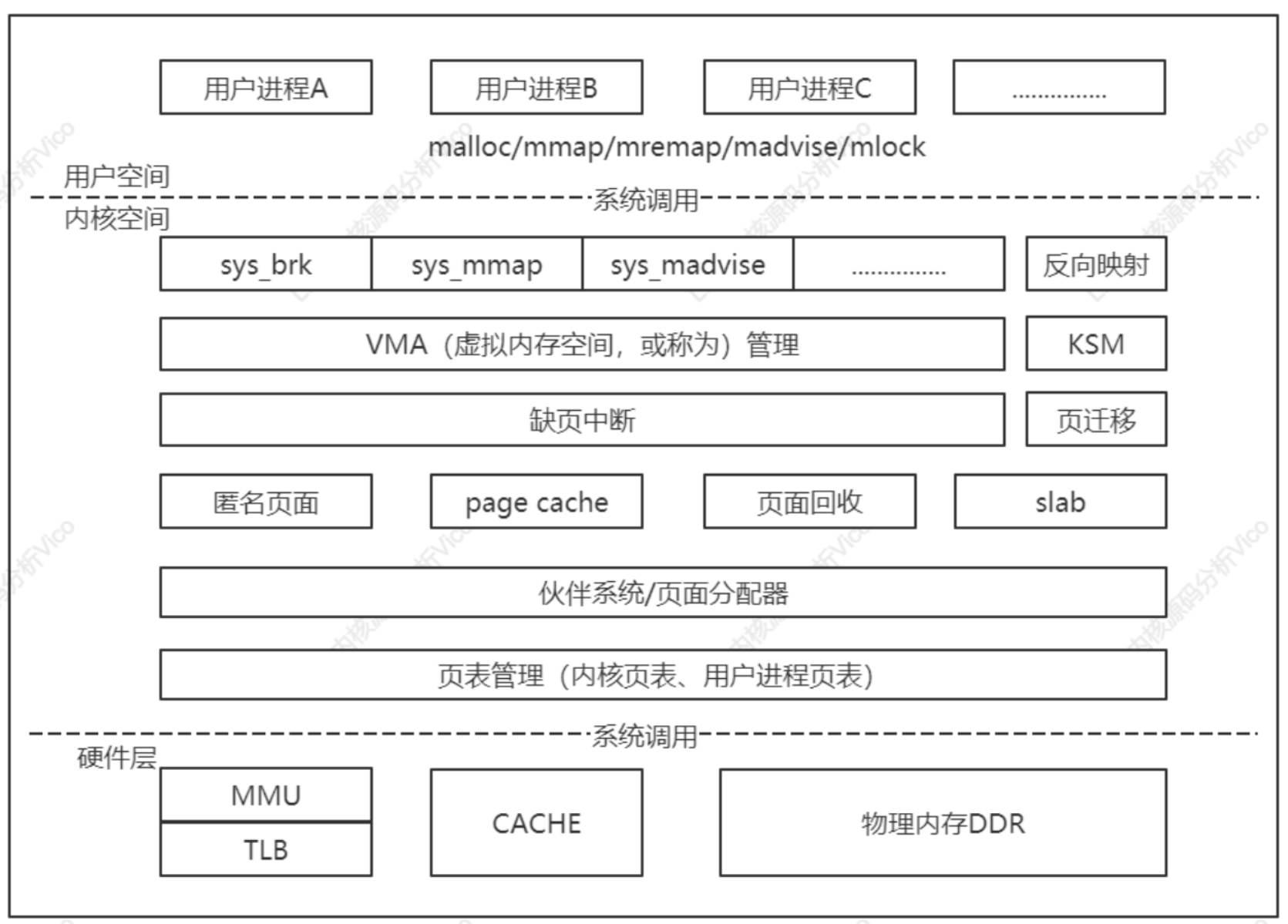
用戶空間:malloc/free–>ptmalloc(glibc)/jemalloc(FreeBSD)/tcmalloc(Google)
內核空間:sys_brk、sys_mmap、sys_munmap等等
應用程序使用malloc()申請內存,使用free()釋放內存,malloc()/free()是glibc庫的內存分配器ptmalloc提供的接口,ptmalloc使用系統調用brk/mmap向內核以頁為單位申請內存,然后劃分成小內存塊分配給用戶應用程序。用戶空間的內存分配器,除glibc庫的ptmalloc,google的tcmalloc/FreeBSD的jemalloc。
內核空間的基本功能:虛擬內存管理負責從進程的虛擬地址空間分配虛擬頁,sys_brk用來擴大或收縮堆,sys_mmap用來在內存映射區域分配虛擬頁,sys_munmap用來釋放虛擬頁。
頁分配器負責分配物理頁,當前使用的頁分配器是伙伴分配器。內核空間提供把頁劃分成小內存塊分配的塊分配器,提供分配內存的接口kmalloc()和釋放內存接口kfree()。塊分配器:SLAB/SLUB/SLOB。
內核空間的擴展功能:不連續頁分配器提供了分配內存的接口vmalloc和釋放內存接口vfree,在內存碎片化時,申請連續物理頁的成功率很低,可申請不連續的物理頁,映射到連續的虛擬頁,即虛擬地址連續頁物理地址不連續。
連續內存分配器(contiguous memory allocator,CMA)用來給驅動程序預留一段連續的內存,當驅動程序不用的時候,可以給進程使用;當驅動程序需要使用的時候,把進程占用的內存通過回收或遷移的方式讓出來,給驅動程序使用。
處理器包含一個稱為內存管理單元(Memory Management Unit,MMU)的部件,負責把虛擬地址轉換成物理地址。內存管理單元包含一個稱為頁表緩存(Translation Lookaside Buffer,TLB)的部件,保存最近使用的頁表映射,避免每次把虛擬地址轉換物理地址都需要查詢內存中的頁表。

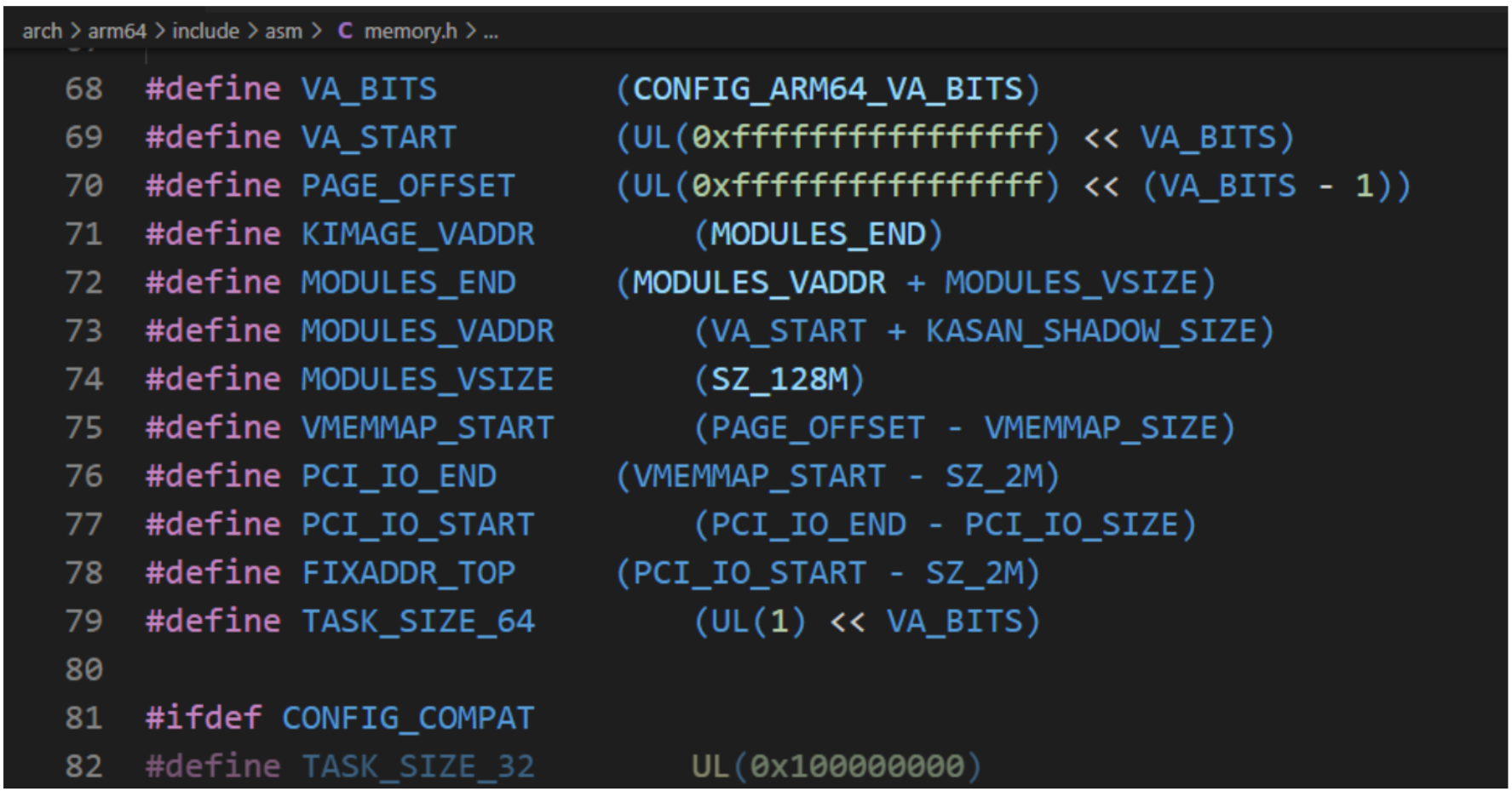
以ARM64處理器為例:虛擬地址 的最大寬度是48位。內核虛擬地址在64位地址空間頂部,高16位全是1,范圍是[0xFFFF 0000 0000 0000,0xFFFF FFFF FFFF FFFF]。用戶虛擬地址 在64位地址 空間的底部,高16位全是0,范圍是[0x0000 0000 0000 0000,0x0000 FFFF FFFF FFFF]。
在編譯ARM64架構的Linux內核時,可以選擇虛擬地址寬度:
a.選擇頁長度4KB,默認虛擬地址寬度為39位;
b.選擇頁長度16KB,默認虛擬地址寬度為47位;
c.選擇頁長度64KB,默認虛擬地址寬度為42位;
d.選擇48位虛擬地址。
在ARM64架構linux內核中,內核虛擬地址 和 用戶虛擬地址寬度相同。所有進程共享內核虛擬地址空間,每個進程有獨立的用戶虛擬地址空間,同一個線程組的用戶線程共享用戶虛擬地址空間,內核線程沒有用戶虛擬地址空間。
進程的用戶虛擬地址空間的起始地址是0,長度是TASK_SIZE,由每種處理器架構定義自己的宏TASK_SIZE。ARM64架構定義宏TASK_SIZE如下所示:
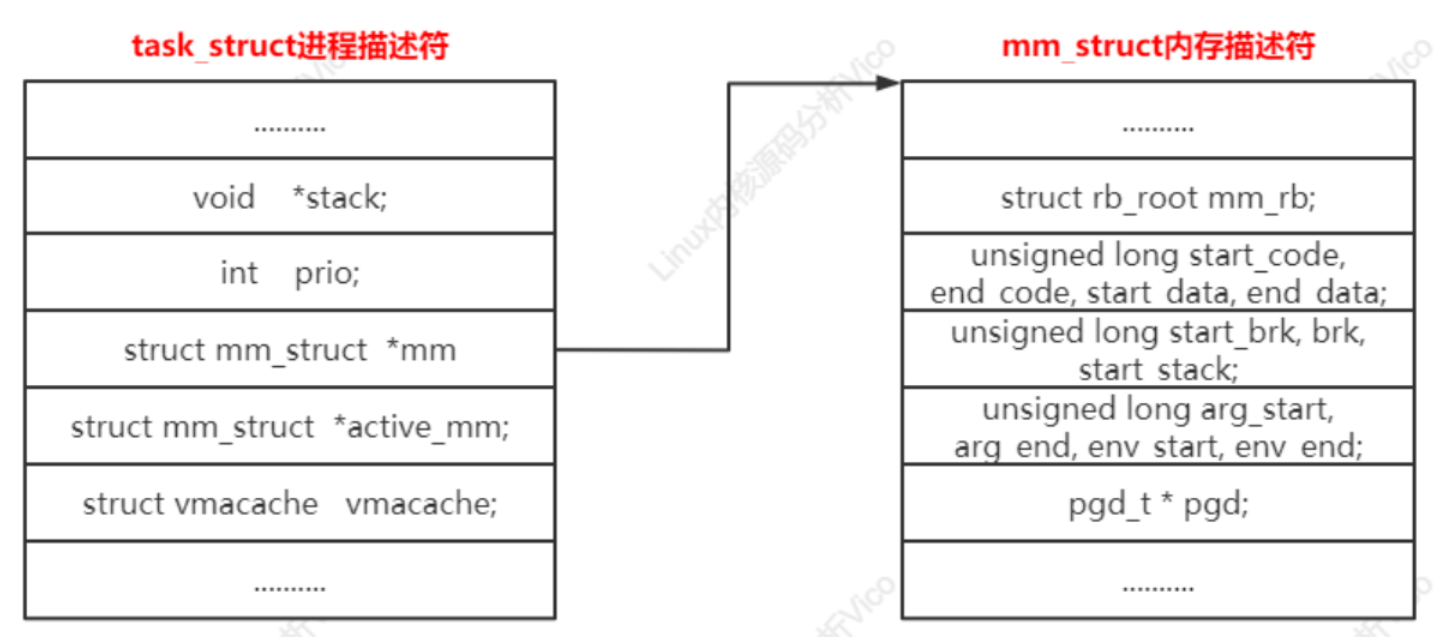
Linux內核使用內存描述符mm_struct描述進程的用戶虛擬地址空間,主要核心成員如下:
// 內存描述符結構體類型(今后要用的主要成員)
struct mm_struct {struct vm_area_struct *mmap; /* list of VMAs */ //虛擬內存區域鏈表struct rb_root mm_rb; //虛擬內存區域紅黑樹u32 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMUunsigned long (*get_unmapped_area) (struct file *filp,unsigned long addr, unsigned long len,unsigned long pgoff, unsigned long flags); //在內存映射區域找到一個沒有映射的區域
#endifunsigned long mmap_base; /* base of mmap area */ //內存映射區域的起始地址unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
#ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES/* Base adresses for compatible mmap() */unsigned long mmap_compat_base;unsigned long mmap_compat_legacy_base;
#endifunsigned long task_size; /* size of task vm space */ //用戶虛擬地址空間的長度unsigned long highest_vm_end; /* highest vma end address */pgd_t * pgd; //指向頁的全局目錄, 即第一級頁表/*** @mm_users: The number of users including userspace.** Use mmget()/mmget_not_zero()/mmput() to modify. When this drops* to 0 (i.e. when the task exits and there are no other temporary* reference holders), we also release a reference on @mm_count* (which may then free the &struct mm_struct if @mm_count also* drops to 0).*/atomic_t mm_users; //共享同一個用戶虛擬地址空間的進程數量, 也就是線程組包含的進程的數量/*** @mm_count: The number of references to &struct mm_struct* (@mm_users count as 1).** Use mmgrab()/mmdrop() to modify. When this drops to 0, the* &struct mm_struct is freed.*/atomic_t mm_count; //內存描述符的引用計數atomic_long_t nr_ptes; /* PTE page table pages */
#if CONFIG_PGTABLE_LEVELS > 2atomic_long_t nr_pmds; /* PMD page table pages */
#endifint map_count; /* number of VMAs */spinlock_t page_table_lock; /* Protects page tables and some counters */struct rw_semaphore mmap_sem;struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung* together off init_mm.mmlist, and are protected* by mmlist_lock*/unsigned long hiwater_rss; /* High-watermark of RSS usage */unsigned long hiwater_vm; /* High-water virtual memory usage */unsigned long total_vm; /* Total pages mapped */unsigned long locked_vm; /* Pages that have PG_mlocked set */unsigned long pinned_vm; /* Refcount permanently increased */unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */unsigned long stack_vm; /* VM_STACK */unsigned long def_flags;// 代碼段/數據段的起始地址和結束地址unsigned long start_code, end_code, start_data, end_data;// 堆的起始地址和結束地址 棧的起始地址unsigned long start_brk, brk, start_stack;// 參數字符串起始地址和結束地址 環境變量的起始地址和結束地址unsigned long arg_start, arg_end, env_start, env_end;unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv *//** Special counters, in some configurations protected by the* page_table_lock, in other configurations by being atomic.*/struct mm_rss_stat rss_stat;struct linux_binfmt *binfmt;cpumask_var_t cpu_vm_mask_var;/* Architecture-specific MM context */mm_context_t context; // 處理器架構特定的內存管理上下文unsigned long flags; /* Must use atomic bitops to access the bits */struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIOspinlock_t ioctx_lock;struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG/** "owner" points to a task that is regarded as the canonical* user/owner of this mm. All of the following must be true in* order for it to be changed:** current == mm->owner* current->mm != mm* new_owner->mm == mm* new_owner->alloc_lock is held*/struct task_struct __rcu *owner;
#endifstruct user_namespace *user_ns;/* store ref to file /proc/<pid>/exe symlink points to */struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIERstruct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKSpgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACKstruct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING/** numa_next_scan is the next time that the PTEs will be marked* pte_numa. NUMA hinting faults will gather statistics and migrate* pages to new nodes if necessary.*/unsigned long numa_next_scan;/* Restart point for scanning and setting pte_numa */unsigned long numa_scan_offset;/* numa_scan_seq prevents two threads setting pte_numa */int numa_scan_seq;
#endif
#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)/** An operation with batched TLB flushing is going on. Anything that* can move process memory needs to flush the TLB when moving a* PROT_NONE or PROT_NUMA mapped page.*/bool tlb_flush_pending;
#endifstruct uprobes_state uprobes_state;
#ifdef CONFIG_HUGETLB_PAGEatomic_long_t hugetlb_usage;
#endifstruct work_struct async_put_work;
};
進程描述符的成員
struct mm_struct *mm; // 進程的mm指向一個內存描述符,內核線程沒有用戶虛擬地址空間,所以mm是空指針。
struct mm_struct *active_mm; // 進程的active_mm和mm總是指向一個內存描述符,內核線程的active_mm在沒有運行時是空指針,在運行時指向上一個進程借用的內存描述符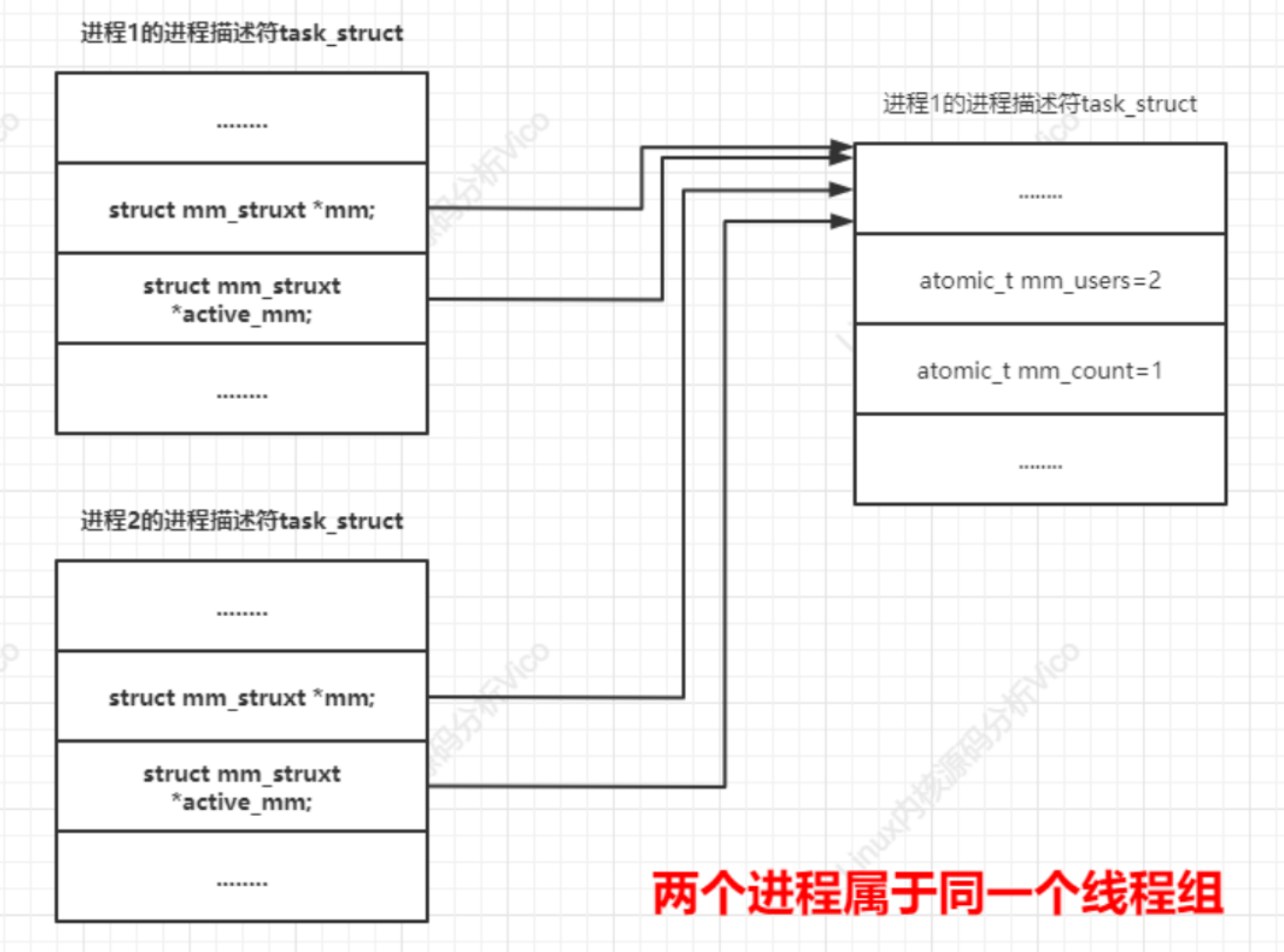
ARM64處理器架構的內核地址空間布局如下: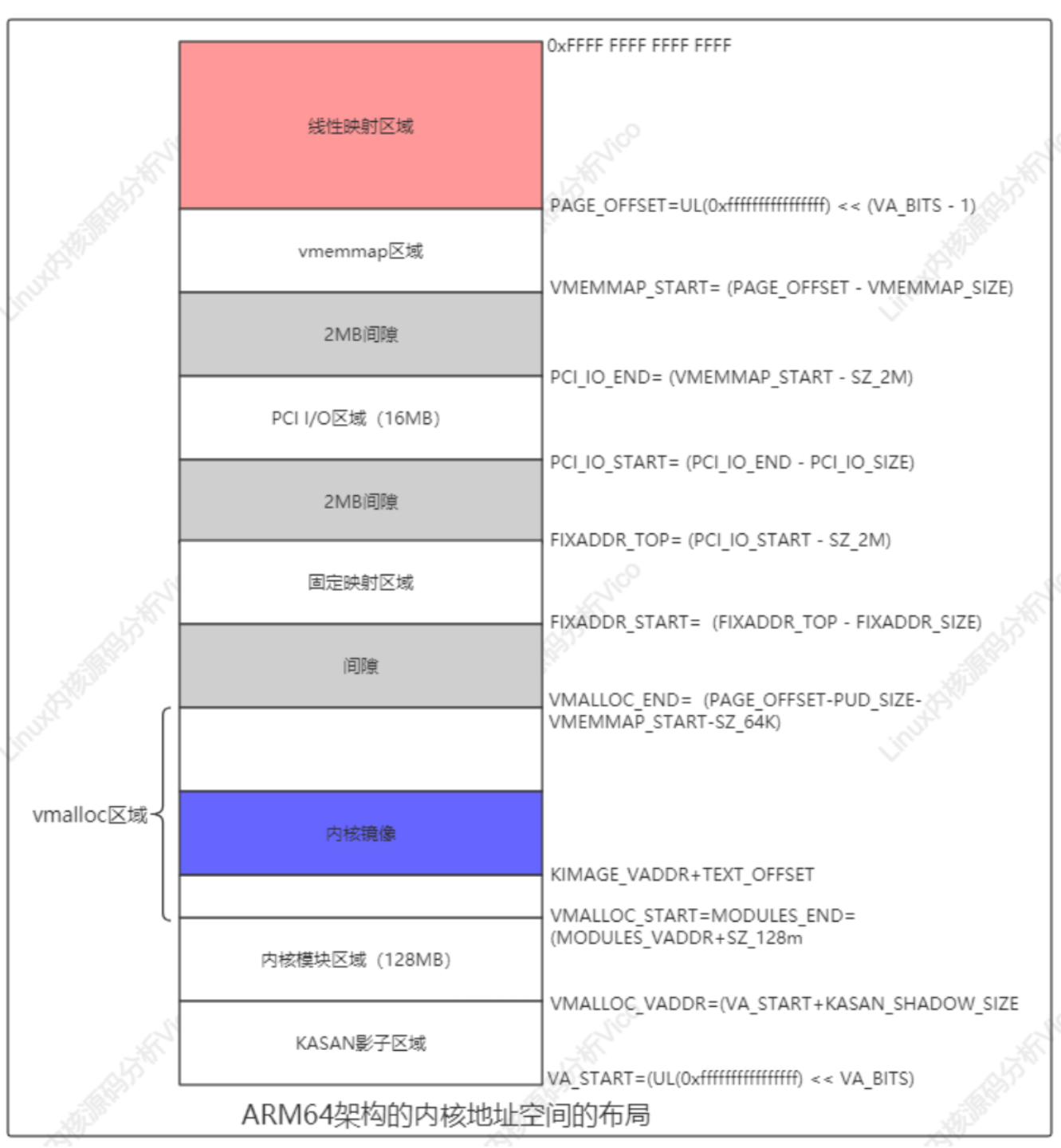
處理器的內存管理單元(Memory Management Unit,MMU)負責把虛擬地址轉換成物理地址,為了改進虛擬地址到物理地址的轉換速度,避免每次轉換都需要查找內存中的頁表,處理器廠商在內存管理單元里面增加一個稱為TLB (Translation Lookaside Buffer,TLB)的高速緩存,TLB直接為轉換后備緩沖區,意譯為頁表緩存。
不同處理器架構的TLB表項的格式不同,ARM64處理器的每條TLB表項不僅包含虛擬地址和物理地址,也包含屬性:內存類型、緩存策略、訪問權限、地址空間標識符(ASID)和虛擬機標識符(VMID)。
如果內核修改了可能緩存在TLB里面的頁表項,那么內核必須負責使舊的TLB表項失效,內核定義每種處理器架構必須實現的函數如下:
// 使所有tlb表項失效
static inline void flush_tlb_all(void)
{dsb(ishst);__tlbi(vmalle1is);dsb(ish);isb();
}// 使指定用戶地址空間的所有tlb表項失效, 參數mm是進程的內存描述符
static inline void flush_tlb_mm(struct mm_struct *mm)
{unsigned long asid = ASID(mm) << 48;dsb(ishst);__tlbi(aside1is, asid);dsb(ish);
}// 使指定用戶地址空間的某個范圍tlb表項進行失效, 參數vma是虛擬內存區域, start是起始地址, end是結束地址
static inline void flush_tlb_range(struct vm_area_struct *vma,unsigned long start, unsigned long end)
{__flush_tlb_range(vma, start, end, false);
}// 使指定用戶地址空間里面的指定虛擬頁的tlb表項失效, 參數vma是虛擬內存區域, uaddr是虛擬頁中的任意虛擬地址
static inline void flush_tlb_page(struct vm_area_struct *vma,unsigned long uaddr)
{unsigned long addr = uaddr >> 12 | (ASID(vma->vm_mm) << 48);dsb(ishst);__tlbi(vale1is, addr);dsb(ish);
}// 使內核的某個虛擬地址范圍的tlb表項失效, 參數start是起始地址, end是結束地址
static inline void flush_tlb_kernel_range(unsigned long start, unsigned long end)
{unsigned long addr;if ((end - start) > MAX_TLB_RANGE) {flush_tlb_all();return;}start >>= 12;end >>= 12;dsb(ishst);for (addr = start; addr < end; addr += 1 << (PAGE_SHIFT - 12))__tlbi(vaae1is, addr);dsb(ish);isb();
}
TLB[IS]{,}
flush_tlb_all用來使所有核的所有TLB失效,內核代碼如下: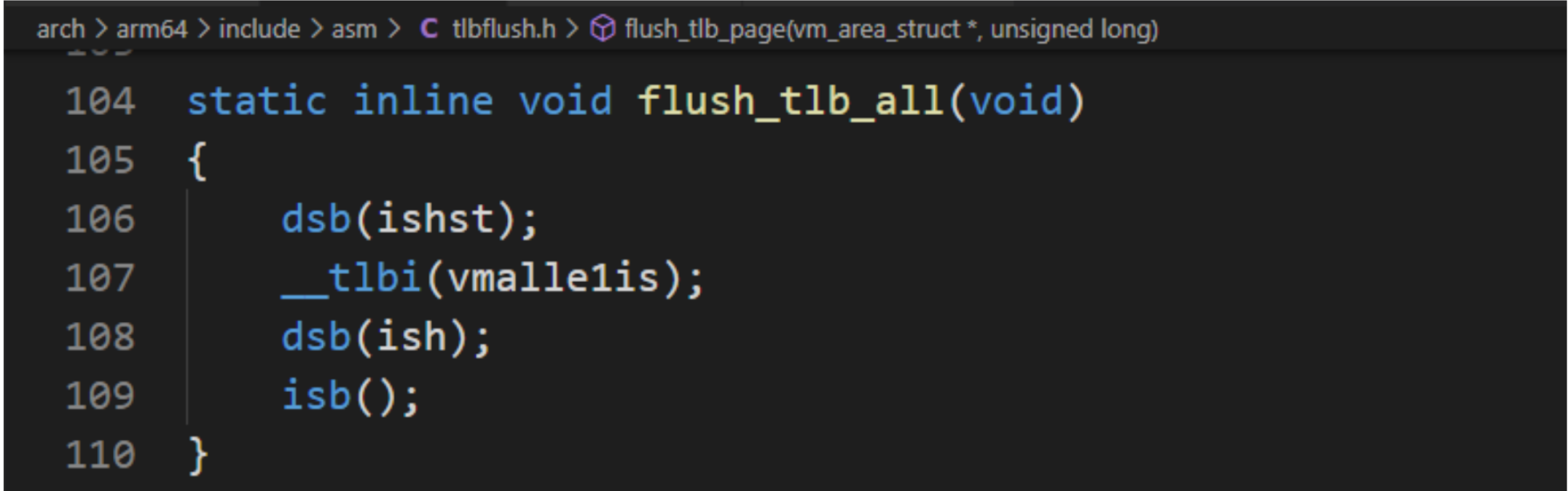
為了減少在進程切換時清空頁表緩存的需要,ARM64處理器的頁表緩存使用非全局位區分內核和進程的頁表項,使用地址空間標識符(Address Space Identifier,ASID)區分不同進程的頁表項。
虛擬機里面運行的客戶OS的虛擬地址轉換成物理地址 分為兩個階段:
a.把虛擬地址轉換成中間物理地址(由客戶操作系統的內核控制,和非虛擬化的轉換過程相同);
b.把中間物理地址轉換成物理地址(由虛擬機監控器控制,虛擬機監控器為每個虛擬機維護一個轉換表,分配一個虛擬機標識符VMID(Virutal machine identifier));
每個虛擬機有獨立的ASID空間,頁表緩存使用虛擬標識 符區別不同虛擬機轉換表項,可以避免每次虛擬機切換都要清空頁表緩存,只需要在虛擬機標識符回繞時把處理器的頁表緩存清空。
層次化的頁表用于支持對大地址空間的快速、高效的管理。頁表用于建立用戶進程的虛擬地址空間和系統物理內存(內存、頁幀)之間的關聯。頁表用來把虛擬頁映射到物理頁,并且存放頁的保護位,即訪問權限。Linux內核把頁表分為4級:
PGD、PUD、PMD、PT。
4.11以后版本把頁表擴展到五級,在頁全局目錄和頁上層目錄之間增加了頁四級目錄(Page 4th Directory,P4D)
選擇四級頁表:頁全局目錄、頁上層目錄、頁中間目錄、直接頁表;
選擇三級頁表:頁全局目錄、頁中間目錄、直接頁表;
選擇二級頁表:頁全局目錄、直接頁表;
處理器架構怎么選擇多少級?在內核配置宏CONFIG_PGTABLE_LEVELS配置頁表級數,
案例分析五級頁表結構如下: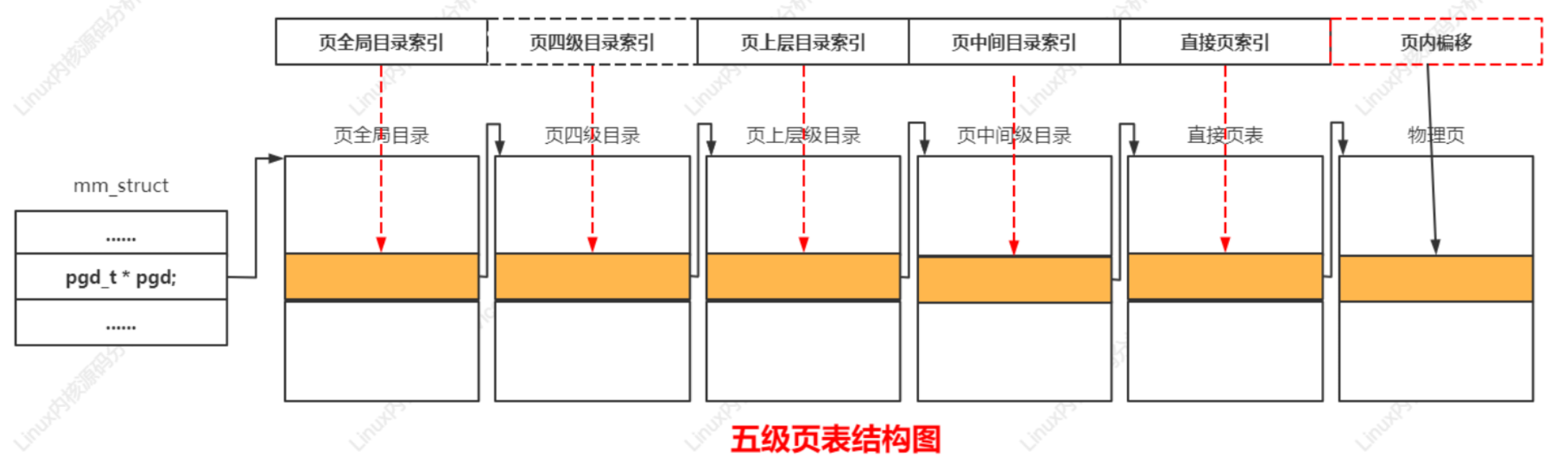
內核初始化完畢后,使用頁分配器管理物理頁,當前使用的頁分配器就是伙伴分配器,伙伴分配器的特點是管理算法簡單且高效。
連續的物理頁稱為頁塊(page block),階(order)是頁的數量單位,2的n次方個連續頁稱為n階頁塊,滿足如下條件的兩個n階頁塊稱為伙伴(buddy)。
1)兩個頁塊是相鄰的,即物理地址是連續的;
2)頁塊的第一頁的物理面頁號必須是2的n次方的整數倍;
3)如果合并(n+1)階頁塊,第一頁的物理頁號必須是2的括號(n+1)次方的整數倍。
伙伴分配器分配和釋放物理頁的數量單位也為階(order)。
以單頁為說明,0號頁和1號頁是伙伴,2號頁和3號頁是伙伴。1號頁和2號頁不是伙伴?因為1號頁和2號頁合并組成一階頁塊,第一頁的物理頁號不是2的整數倍。
分配n階頁塊的過程:
a. 查看是否有空閑的n階頁塊,如果有,直接分配,如果沒有,繼續執行下一步;
b. 查看是否存在空閑的(n+1)階頁塊,如果有把(n+1)階頁塊分裂為兩個n階頁塊,一個插入空閑n階頁塊鏈表,另一個分配出去,如果沒有,繼續執行下一步;
c. 查看是否存在空閑的(n+2)階頁塊,如果有,把(n+2)階頁塊分裂為兩個(n+1)階頁塊,一個插入空閑(n+1)階頁塊鏈表,另一個分裂為兩個n階頁塊,一個插入空閑n階頁塊鏈表,另一個分配出去;如果沒有繼續查看更高階是否存在空閑頁塊。
內核在基本伙伴分配器基礎上進一步擴展:
a. 支持內存節點和區域,稱為分區的伙伴分配器;
b. 為預防內存碎片,把物理頁根據可移動性分組;
c. 針對分配單頁做性能優化,為減少處理器之間的鎖競爭,在內存區域增加1個每處理器頁集合。
內存區域的結構體成員free_area用來維護空閑頁塊,數組下標對應頁塊的階數。結構體free_area的成員free_list是空閑頁塊的鏈表,nr_free是空閑頁塊的數量。內存區域的結構體成員managed_pages是伙伴分配器管理的物理頁的數量。
...
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
... struct zone {/* Read-mostly fields *//* zone watermarks, access with *_wmark_pages(zone) macros */unsigned long watermark[NR_WMARK];unsigned long nr_reserved_highatomic;......unsigned long managed_pages;unsigned long spanned_pages;unsigned long present_pages;const char *name;....../* free areas of different sizes */// MAX_ORDER是最大階數, 實際上是可分配的最大除數加1, 默認值是11, 意味伙伴分配器一次 最多可分配2的10次方頁 struct free_area free_area[MAX_ORDER];bool contiguous;ZONE_PADDING(_pad3_)/* Zone statistics */atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;

首選的內存區域在什么情況下從備用區域借用物理頁?此問題從區域水線講解深入理解,每個內存區域有3個水線。
a.高水線(HIGH):如果內存區域的空閑頁數大于高水線,說明該內存區域的內存充足;
b.低水線(LOW):如果內存區域的空閑頁數小于低水線,說明該內存區域的內存輕微不足;
c.最低水線(MIN):如果內存區域空閑頁數小于最低水線,說明該內存區域的內存嚴重不足。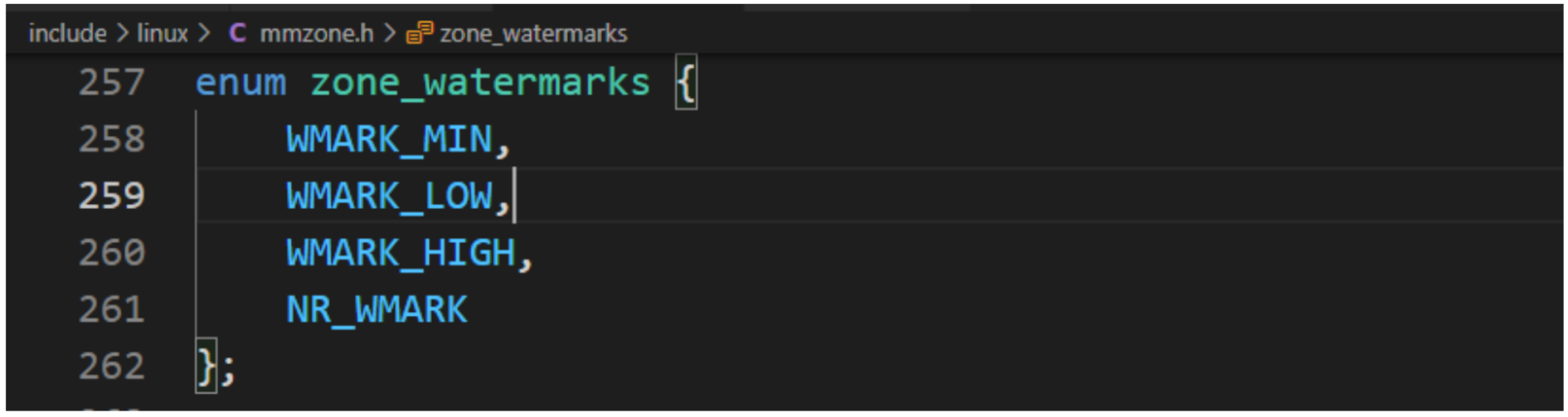
struct zone {/* Read-mostly fields *//* zone watermarks, access with *_wmark_pages(zone) macros */unsigned long watermark[NR_WMARK]; ......atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
計算水線時,有兩個重要的參數:
修改最小空閑字節數方式:
cat /proc/sys/vm/min_free_kbytes
修改水線縮放因子方式:
cat /proc/sys/vm/watermark_cacle_factor
通過函數__setup_per_zone_wmarks()負責計算每個內存區域的最低水線、低水線和高水線。
計算最低水線方法:
min_free_pages=min_free_kbytes對應的頁數。
lowmem_pages=所有低端內存區域伙伴分配器管理的頁數總和。
高端內存區域最低水線=zone->managed_pages/1024。
低端內存區域最低水線=min_free_pages*zone->managed_pages/lowmem_pages。
計算低水線和高水線方法:
增量=(最低水線/4, managed_pageswatermark_scale_factor/10000) 取得最大值
低水線=最低水線+增量
高水線=最低水線+增量2
如果(最低水線/4)比較大,那么計算公式簡化為:
低水線=最低水線5/4
高水線=最低水線3/2
Buddy提供以page為單位的內存分配接口,這對內核來說顆粒度還太大,所以需要一種新的機制,將page拆分為更小的單位來管理。
Linux中支持的主要有:slab、slub、slob。其中slob分配器的總代碼量比較少,但分配速度不是最高效的,所以不是為大型系統設計,適合內存緊張的嵌入式系統。
slab分配器的作用不僅僅是分配小塊內存,更重要的作用是針對經常分配和釋放的對象充當緩存。slab分配器的核心思路是:為每種對象類型創建一個內存緩存,每個內存緩存由多個大塊組成,一個大塊是由一個或多個連續的物理頁,每個大塊包含多個對象。slab采用面向對象的思想,基于對象類型管理內存,每種對象被劃分為一類,比如進程描述符task_struct是一個類,每個進程描述符實例是一個對象。如下圖所示為內存緩存的組成結構: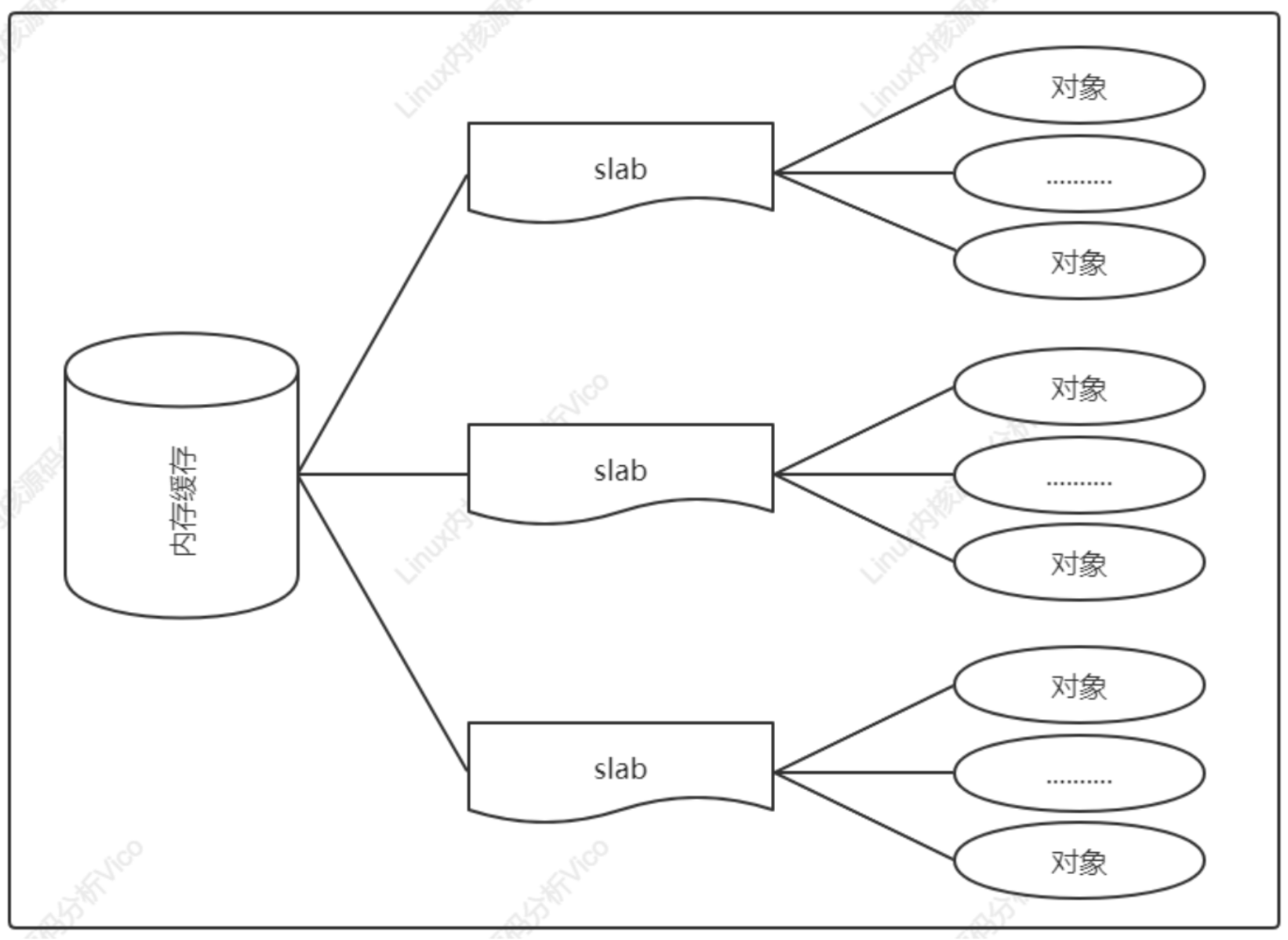
slab分配器在某些情況下表現不太優先,所以Linux內核提供兩個改進的塊分配器。
目前slub分配器已成為默認的塊分配器。
通用的內存緩存的編程接口如下:
a. 分配內存kmalloc;
kmalloc(size_t size,gfp_t flags)
b. 重新分配內存krealloc;
krealloc(const void *p,size_t new_size,gpf_t flags)
c. 釋放內存kfree;
kfree(const void *objp)
創建專用的內存緩存編程接口如下:
a. 創建內存緩存kmem_cache_create
b. 指定內存緩存分配kmem_cache_alloc
c. 釋放對象kmem_cache_free
d. 銷毀內存緩存keme_cache_destroy
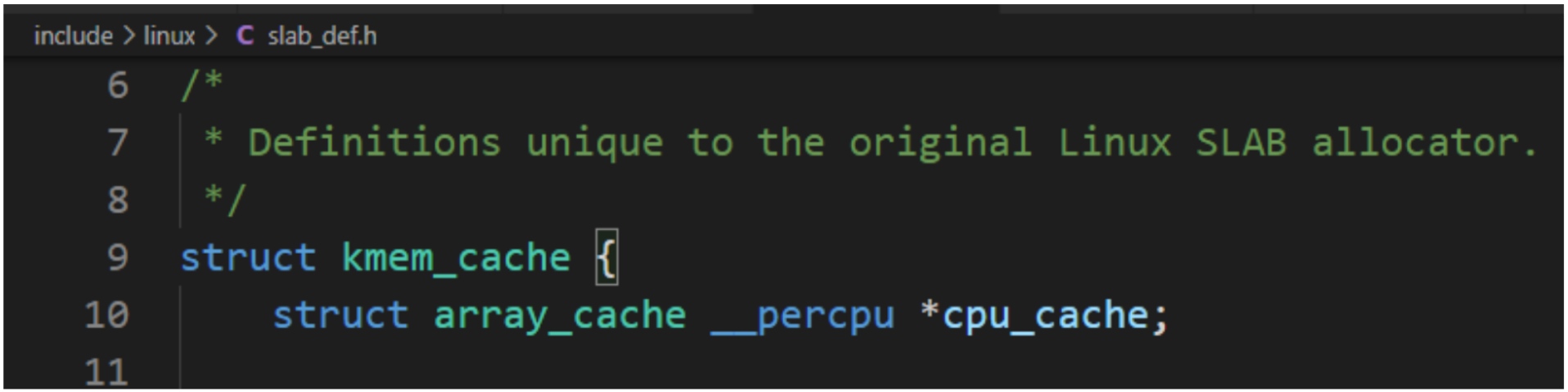
內存緩存的數據結構如下圖所示: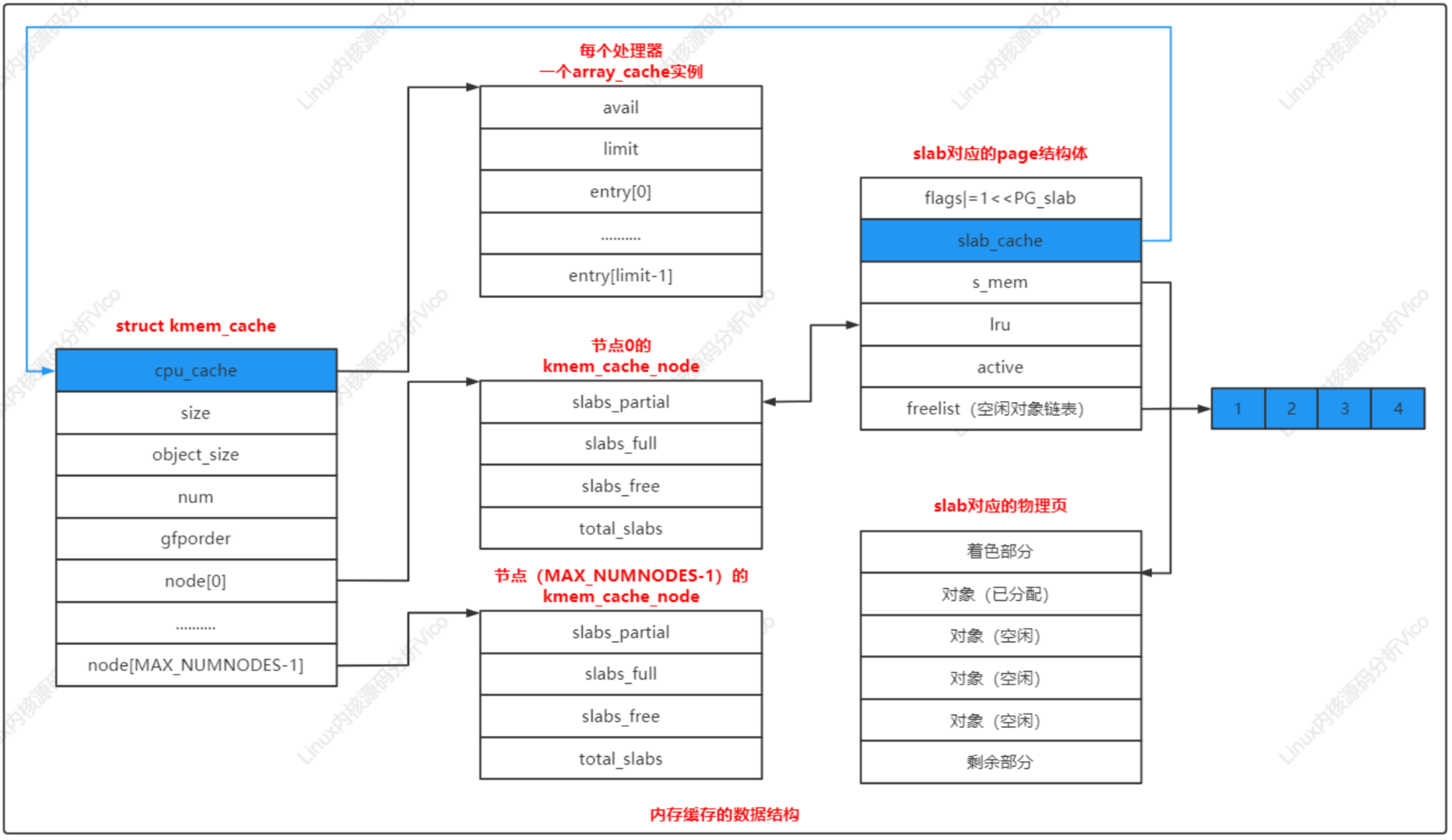
slab分配器 數據結構
a. 每一個內存緩存對應一個kmem_cache實例
b. 每一個內存節點對應一個kmem_cache_node實例
每個slab由一個或多個連續的物理頁組成,頁的階數是kmem_cache.gfporder,如果階數大于0,組成一個復合頁,slab被劃分為多個對象,大多數情況下slab長度不是對象長度的整數倍,slab有剩余部分,可以用來給slab進行著色。著色:把slab的第一個對象從slab的起始位置偏移一個數值,偏移值是處理器的一級緩存行長度的整數倍,不同slab的偏移值不同,使用不同slab的對象映射到處理器不同的緩存行。
a. 計算slab
函數calculate_slab_order負責計算slab長度,從0階到kmalloc()函數支持最大階數KMALLOC_MAX_ORDER。
如果階數大于或等于允許的最大slab階數,那么選擇這個階數,盡量選擇低的階數,因為申請高階頁塊成功的概率低。如果剩余長度小于或等于slab長度的1/8,那么選擇這個階數。slab_max_order:允許的最大slab階數,如果內存容量大于32MB,那么默認值是0,否則值為0,通過內核參數slab_max_order指定。
b.著色
slab是一個或多個連續的物理頁,起始地址總是頁長度的整數倍,不同slab中相同偏移的位置在處理器一級緩存中的索引相同。如果slab的剩余部分的長度超過一級緩存行的長度,剩余部分對應的一級緩存行沒有被利用;如果對象的填充字節的長度超過一級緩存行的長度,填充字節對應的一級緩存行沒有被利用。這兩種情況導致處理器的某些緩存行被過度使用,另一些緩存行很少使用。
內存緩存為每個處理器創建一個數組緩存(結構體array_cahce)。釋放對象時,把對象存放到當前處理器對應的數組緩存中;分配對象的時候,先從當前處理器的數組緩存分配對象,采用后進先出(Last In First Out,LIFO)的原則,這種做可以提高性能。
每處理器數組緩存:
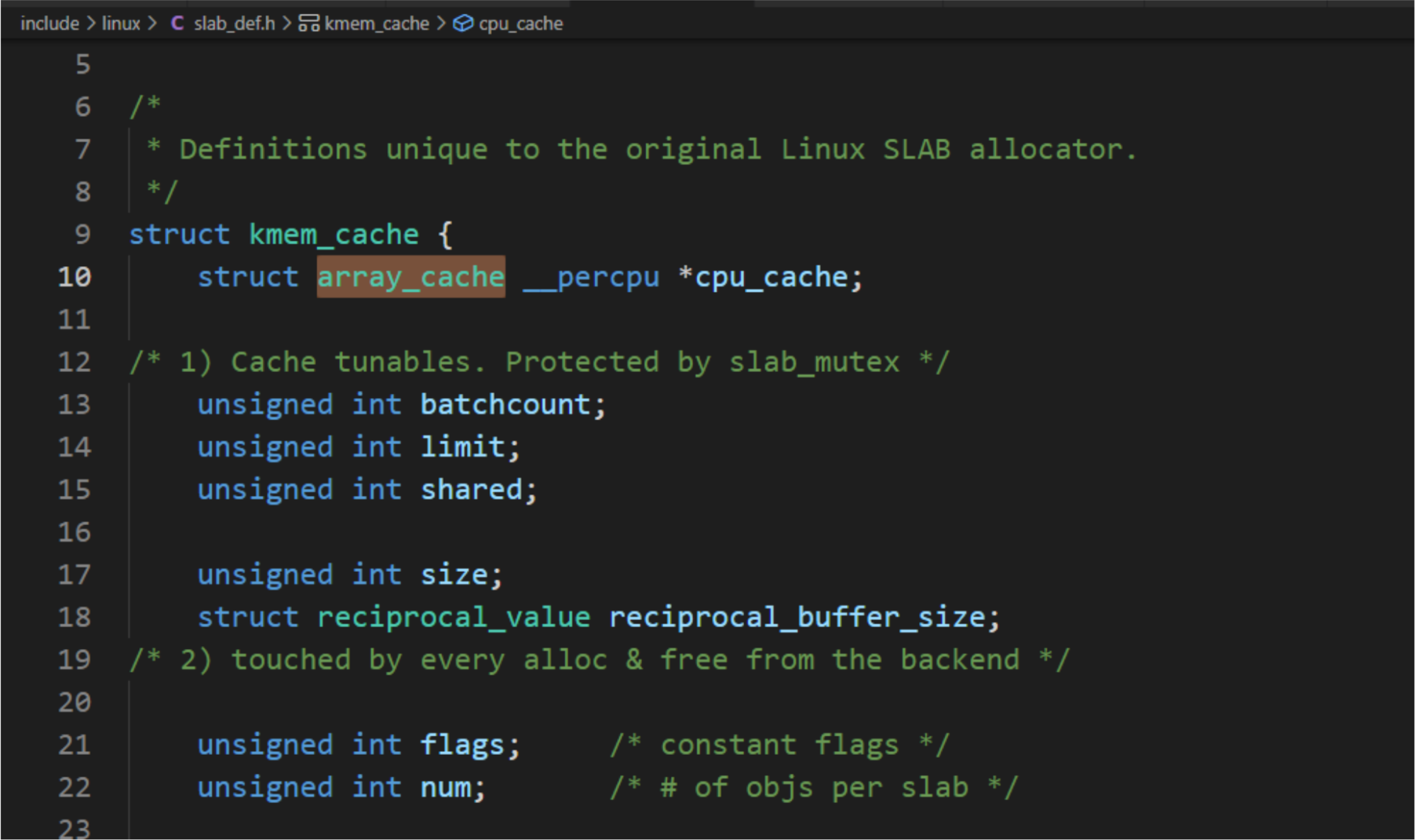
struct array_cache {unsigned int avail; //數組存放的對象的數量unsigned int limit; //數組的大小, 和結構體kmem_cache成員limit值相同, 根據對象長度猜測一個值unsigned int batchcount; //批量值, 和結構體kmem_cache成員batchcount值相同, 批量值是數組大小的一半unsigned int touched;void *entry[]; /** Must have this definition in here for the proper* alignment of array_cache. Also simplifies accessing* the entries.*/
};
內存緩存針對每個內存節點創建一個kmem_cache_node實例。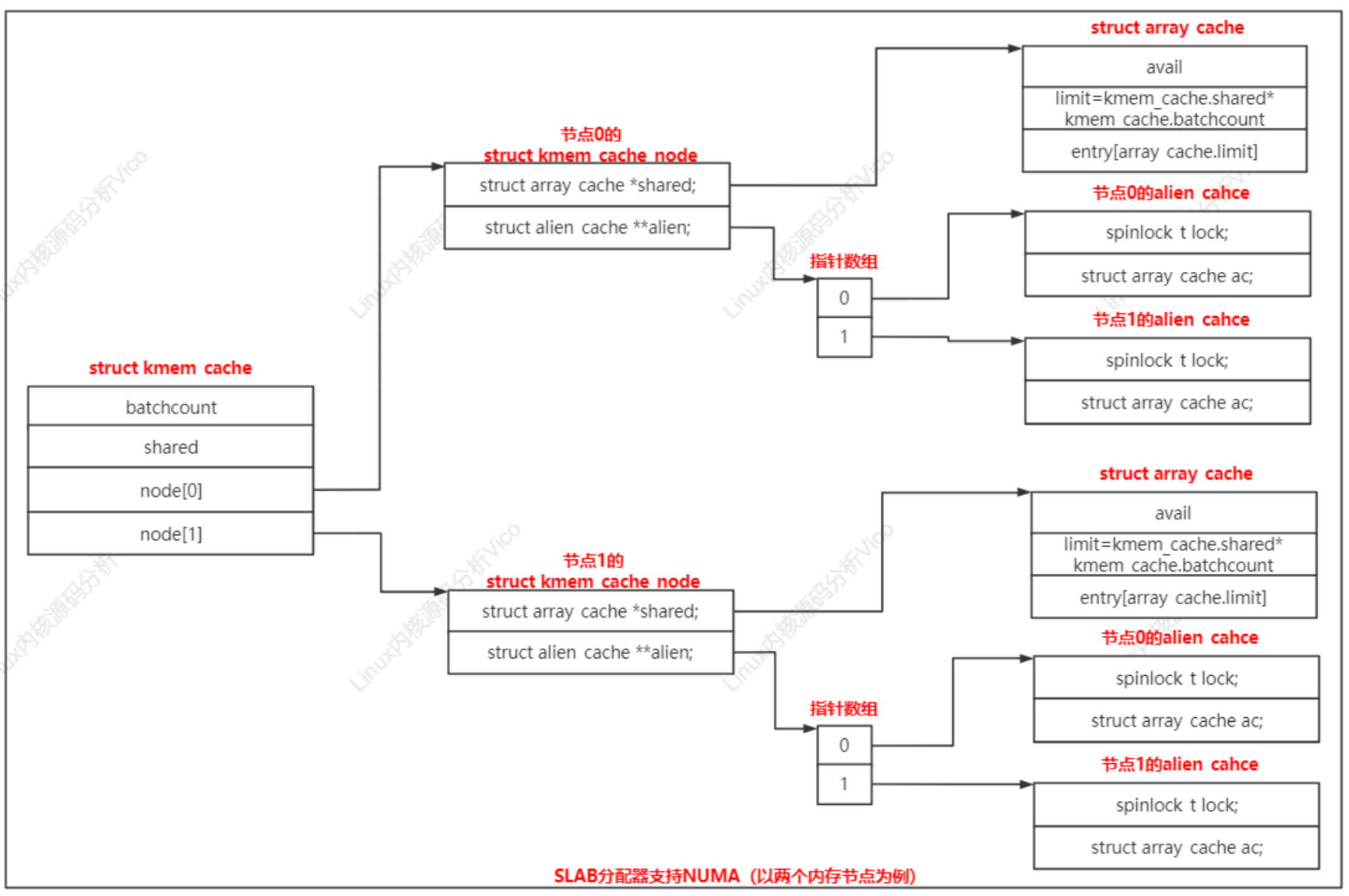
struct kmem_cache {......struct kmem_cache_node *node[MAX_NUMNODES];
};
kmem_cache_node實例的成員shared指向共享數組緩存,成員alien指向遠程節點數組緩存,每個節點一個遠程節點數組緩存。
分配和釋放本地內存節點的對象時,也會使用共享數組緩存
a. 申請分配對象時,如果當前處理器的數組緩存是空的,共享數組緩存里面的對象可以用來重填;
b. 釋放對象時,如果當前處理器的數組緩存是滿的,并且共享數組緩存有空閑空間,可以轉移一部分對象到共享數組緩存,不需要把對象批量還給slab,然后把正在釋放的對象添加到當前處理器的數組緩存中。
對于所有對象空閑的slab,沒有立即釋放,而是放在空閑slab鏈表中。只有內存節點上空閑對象的數量超過限制,才開始回收空閑slab,直到空閑對象的數量小于或等于限制。
結構體kmem_cache_node的成員slabs_free是空閑slab鏈表的頭節點,成員free_objects是空閑對象的數量,成員free_limit是空閑對象的數量限制。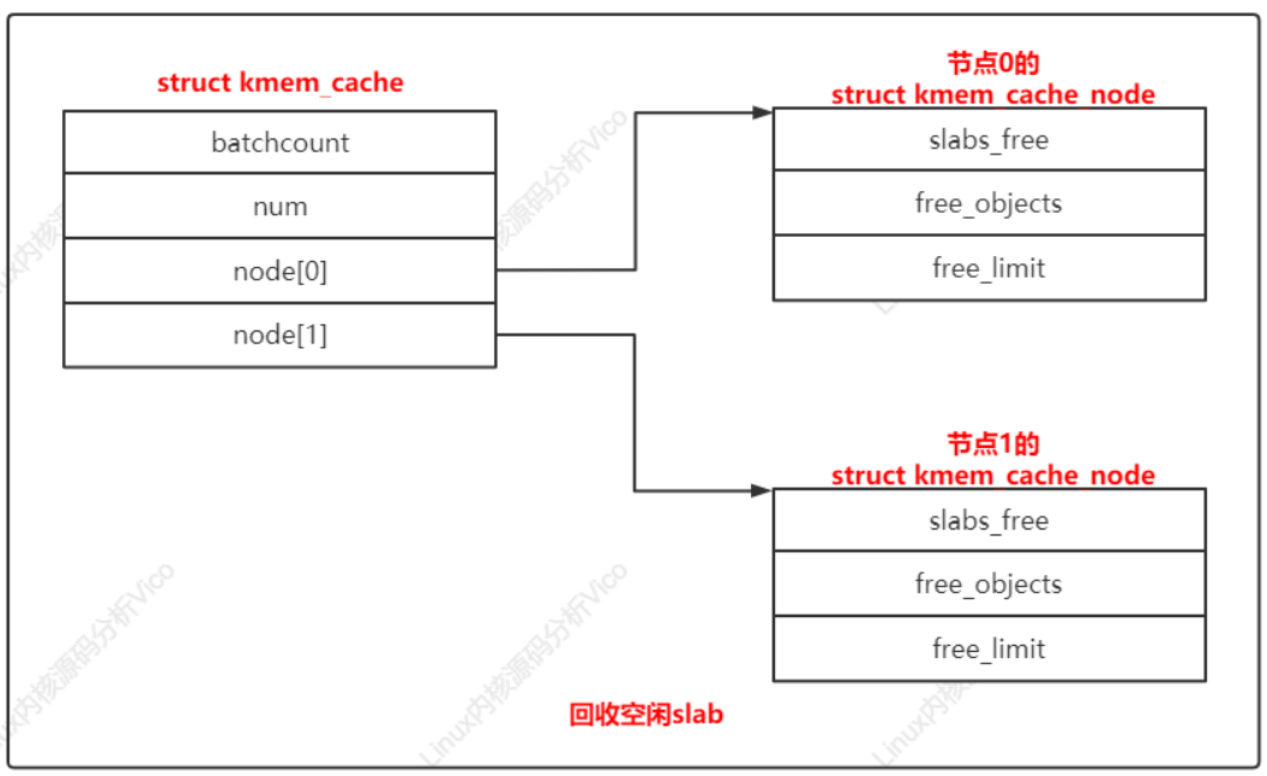
節點x的空閑對象的數量限制=(1+節點的處理器數量)*keme_cache.batchcount+kmem_cache.num
每個處理器每隔2秒針對每個內存緩存執行
a. 回收節點x對應的遠程節點數組緩存中的對象
b. 如果過去2秒沒有從當前處理器的數組緩存分配對象,那么回收數組緩存中的對象。
當設備長時間運行后,內存碎片化,很難找到連續的物理頁。在這種情況下,如果需要分配長度超過一頁的內存塊,可以使用不連續頁分配器,分配虛擬地址連續但是物理地址不連續的內存塊。在32位系統中不連續分配器還有一個好處:優先從高端內存區域分配頁,保留稀缺的低端內存區域。
不連續頁分配器的數據結構關系如下: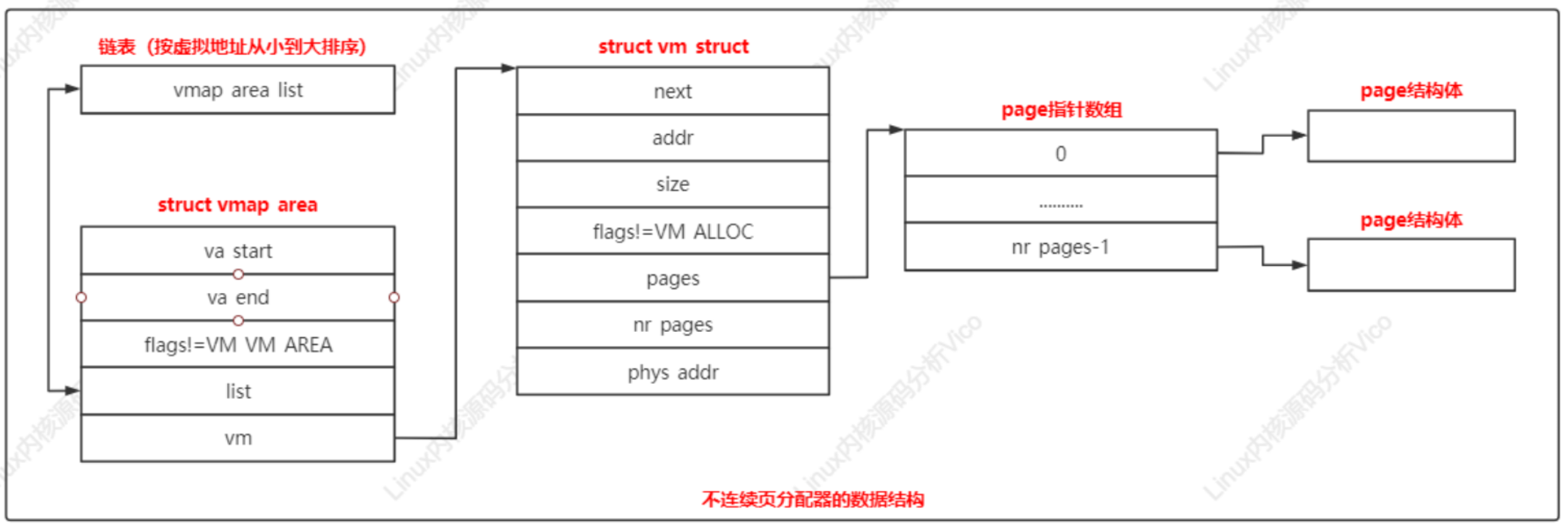

每個虛擬內存區域對應一個vmap_area實例;
每個vmap_area實例關聯一個vm_struct實例;
vmalloc虛擬地址空間的范圍是(VMALLOC_START,VMALLOC_END),每種處理器架構都需要定義這兩個宏。如ARM64架構定義宏如下:
vmalloc函數執行過程:
a.分配虛擬內存區域
b.分配物理頁
c.在內核的頁表中把虛擬頁映射到物理頁
內存映射是在進程的虛擬地址空間中創建一個映射,可為分兩種:
通常把文件映射的物理頁稱為文件頁,把匿名映射的物理頁稱為匿名頁。
【內存映射原理】
a. 創建內存映射的時候,在進程的用戶虛擬地址空間中分配一個虛擬內存區域。
b. Linux內核采用延遲分配物理內存的策略,在進程第一次訪問虛擬頁的時候,產生缺頁異常。如果是文件映射,那么分配物理頁,把文件指定區間的數據講到物理頁中,然后在頁表中把虛擬頁映射到物理頁;如果是匿名映射,那么分配物理頁,然后在頁表中把虛擬頁映射到物理頁。
根據修改是否其他進程可見和是否傳遞到底層文件,內存映射分為共享映射和私有映射:
共享映射:修改數據時映射相同區域的其他進程可以看見,如果是文件支持的映射,修改會傳遞到底層文件;
私有映射:第一次修改數據時會從數據源復制一個副本,然后修改副本,其他進程看不見,不影響數據源;
兩個進程可以使用共享的文件映射實現共享內存。匿名映射通常是私有映射,共享的匿名映射只有出現在父進程和子進程之間。在進程的虛擬地址空間中,代碼段和數據段是私有的文件映射,未初始化數據段、堆棧是私有的匿名映射。
內存管理子系統提供系統調用:
在內核空間中可以使用兩個函數:
1、系統調用mmap():進程創建匿名的內存映射,把內存的物理頁映射到進程的虛擬地址空間;進程把文件映射到進程的虛擬地址空間,可以像訪問內核一樣訪問文件,不需要調用系統調用read()/write()訪問文件 ,從頁避免用戶模式和內核模式之間的切換,提高讀寫文件速度。兩個進程針對同一個文件 創建共享的內存映射,達到共享內存。調用此函數成功:返回虛擬地址,否則返回負的錯誤號。
#include <sys/mman.h> void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);
addr:起始虛擬地址,如果addr為0,內核選擇虛擬地址,否則內核把這個參數作為提示,在附近選擇虛擬地址;
length: 映射的長度,單位是字節;
prot:保護位PROT_EXEC(頁可執行) PROT_READ(頁可讀) PROT_WRITE(頁可寫) PROT_NONE(頁不可訪問)
flags:標志MAP_SHARED(共享映射)MAP_PRIVATE(私有映射)MAP_ANONYMOUS(匿名映射)MAP_FIXED(固定映射)MAP_LOCKED(把頁鎖在內存中)MAP_POPULATE(填充頁表,即分配并且映射到物理頁,如果是文件映射,該標志導致預讀文件 )
fd:文件描述符:僅當創建文件映射的時候,此參數才有意義。
offset:偏移,單位是字節,必須是頁長度的整數倍。int munmap(void *addr, size_t length);
2、系統調用mprotect():用來設置虛擬內存區域的訪問權限。
#include <sys/mman.h> int mprotect(void *addr, size_t len, int prot);
addr:起始虛擬地址,必須是頁長度的整數倍
len:虛擬內存區域的長度,單位是字節
prot:保護位PROT_NONE:頁不可以訪問PROT_READ:頁可讀PROT_WRITE:頁可寫PROT_EXEC:頁可執行
調用此函數:如果成功返回0,否則返回負的錯誤號。
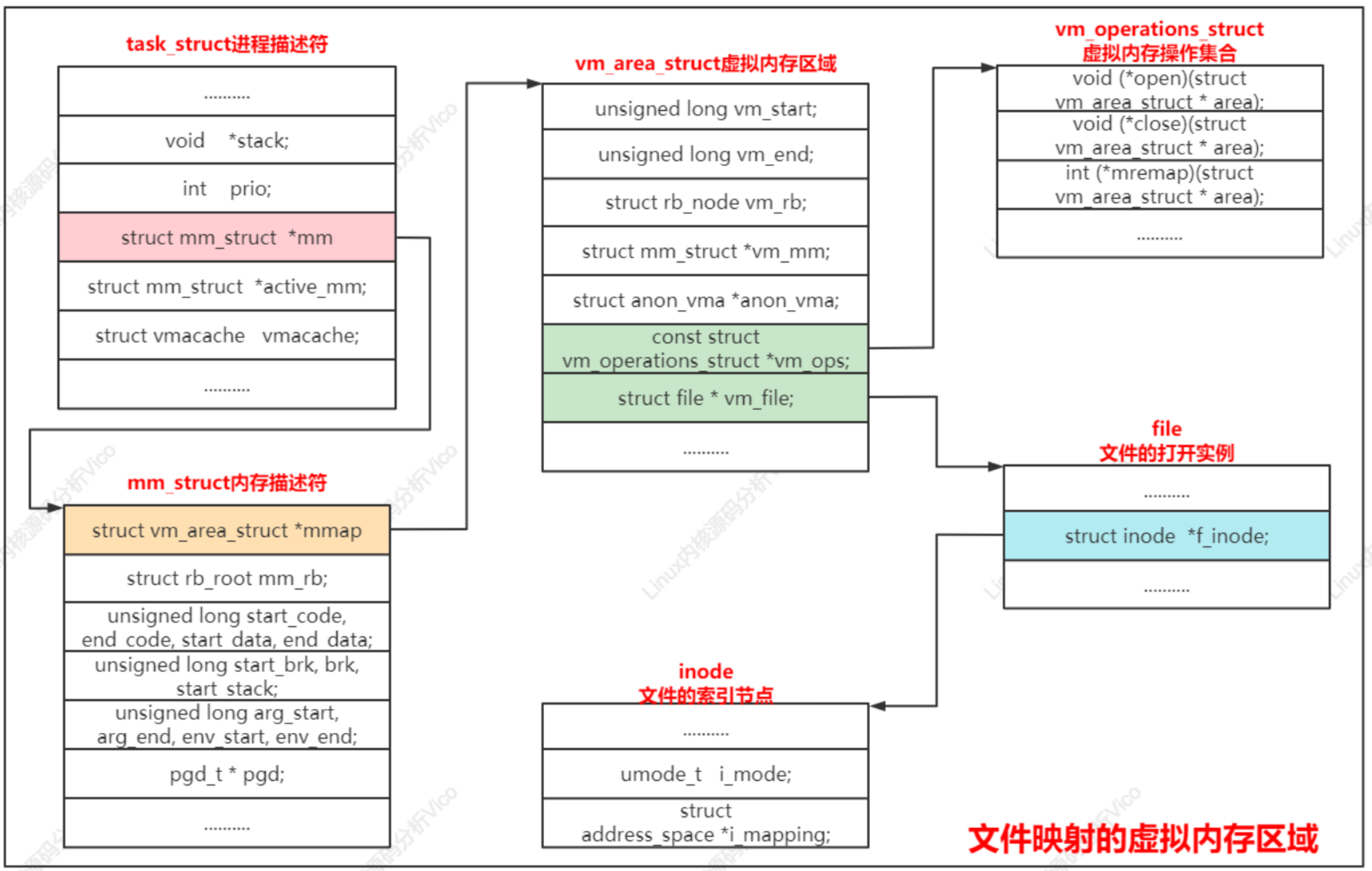
虛擬內存區域是分配給進程的一個虛擬地址范圍,內核使用結構體vm_area_struct描述虛擬內存區域。具體內核源碼如下:
//虛擬內存區域結構體類型
struct vm_area_struct {/* The first cache line has the info for VMA tree walking. */unsigned long vm_start; /* Our start address within vm_mm. */ //起始地址unsigned long vm_end; /* The first byte after our end address_space-//結束地址within vm_mm. *//* linked list of VM areas per task, sorted by address */// 虛擬內存區域鏈表, 按起始地址排序struct vm_area_struct *vm_next, *vm_prev;struct rb_node vm_rb; //紅黑樹節點/** Largest free memory gap in bytes to the left of this VMA.* Either between this VMA and vma->vm_prev, or between one of the* VMAs below us in the VMA rbtree and its ->vm_prev. This helps* get_unmapped_area find a free area of the right size.*/unsigned long rb_subtree_gap;/* Second cache line starts here. */struct mm_struct *vm_mm; /* The address space we belong to. */ //指向內存描述符, 即虛擬內存區域所屬的用戶虛擬地址空間pgprot_t vm_page_prot; /* Access permissions of this VMA. */ //保護位, 即訪問權限unsigned long vm_flags; /* Flags, see mm.h. */ //標志/** For areas with an address space and backing store,* linkage into the address_space->i_mmap interval tree.*/// 為了支持查詢一個文件區間被映射到哪些虛擬內存區域, 把一個文件映射到的所有虛擬內存區域加入到該文件的地址空間結構體address_space的成員i_mmap指向的區間樹struct {struct rb_node rb;unsigned long rb_subtree_last;} shared;/** A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma* list, after a COW of one of the file pages. A MAP_SHARED vma* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack* or brk vma (with NULL file) can only be in an anon_vma list.*/// 把虛擬內存區域關聯的所有anon_vma實例串聯起來, 一個虛擬內存區域會關聯到父進程的anon_vma實例和自己自己的anon_vma實例struct list_head anon_vma_chain; /* Serialized by mmap_sem & * page_table_lock */struct anon_vma *anon_vma; /* Serialized by page_table_lock */ //指向一個anon_vma實例, 結構體anon_vma用來組織匿名頁被映射到的所有虛擬地址空間。/* Function pointers to deal with this struct. */const struct vm_operations_struct *vm_ops; //虛擬內存操作集合/* Information about our backing store: */// 文件偏移, 單位為頁unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZEunits */struct file * vm_file; /* File we map to (can be NULL). */ //文件, 如果是私有的匿名映射, 成員是空指針void * vm_private_data; /* was vm_pte (shared mem) */#ifndef CONFIG_MMUstruct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMAstruct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endifstruct vm_userfaultfd_ctx vm_userfaultfd_ctx;
};
虛擬內存區域的標志:結構體vm_area_struct成員vm_flags存放虛擬內存區域的標志:
C標準庫封裝函數mmap用來創建內存映射,內核提供POSIX標準定義系統調用mmap。系統調用執行流程:

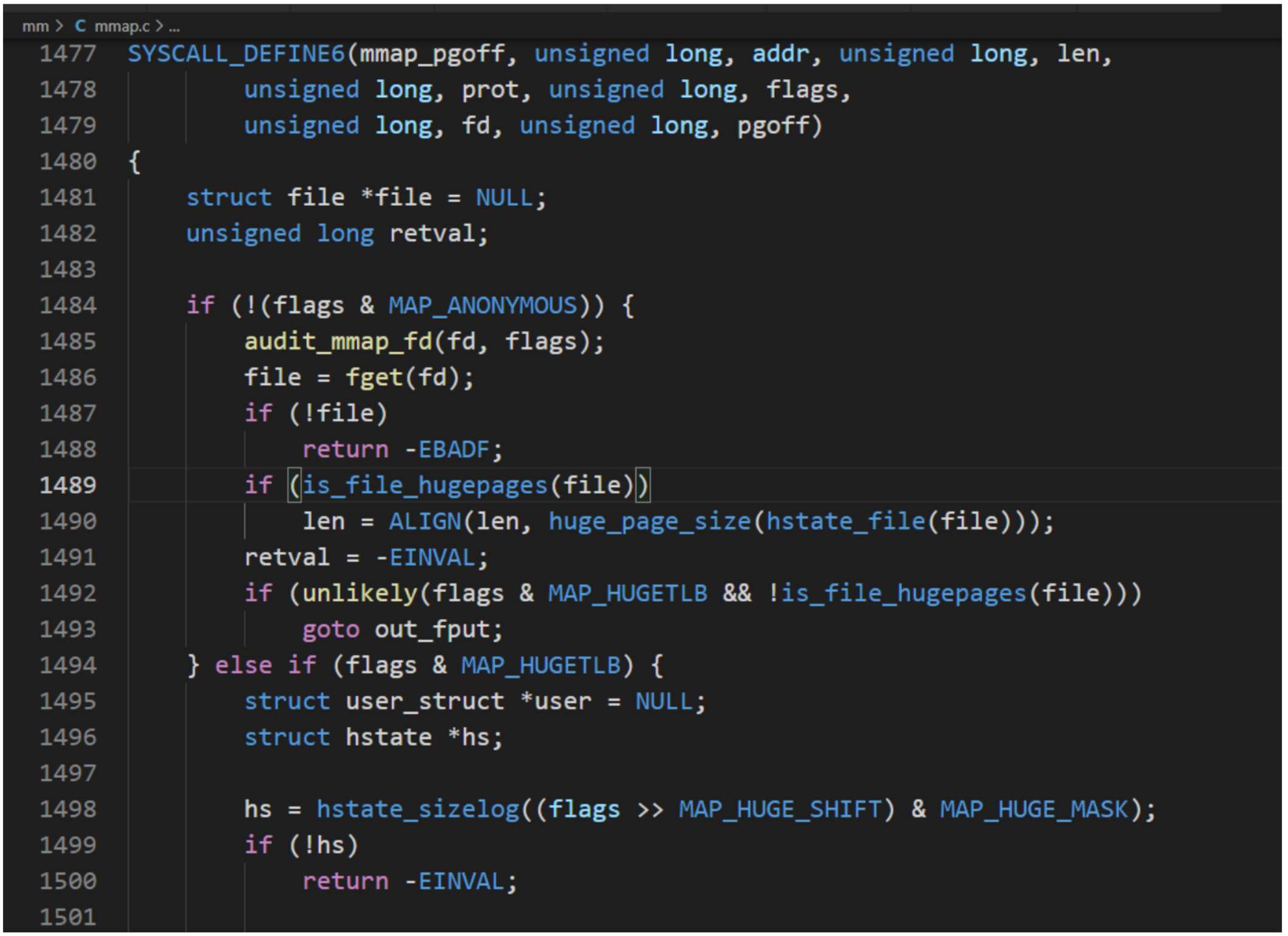
函數sys_mmap_pgoff和函數do_mmap執行流程如下: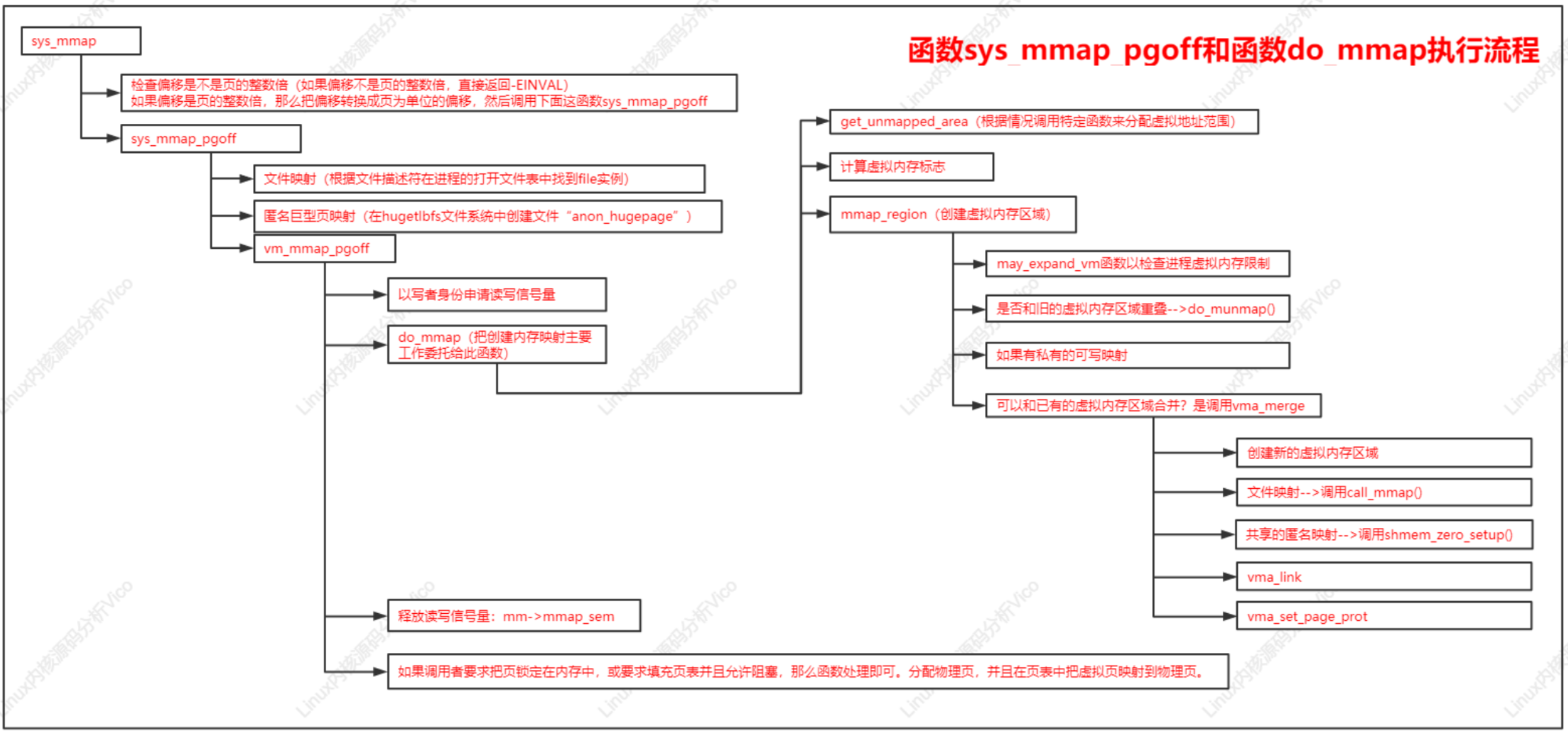
系統調用munmap用來刪除內存映射,它有兩個參數:起始地址和長度。系統調用munmap的執行流程,主要把工作委托給源文件“mm/mmap.c"中的函數do_munmap。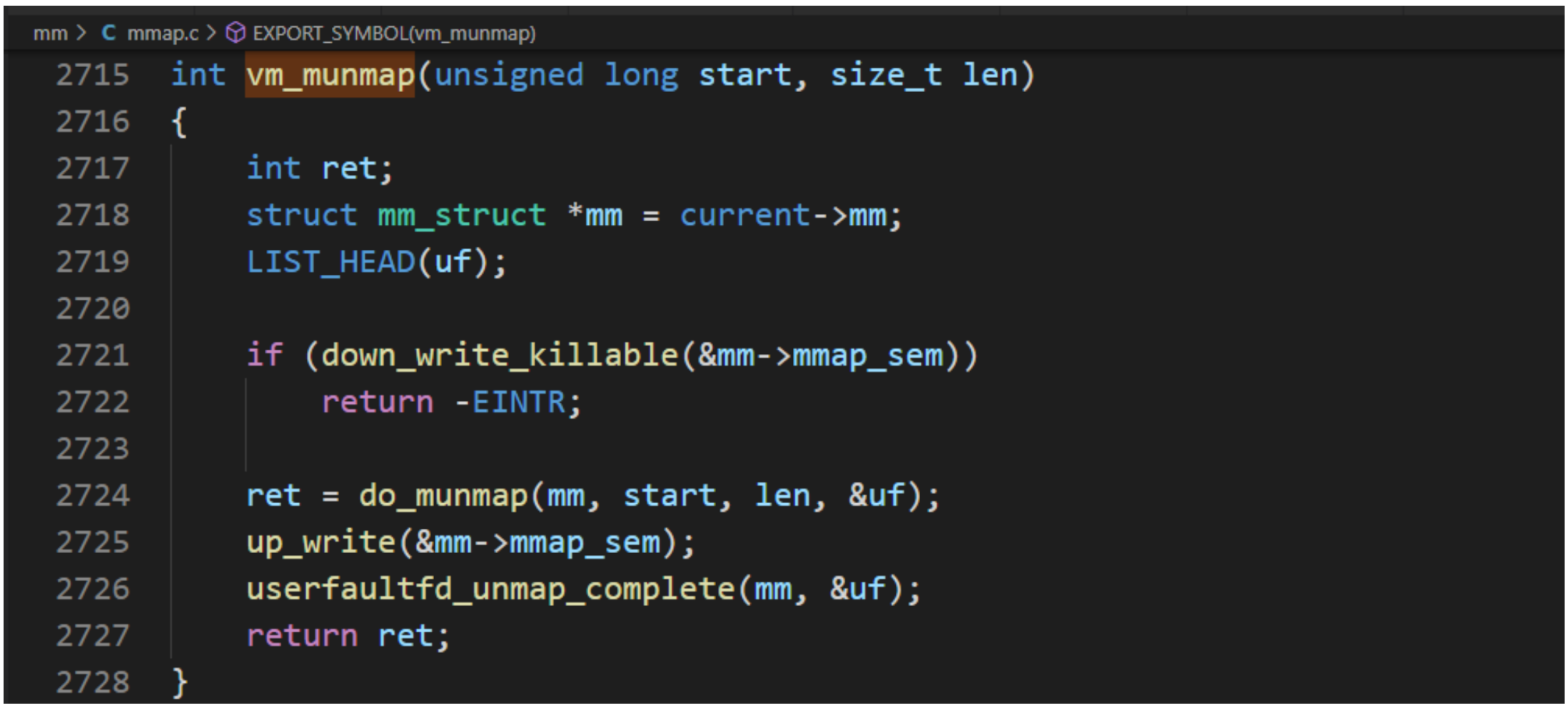
系統調用munmap執行流程如下: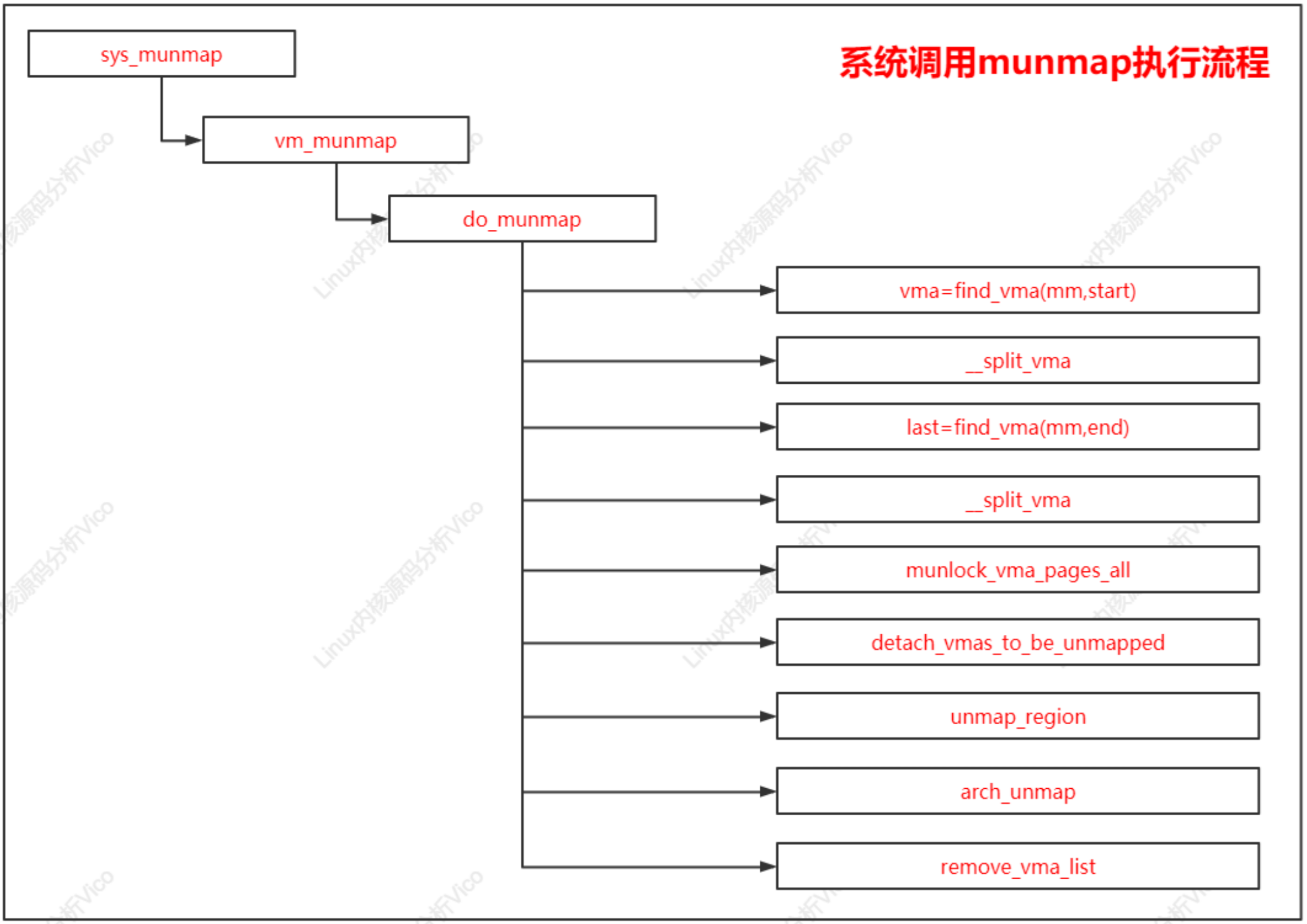
非一致內存訪問(Non-Uniform Memory Access,NUMA):指內存被劃分成多個內存節點的多處理器系統,訪問一個內存節點花費的時間取決于處理器和內存節點的距離。
對稱多處理器(Symmetric Multi-Processor, SMP):即一致內存訪問(Uniform Memory Access,UMA),所有處理器訪問內存花費的時間是相同的。
在實際應用中可以采用混合體系結構,在NUMA節點內部使用SMP體系。
內存模型是從處理器的角度看到的物理內存分布情況,內核管理不同內存模型的方式存在差異。內存管理子系統支持3種內存模型:
什么情況下會出現內存的物理地址空間存在空洞?
如果內存的物理地址空間存在空洞,應該選擇那種內存模型?
內存管理子系統使用節點(node)、區域(zone)和頁(page)三級結構描述物理內存。
內存節點被劃分為內存區域,內核定義區域類型如下:
enum zone_type {
#ifdef CONFIG_ZONE_DMA/** ZONE_DMA is used when there are devices that are not able* to do DMA to all of addressable memory (ZONE_NORMAL). Then we* carve out the portion of memory that is needed for these devices.* The range is arch specific.** Some examples** Architecture Limit* ---------------------------* parisc, ia64, sparc <4G* s390 <2G* arm Various* alpha Unlimited or 0-16MB.** i386, x86_64 and multiple other arches* <16M.*/ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32/** x86_64 needs two ZONE_DMAs because it supports devices that are* only able to do DMA to the lower 16M but also 32 bit devices that* can only do DMA areas below 4G.*/ZONE_DMA32,
#endif
每個內存區域用一個zone結構體描述,其內核源碼如下:
struct zone {/* Read-mostly fields *//* 區域水線,使用宏訪問 */unsigned long watermark[NR_WMARK]; // 頁分配器使用水線unsigned long nr_reserved_highatomic;// 頁分配器使用,當前區域保留多少頁不能借給高的區域類型long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMAint node;
#endif
// 指向內存節點的pglist_data實例struct pglist_data *zone_pgdat;
// 每處理器集合struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM/** Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section*/unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM *//* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */unsigned long zone_start_pfn; // 當前區域的起始物理頁號unsigned long managed_pages; // 伙伴分配器管理 的物理頁的數量unsigned long spanned_pages; // 當前區域跨越的總頁數,包括空洞unsigned long present_pages; // 當前區域存在的物理頁的數量,不包括空洞const char *name; // 區域名稱
#ifdef CONFIG_MEMORY_ISOLATION/** Number of isolated pageblock. It is used to solve incorrect* freepage counting problem due to racy retrieving migratetype* of pageblock. Protected by zone->lock.*/unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG/* see spanned/present_pages for more description */seqlock_t span_seqlock;
#endifint initialized;/* Write-intensive fields used from the page allocator */ZONE_PADDING(_pad1_)/* free areas of different sizes */// MAX_ORDER最大除數,實際上是可分配的最大除數加1,默認值是11,// 意味伙伴分配器一次最多可分配2的10次方頁struct free_area free_area[MAX_ORDER]; // 不同長度的空閑區域/* zone flags, see below */unsigned long flags;/* Primarily protects free_area */spinlock_t lock;/* Write-intensive fields used by compaction and vmstats. */ZONE_PADDING(_pad2_)/** When free pages are below this point, additional steps are taken* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached*/unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA/* pfn where compaction free scanner should start */unsigned long compact_cached_free_pfn;/* pfn where async and sync compaction migration scanner should start */unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION/** On compaction failure, 1<<compact_defer_shift compactions* are skipped before trying again. The number attempted since* last failure is tracked with compact_considered.*/unsigned int compact_considered;unsigned int compact_defer_shift;int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA/* Set to true when the PG_migrate_skip bits should be cleared */bool compact_blockskip_flush;
#endifbool contiguous;ZONE_PADDING(_pad3_)/* Zone statistics */atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;
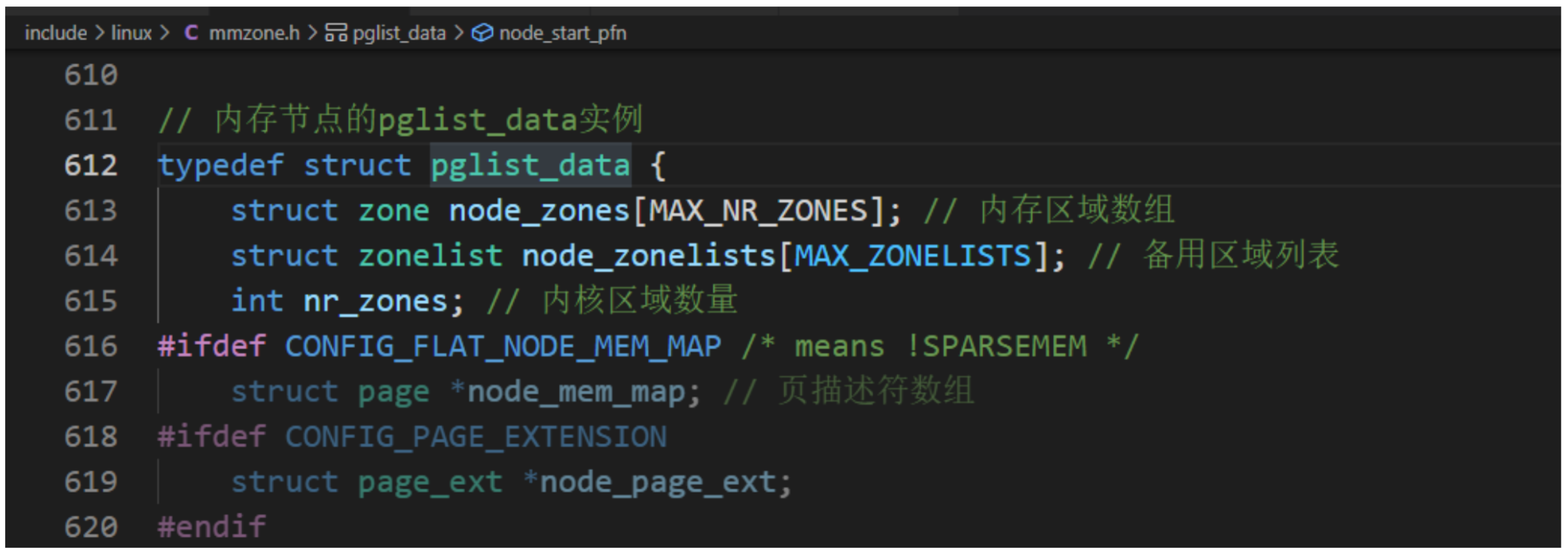
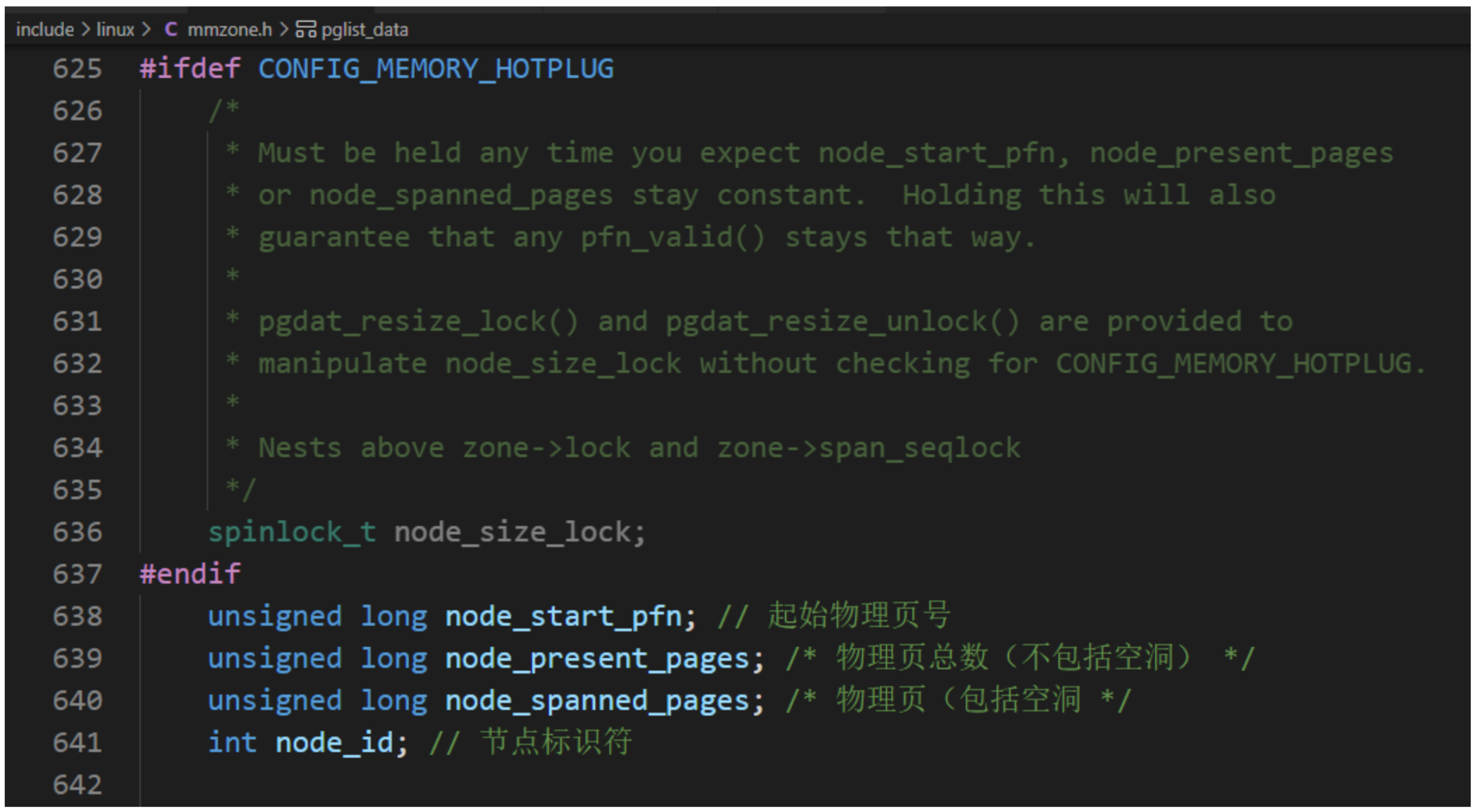
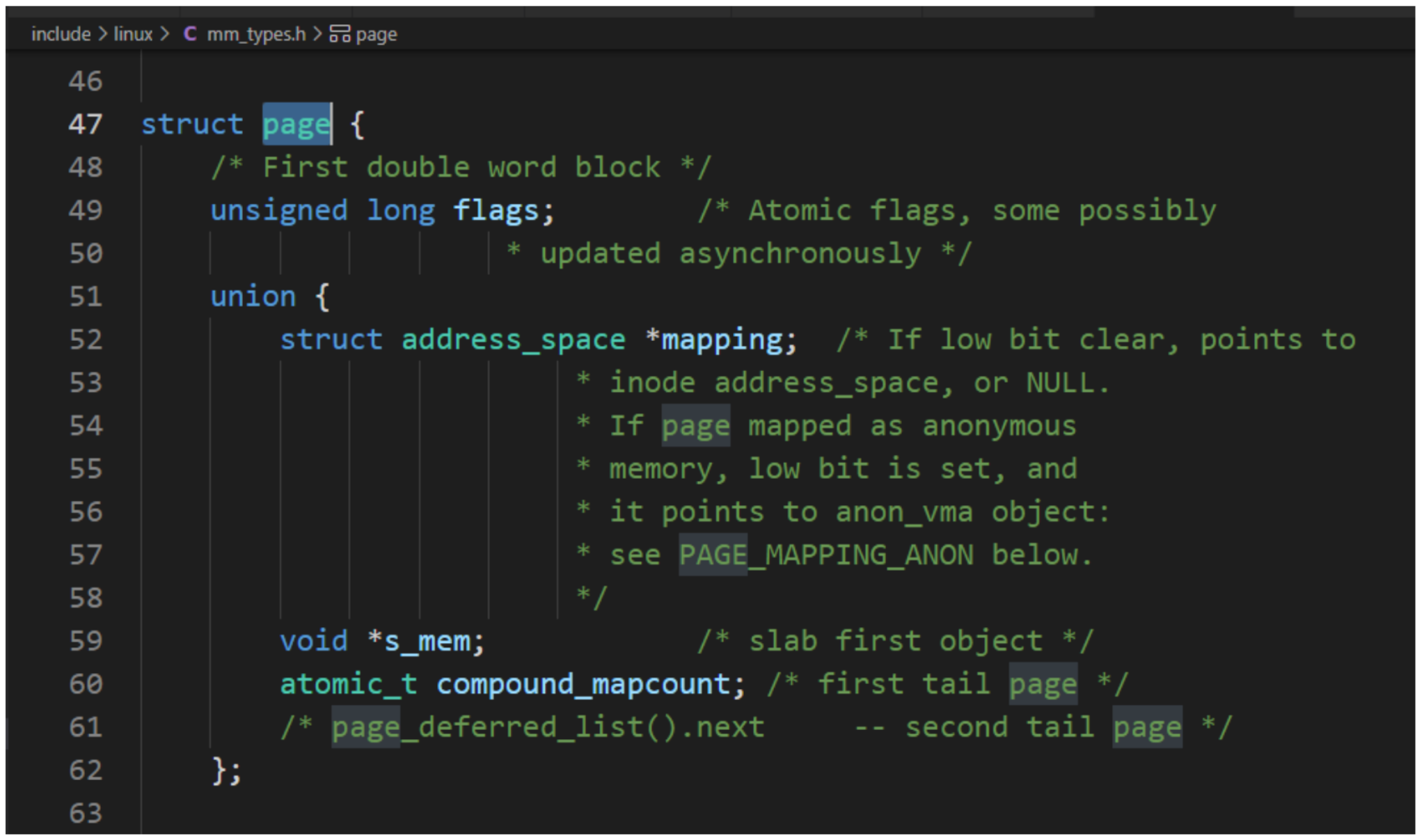
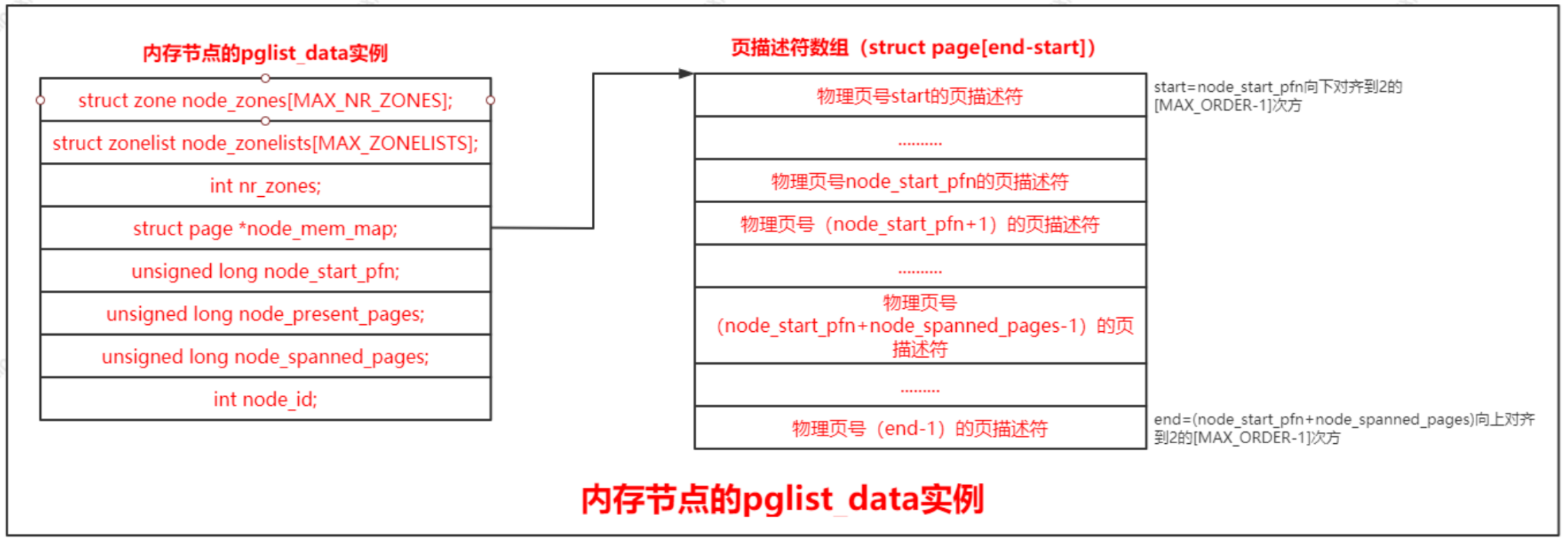
每個物理頁對應一個page結構體,稱為頁描述符,內存節點的pglist_data實例的成員node_mem_map指向該內存節點包含的所有物理頁的頁描述符組成的數據。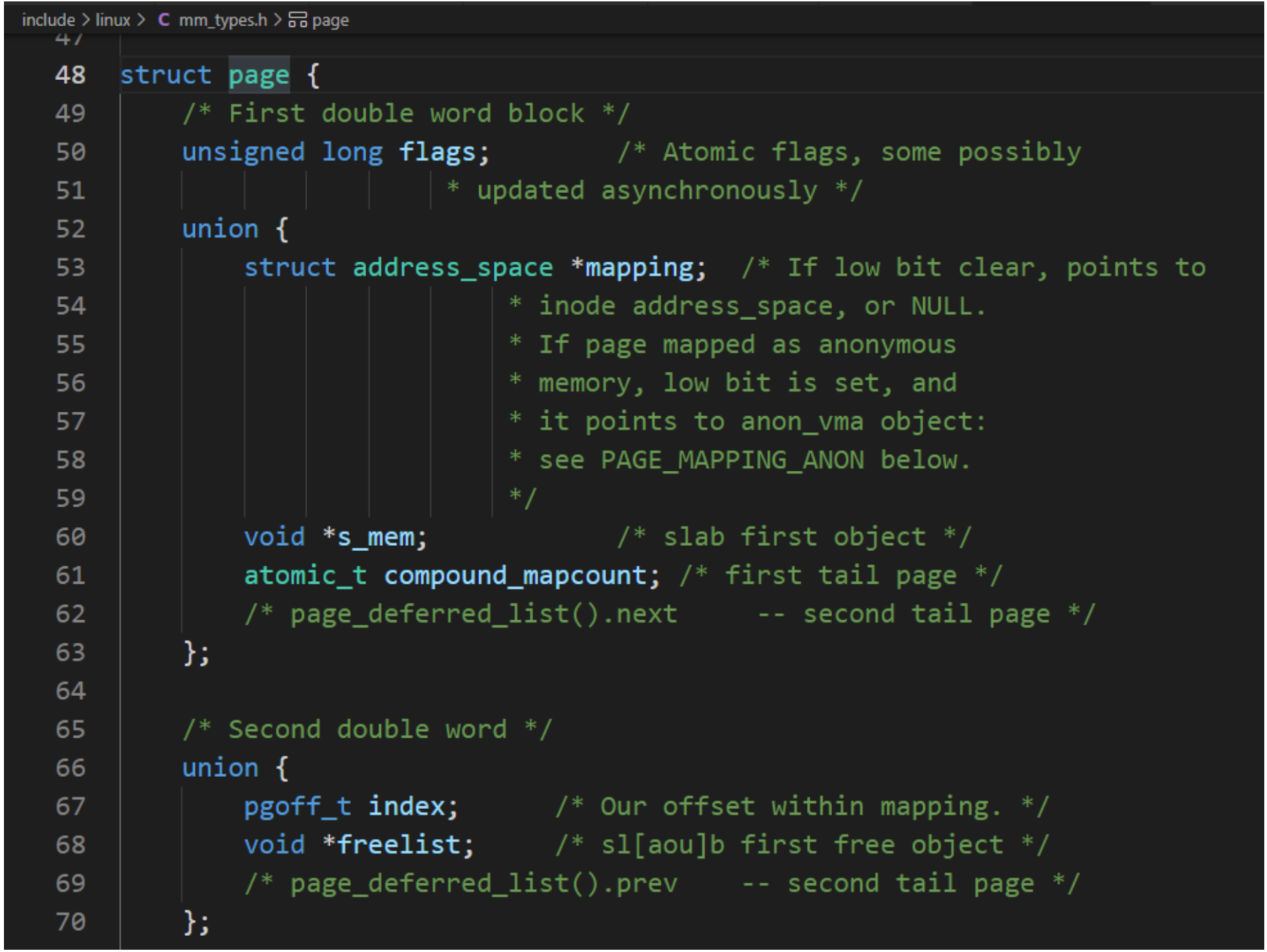
因物理頁的數量很大,所以在page結構體中增加1成員,可能導致所有page實例占用的內存大幅度增加。為了減少內存消耗,內核努力使page結構體盡可能小,對于不會同時生效的成員,使用聯合體,這種做法帶來的負面影響是page結構體的可讀性差。
1、kmalloc():用于申請較小的、連續的物理內存;
void * kmalloc (size_t size, gfp_t flags);
2、vmalloc():用于申請較大的內存空間,虛擬內存是連續的。
void *vmalloc(unsigned long size);
首先掌握管理資源的數據結構和函數。
Linux 提供了一個通用構架,用于在內存中構建數據結構。這些結構描述了系統中可用的資源,使得內核代碼能夠管理和分配資源。注意,其中關鍵的數據結構是resource,定義如下:
樹型結構中的資源管理如下: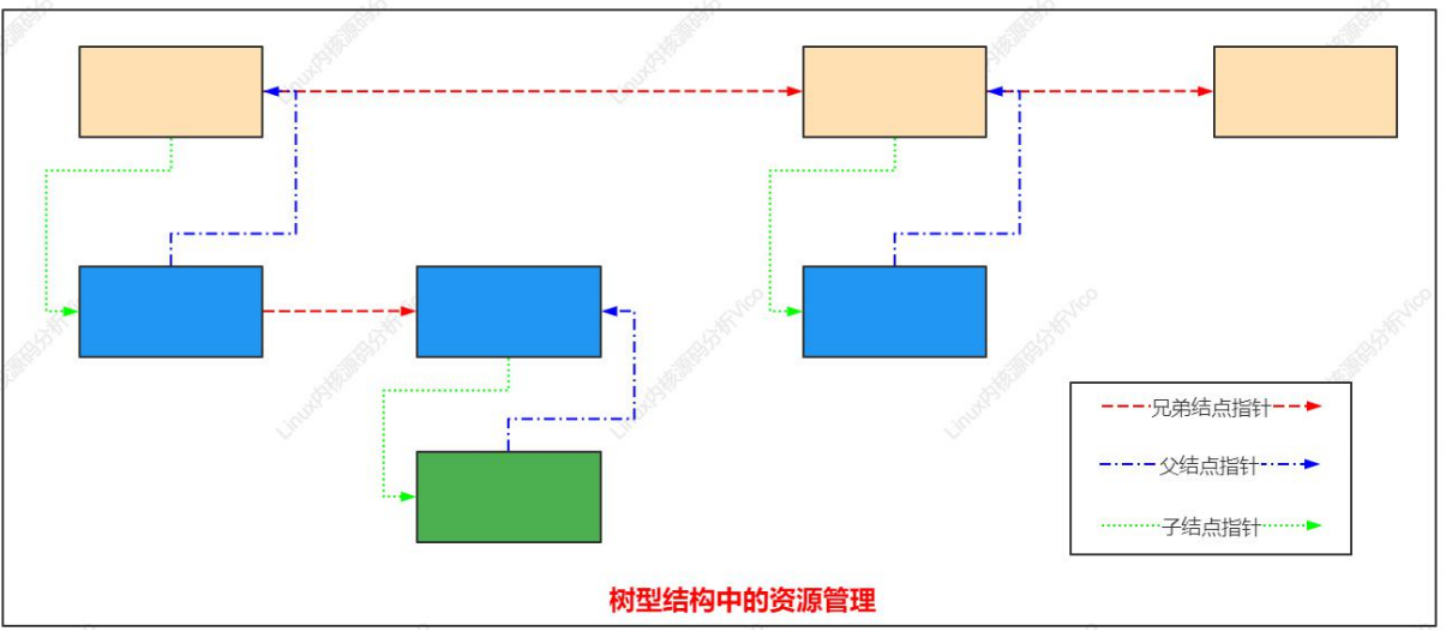
用于連接parent、child、sibling成員的規則:
為確保可靠地配置資源(無論何種類型),內核必須提供一種機制來分配和釋放資源。一旦資源已經分配,則不能由任何其他驅動程序使用。請求和釋放資源,無非是從資源樹中添加和刪除項而已。
**請求資源 **
內核提供了__request_resource 函數,用于請求一個資源區域。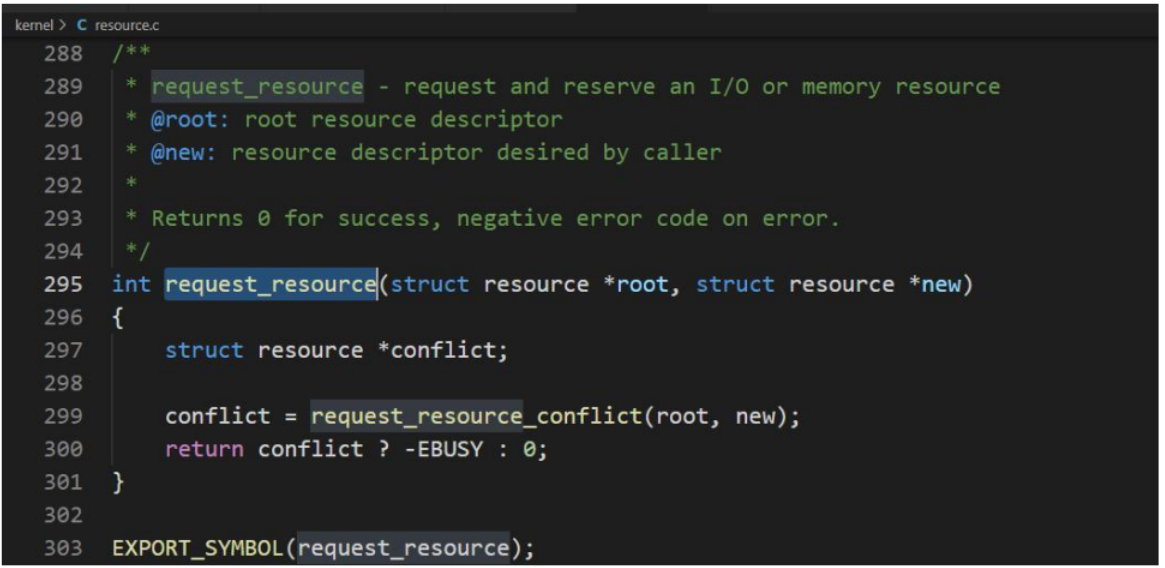
**釋放資源 **
調用 release_resource 函數釋放使用中的資源。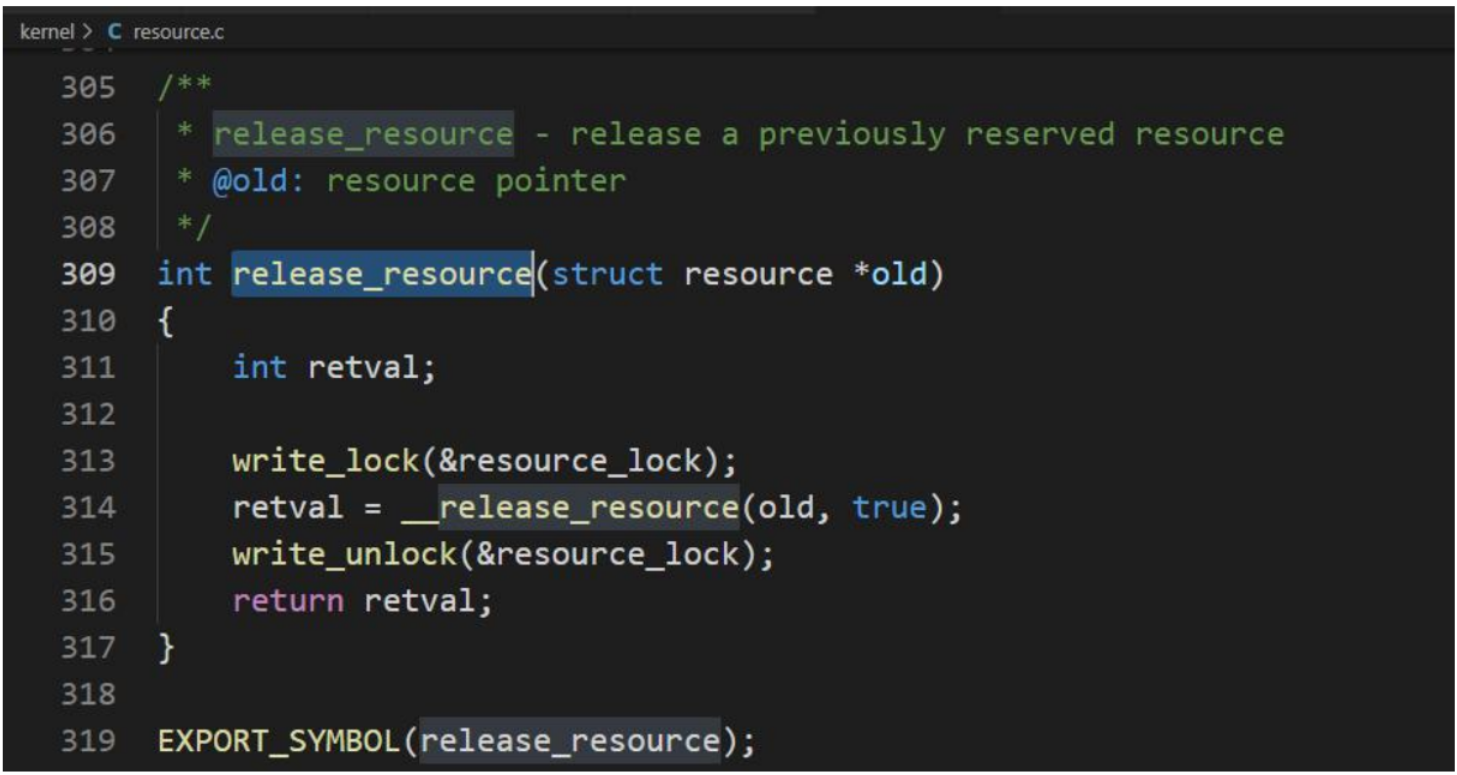
在給出 BIO 的準確定義之前,最好先討論其原理,如下圖所示。BIO 的主要管理結構(bio)關聯到一個向量(即數組),各個數組項都指向一個內存頁(切記:不是頁在內存中的地址,而是對應于該頁幀的 page實例)。這些頁用于從設備接收數據、向設備發送數據。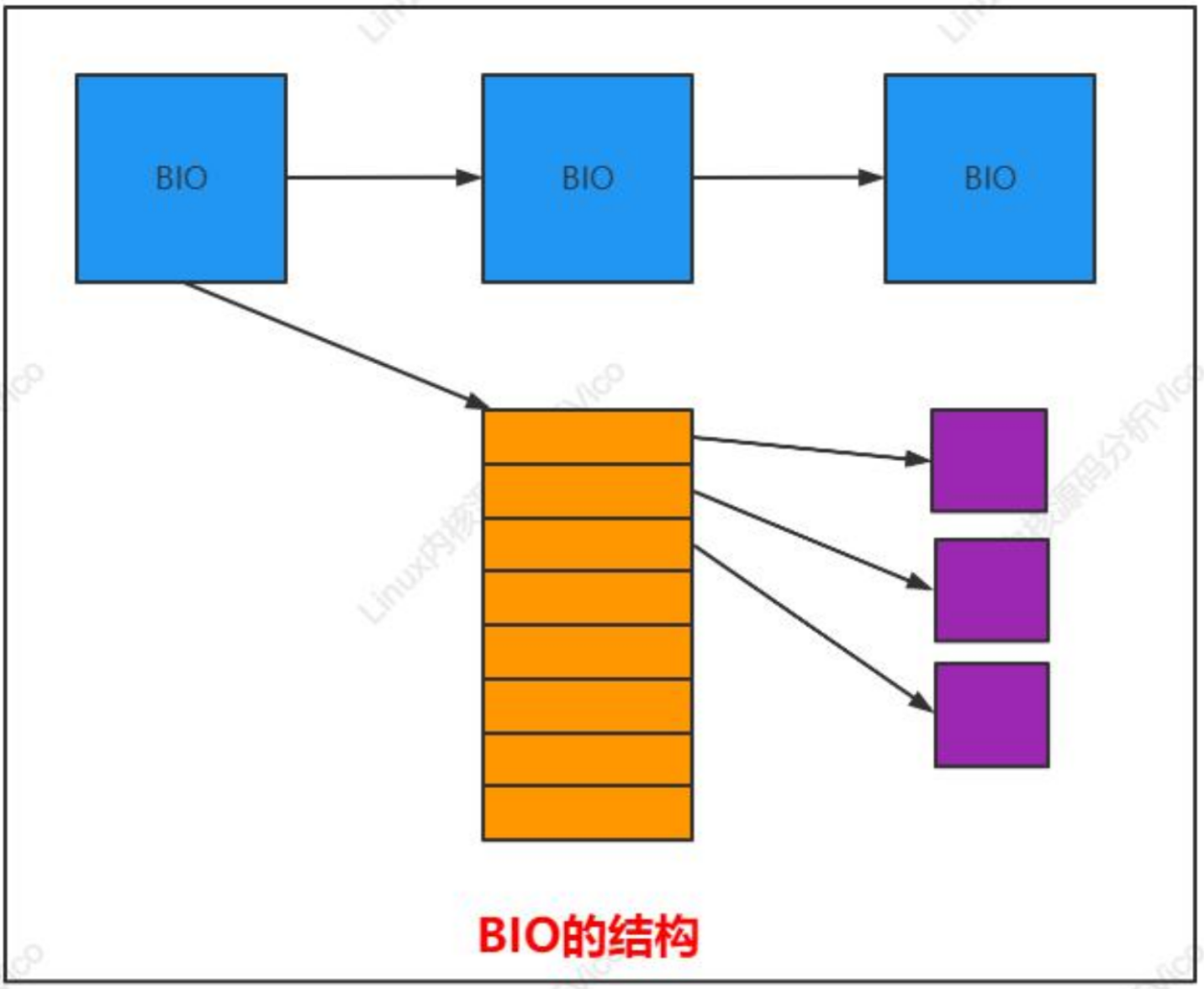
BIO 在內核源碼數據結構定義如下
各個數組元素的結構的定義:
bio_vec(
bio_page(指向用于數據傳輸的頁對應page實例)
bio_len(指向用于數據的字節數目)
bio_offset(頁內的偏移量)
)
內核采用的各種用于調度和重排 I/O 操作的算法,稱之為 I/O 調度器(對比通常的進程調度器,或網絡中控制通信數據量的數據包調度器)。通常,I/O 調度器也稱作電梯(elevator)。它們由下列數據結構中的一組函數表示: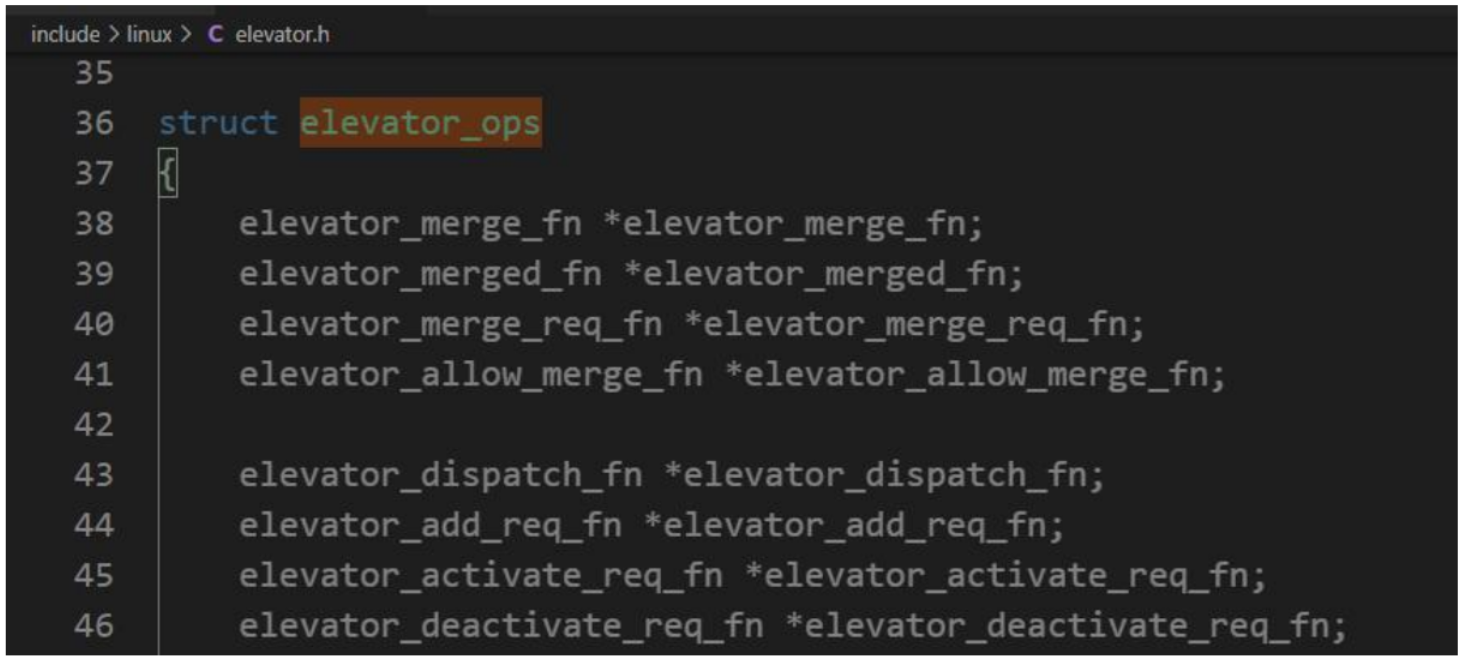
每個 I/O 調度器都封裝在下列數據結構中,其中還包含了供內核使用的其他信息:
內核將所有I/O調度器在一個標準的雙鏈表中維護,鏈表元素是list成員
系統總線上傳送的信息包括數據信息、地址信息、控制信息,因此,系統總線包含有三種不同功能的總 線 , 即數 據 總 線 DB ( Data Bus ) 、地 址 總 線 AB (Address Bus)和控制總線 CB(Control Bus)。
數據總線(Data Bus):將CPU的數據傳送到存儲器或IO接口等等部件,也可以將其他部件數據傳送到CPU。
地址總線(Address Bus):專門傳送地址的,由于地址只能從CPU傳向外部存儲器或IO端口,所以地址總線是單向三態的。比如:地址總線為n位,尋址空間為2的n次方個地址空間(存儲單元)。
控制總線(Control Bus):用來傳送控制信號和時序信號。
系統總線在微型計算機中的地位,如同人的神經中樞系統,CPU 通過系統總線對存儲器的內容進行讀寫,同樣通過總線,實現將 CPU 內數據寫入外設,或由外設讀入 CPU。微型計算機都采用總線結構。總線就是用來傳送信息的一組通信線。微型計算機通過系統總線將各部件連接到一起,實現了微型計算機內部各部件間的信息交換。
PCI(peripheral component interconnect)總線是當前最流行的總線之一,它是由 Intel 公司推出的一種局部總線。它定義了 32 位數據總線,且可擴展為 64 位。 PCI 總線主板插槽的體積比原 ISA 總線插槽還小,其功能比 VESA、ISA 有極大的改善,支持突發讀寫操作,最大傳輸速率可達 132MB/s,可同時支持多組外圍設備。PCI 局部總線不能兼容現有的 ISA、EISA、MCA(micro channel architecture)總線,但它不受制于處理器,是基于奔騰等新一代微處理器而發展的總線。
PCI 總線規定了以下設計目標:
PCI系統的布局(內核中PCI):
設備標識(系統某個PCI總線上每個設備。都由一組3個編號標識)
總線編號:設備所在總線的編號,0-255
插槽編號:總線內核的一個唯一標識編號。一個總線最多可附接32個設備。
功能編號:用于在一個擴展卡,實現包括多個擴展設備的設備(IDE控制器、USB控制器等等)。擴展設備必須通過功能編號來進行區分。PCI標準將一個設備上功能部件最大數目為8,每個設備都通過一個16位編號唯一標識(8位用于總線編號,5位用于插槽編號,3位用于功能編號)
PCI配置空間,PCI有三個相互獨立的物理地址(IO地址空間、配置空間、設備存儲器地址空間)
PCI總線規范配置空間總長度為256個字節。
PCI 配置空間布局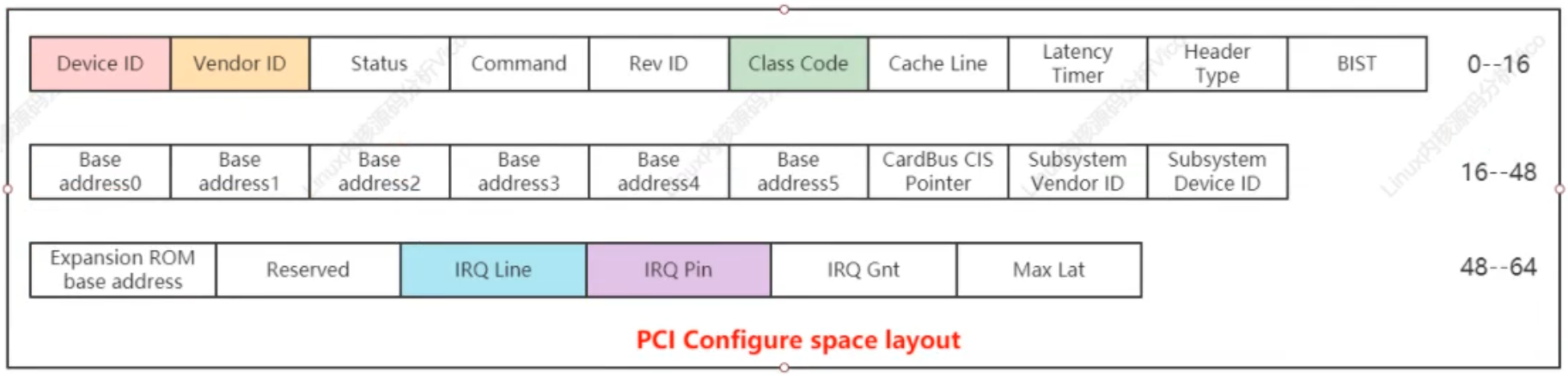
Device ID:設備ID
Vendor ID:廠商ID
Rev ID:用于區分不同設備修訂級別
Class Code:用于將設備分配到各種不同的功能組
基類及子類pci_ids.h中對應常數的名稱:
大容量的存儲器(PCI_BASE_CLASS_STOREAGE):SCSI、IDE、RAID
網絡(PCI_BASE_CLASS_NETWORK):以太網、FDDI
系統組件(PCI_BASE_CLASS_SYSTEM):實時時鐘、DMA控制器
PCI 總線數據結構
在內存中,每個 PCI 總線都通過 pci_bus 數據結構的一個實例表示,該結構定義如下: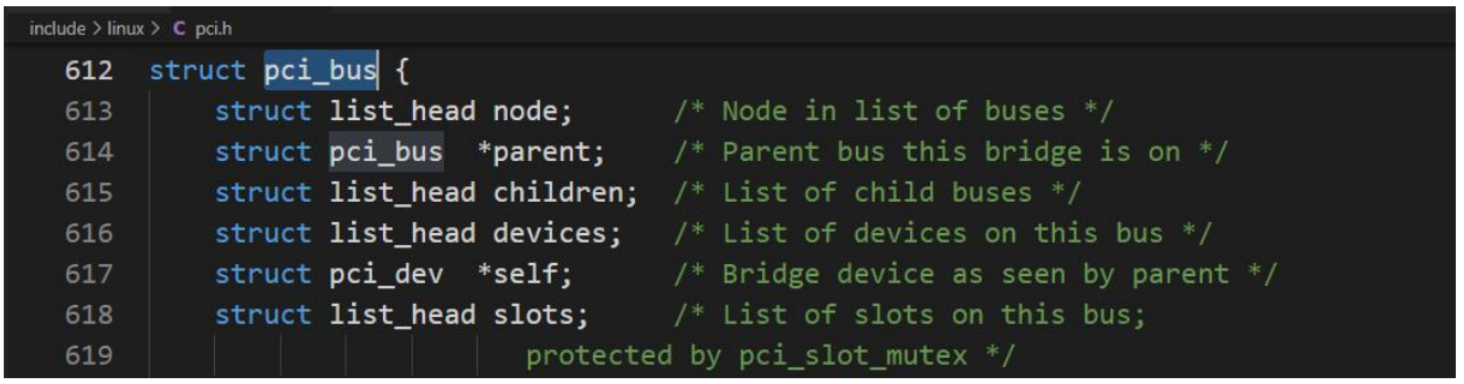
結構成員:系統中的各個總線由pci_bus的實例表示;
pci_dev結構表示各個設備、擴展卡和功能部件;
每個驅動程序都通過pci_driver的一實例描述。
struct pci_dev 是一個關鍵的數據結構,用于表示系統中的各個 PCI 設備。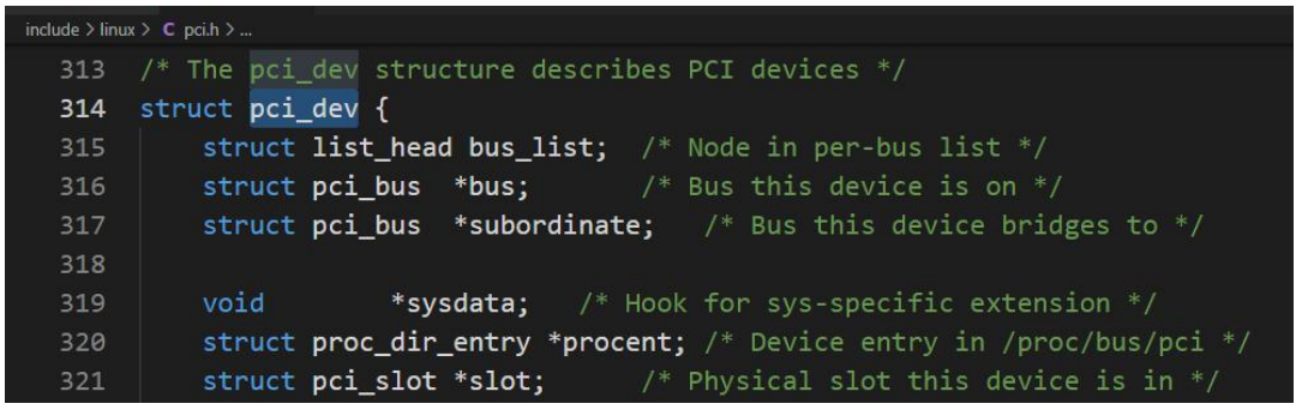
PCI 層中最后一個基本的數據結構是 pci_driver。它用于實現 PCI 驅動程序,表示了通用內核代碼和設備的底層硬件驅動程序之間的接口。每個 PCI 驅動程序都必須將其函數填到該接口中,使得內核能夠一致地控制可用的驅動程序。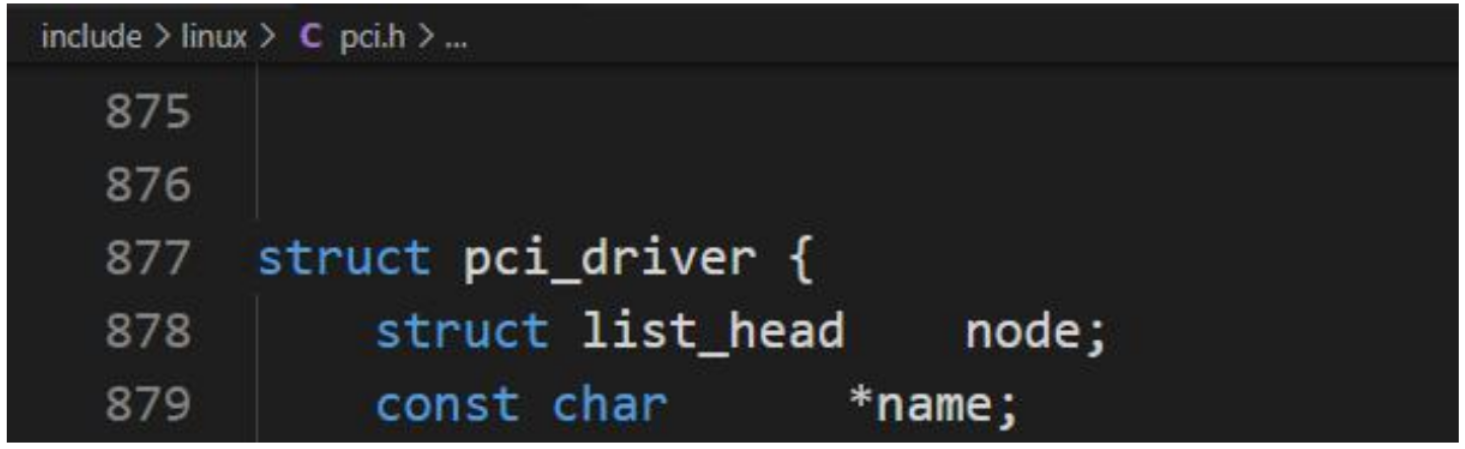
PCI 驅動程序可以通過 pci_register_driver 注冊。該函數十分簡單,其主要任務是,對相關函數已經分配的一個 pci_device 實例,填充一些剩余的字段。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态












