Vivado IP核之复数浮点数累加 Floating-point 快速实现多个数据相加
目录
前言
一、Floating-point IP核配置步骤
二、仿真
1.顶层代码
2.仿真代码
三、仿真结果分析
总结
在FPGA中,常常都会设计到浮点数的累加,单纯的两个两个的相加会占用大量的时钟周期,无意中发现xilinx提供的Floating-point IP核具有累加功能,那这就非常方便了,可以节约大量的时钟周期。上次在网上搜了半天也没搜到累加IP核的配置,所以我打算将该IP核实现累加的操作过程记录下来。
提示:以下是本篇文章正文内容,均为作者本人原创,写文章实属不易,希望各位在转载时附上本文链接。
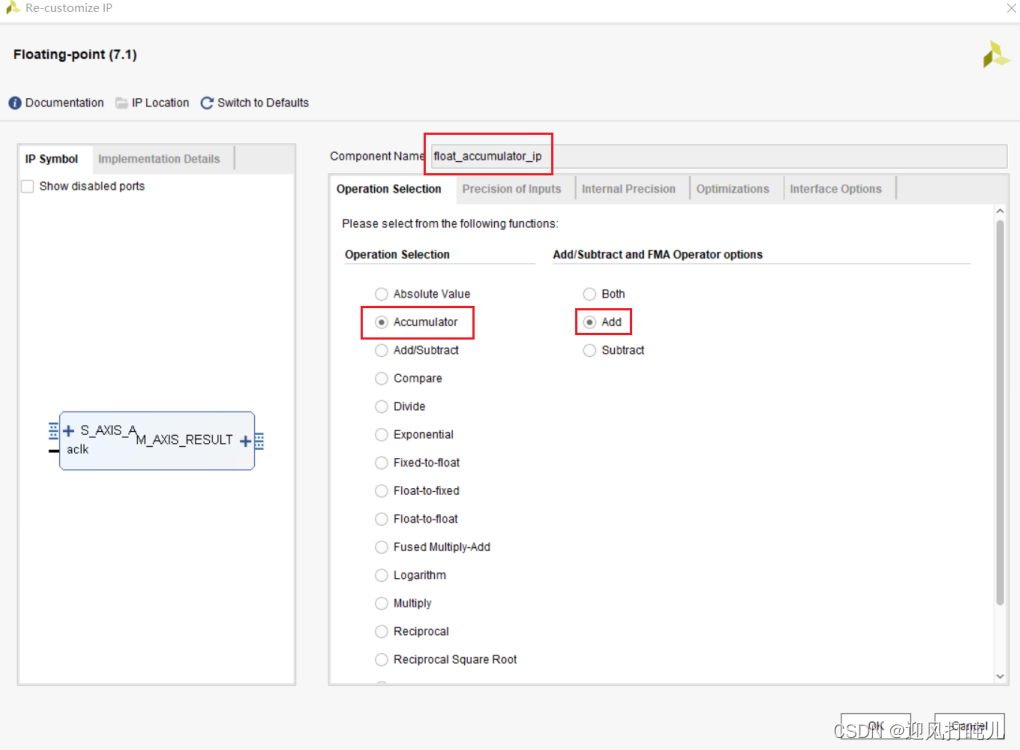
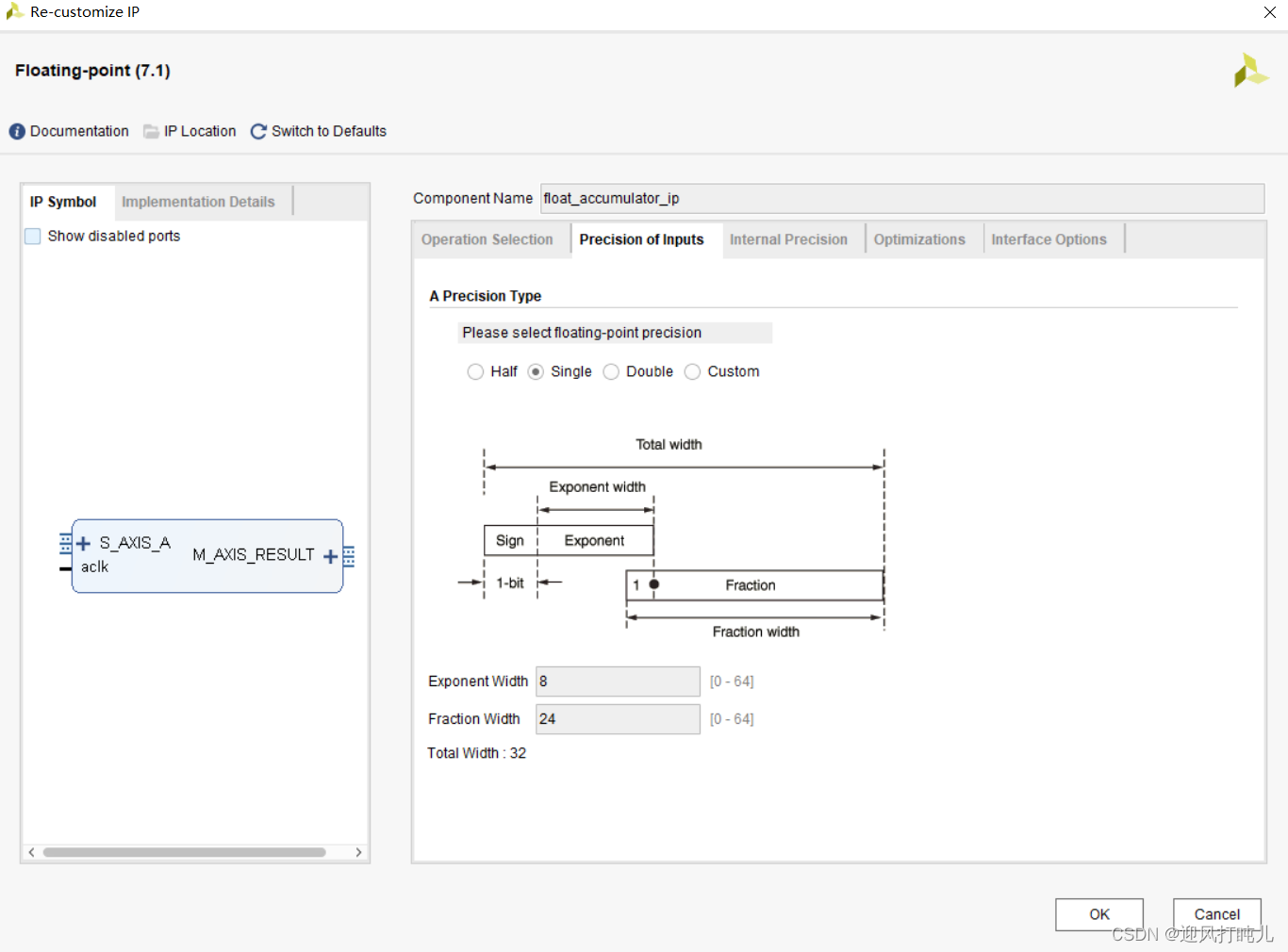
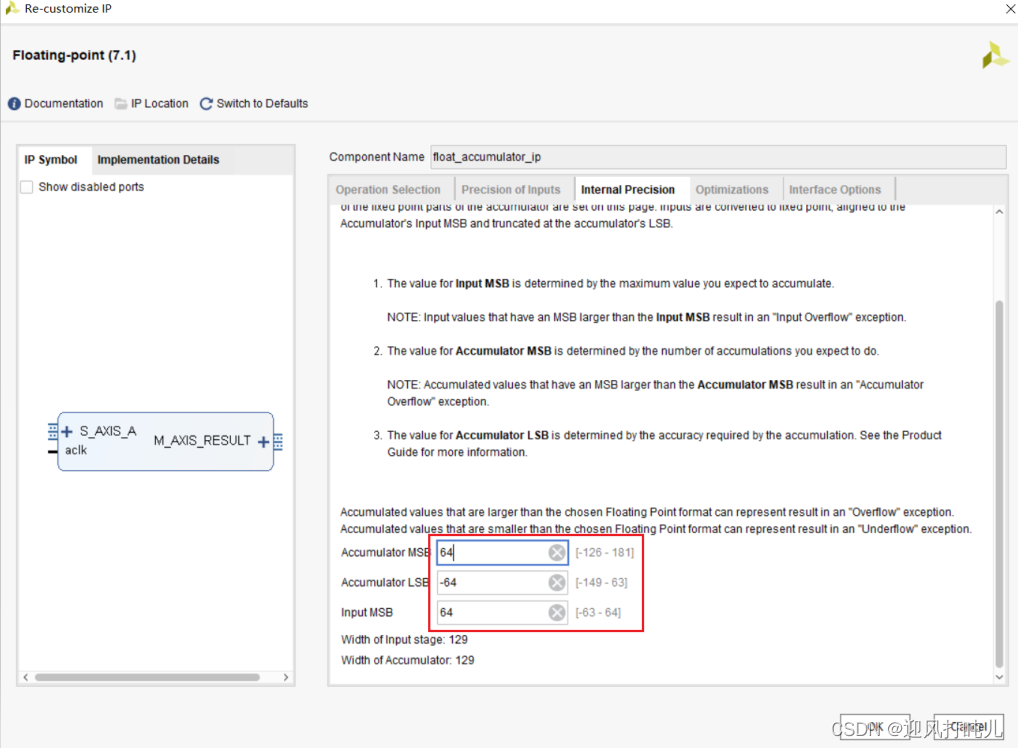

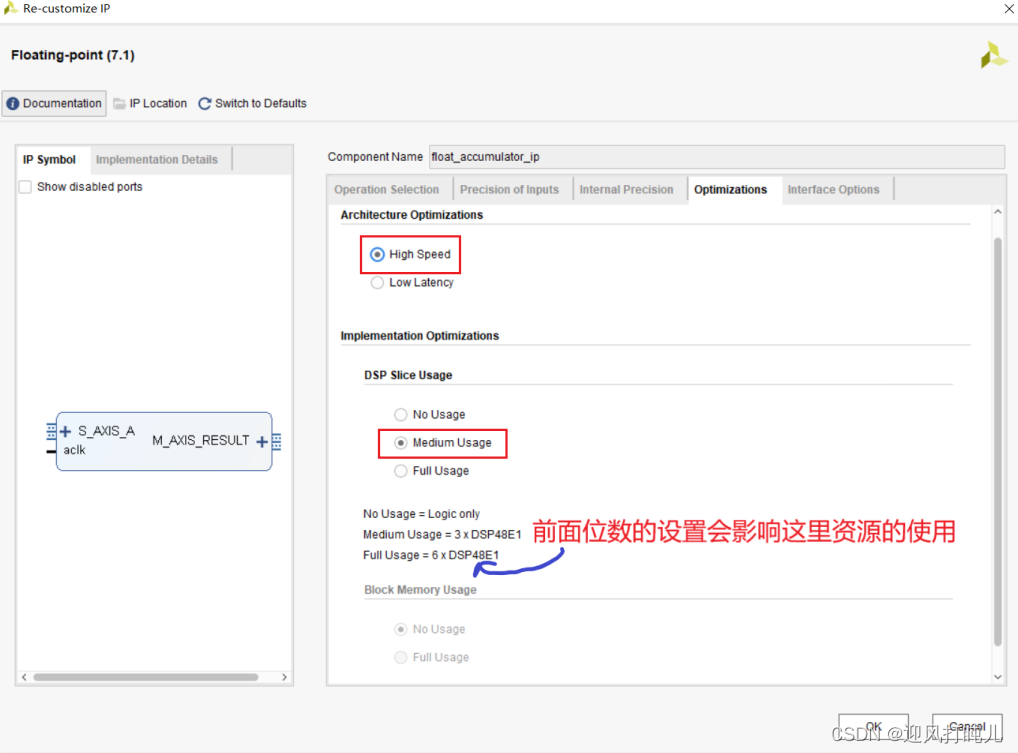
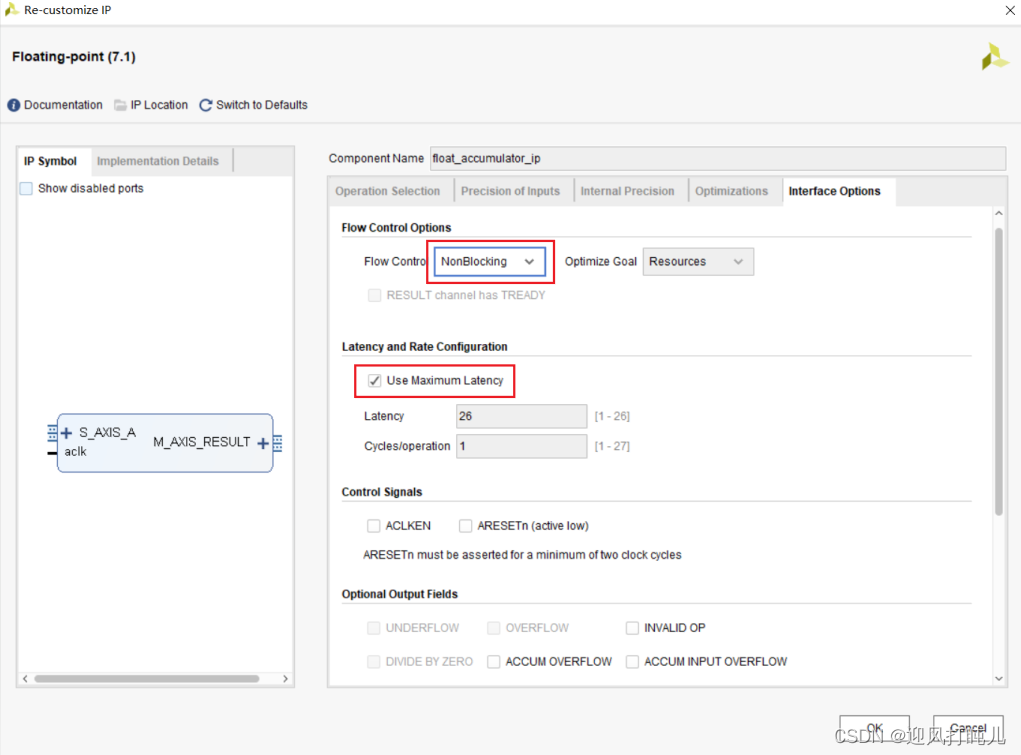
上面这张图片是对那几个位数配置的说明,之所以要配置他们,是因为这个IP核不是直接累加浮点数,而是先转为定点数累加完成后再转回浮点数。图片当中有说可以配置它推荐的位数累加,虽然有转为定点数这个过程,但跟用单精度浮点数累加一样。也就是位数达到一定的要求下,能完完全全保证精度。此处我没有将位数配置那么高,配置的太高要的DSP资源就很多。
代码如下:
`timescale 1ns / 1ps
//
// Company: cq university
// Engineer: clg
// Create Date: 2022/09/15 19:55:41
// Design Name:
// Module Name: complex_accumulator_ip
// Project Name:
// Target Devices:
// Tool Versions: 2017.4
// Description:
// Dependencies:
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//module complex_accumulator_ip(input clk ,input valid ,//执行加法有效信号input [ 31:0] re_a ,//复数a的实部input [ 31:0] im_a ,//复数a的虚部input last ,//累加最后一个数据标志信号output res_valid ,//结果有效信号output res_last ,//全部数据累加完标志信号output [ 31:0] re_res ,//运算结果实部output [ 31:0] im_res //运算结果虚部);float_accumulator_ip u1_float_accumulator_ip( //实部累加.aclk (clk ),.s_axis_a_tvalid (valid ),.s_axis_a_tdata (re_a ),.s_axis_a_tlast (last ),.m_axis_result_tvalid (res_valid ),.m_axis_result_tdata (re_res ),.m_axis_result_tlast (res_last )
);float_accumulator_ip u2_float_accumulator_ip( //虚部累加.aclk (clk ),.s_axis_a_tvalid (valid ),.s_axis_a_tdata (im_a ),.s_axis_a_tlast (last ),.m_axis_result_tvalid ( ),.m_axis_result_tdata (im_res ),.m_axis_result_tlast ( )
);endmodule
代码如下:
`timescale 1ns / 1ps
//
// Company: cq university
// Engineer: clg
// Create Date: 2022/09/15 19:56:43
// Design Name:
// Module Name: complex_accumulator_ip_tb
// Project Name:
// Target Devices:
// Tool Versions: 2017.4
// Description:
// Dependencies:
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//module complex_accumulator_ip_tb();
reg clk ;
reg valid ;
reg [ 31:0] re_a ;
reg [ 31:0] im_a ;
reg last ;
wire [ 31:0] re_res ;
wire [ 31:0] im_res ;
wire res_valid ;
wire res_last ;always #1 clk=!clk;
initial begin clk=0;valid=0;last=0;re_a=0;im_a=0;
#1 last=0;
#2 re_a=32'b00111111100000000000000000000000; //1im_a=32'b00111111100000000000000000000000; //1valid=1;
#2 re_a=32'b01000000000000000000000000000000; //2im_a=32'b01000000000000000000000000000000; //2
#2 re_a=32'b01000000010000000000000000000000; //3im_a=32'b01000000010000000000000000000000; //3last=1;
#2 last=0;valid=0;
//#3 valid=0;
endcomplex_accumulator_ip u1_complex_accumulator_ip(.clk (clk ),.last (last ),.valid (valid ),//执行加法有效信号.re_a (re_a ),//复数a的实部.im_a (im_a ),//复数a的虚部.re_res (re_res ),//运算结果实部.im_res (im_res ),//运算结果虚部.res_valid (res_valid ),.res_last (res_last )
);endmodule
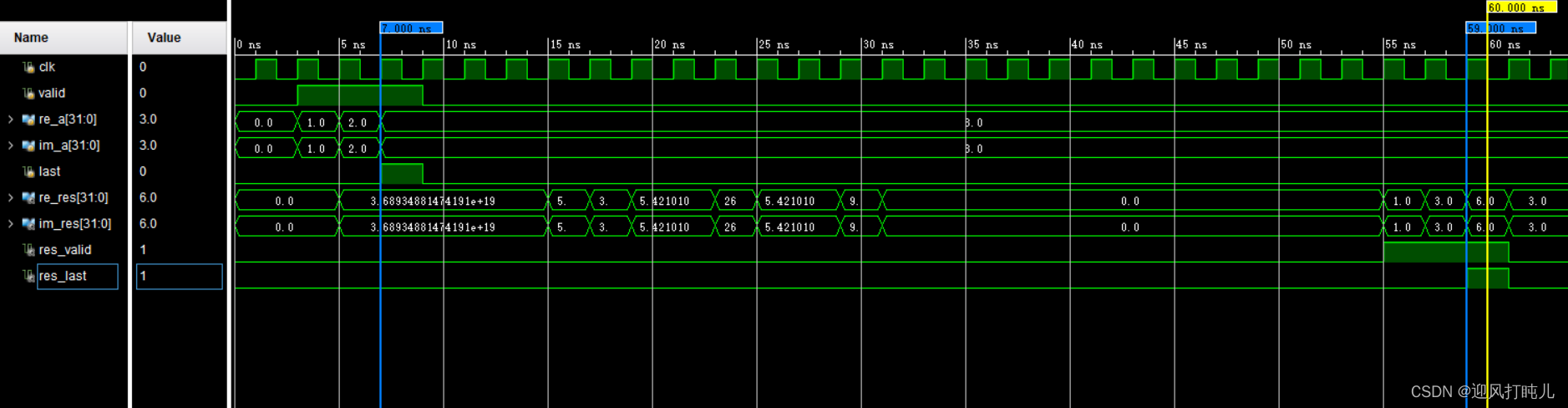
仿真结果如图所示,可知该模块成功实现了3个复数浮点数的累加,结果输出延时26个时钟周期,和前面IP核配置的延时一致。
以上就是今天要讲的内容,本文仅仅简单介绍了如何利用IP核快速实现复数浮点数累加的基本操作,大家如果想用它来完成更多的数据累加,自己则要修改代码或者理解操作后自己编写代码。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











